
Xen 3.0 虚拟化
编者按:本文自最初发布以来已更新。
虚拟化已经存在超过 40 年了。早在 20 世纪 60 年代,IBM 就已经在大型机上开发了虚拟化支持。从那时起,许多虚拟化项目已经可用于 UNIX/Linux 和其他操作系统,包括 VMware、FreeBSD Jail、coLinux、微软的 Virtual PC 以及 Solaris 的 Containers 和 Zones。
这些虚拟化解决方案的问题在于性能低下。Xen 项目,然而,提供了令人印象深刻的性能结果——接近原生性能——这是其关键优势之一。另一个令人印象深刻的特性是实时迁移,我在之前的一篇文章中讨论过。经过长时间的期待,Xen 3.0 版本最近发布了,它是本文的重点。
Xen 的主要目标是通过半虚拟化和虚拟设备来更好地利用计算机资源和服务器整合。在这里,我们讨论 Xen 3.0 如何实现这些想法。我们还研究了英特尔的新型 VT-x/VT-i 处理器,它们具有内置的虚拟化支持,以及它们与 Xen 的集成。
Xen 背后的思想是在高于 0 且权限较低的环中运行客户操作系统,而不是在环 0 中。在高于 0 的环中运行客户操作系统称为“环降权”。x86 上默认的 Xen 安装在环 1 中运行客户操作系统,称为处理器的当前特权级 1(或 CPL 1)。它在 CPL 0 中运行虚拟机监视器(VMM),即“hypervisor”。应用程序在环 4 中运行,无需任何修改。

IA-32 指令集包含大约 250 条指令,其中 17 条在环 1 中运行时存在问题。这些指令在两种意义上可能存在问题。首先,在环 1 中运行指令可能会导致一般保护异常(GPE),也可能称为一般保护错误(GPF)。例如,运行HLT会立即导致 GPF。某些指令,例如CLI和STI,如果满足特定条件,可能会导致 GPF。也就是说,如果 CPL 大于当前程序或过程的 IOPL,并且因此权限较低,则会发生 GPF。
第二个问题发生在不会导致 GPF 但仍然失败的指令上。许多 Xen 文章使用术语“静默失败”来描述这些情况。例如,恢复的 EFLAGS 处的 POPF 具有与当前 EFLAGS 不同的中断标志(IF)值。
Xen 如何处理这些有问题的指令?在某些情况下,例如 HLT 指令,环 1 中的指令(客户操作系统在此处运行)被 hypercall 替换。例如,考虑 sparse/arch/xen/i386/kernel/process.c 中的 cpu_idle() 方法。与最终在 Linux 内核中完成的操作不同,我们调用 xen_idle() 方法而不是调用 HLT 指令。它执行一个 hypercall,即 HYPERVISOR_sched_op(SCHEDOP_block, 0) hypercall。
hypercall 是 Xen 对 Linux 系统调用的模拟。系统调用是为了从用户空间(CPL3)移动到内核空间(CPL0)而调用的中断(0x80)。hypercall 也是一个中断(0x82)。它将控制权从环 1(客户域在此处运行)传递到环 0(Xen 在此处运行)。系统调用和 hypercall 的实现非常相似。两者都在 eax 寄存器中传递 syscall/hypercall 的编号。传递其他参数的方式相同。此外,系统调用表和 hypercall 表都在同一个文件 entry.S 中定义。
您可以通过构建 hypercall 数组将一些 hypercall 批量处理为一个 multicall。您可以使用 multicall_entry_t 结构来执行此操作。然后,您可以使用一个 hypercall,HYPERVISOR_multicall。这样,进出 hypervisor 的次数就减少了。当然,尽可能减少这种跨特权转换可以提高性能。例如,netback 虚拟驱动程序使用了这种 multicall 机制。
这是另一个示例:CLTS 指令清除 CR0 中的任务切换(TS)标志。但是,与 HLT 的情况一样,此指令在环 1 中发出时会导致 GPF。但是,CLTS 指令本身不会被某些 hypercall 替换。相反,它以下列方式委托给环 0。当它在环 1 中发出时,我们得到一个 GPF。但是,此 GPF 由 do_general_protection() 处理,该函数位于 xen/arch/x86/traps.c 中。但是请注意,do_general_protection() 是 hypervisor 处理程序,它在环 0 中运行。从那里,do_general_protection() 调用 do_fpu_taskswitch()。在某些情况下,此处理程序会扫描 CPU 中接收到的指令的操作码。在 CLTS 的情况下,操作码为 0x06,它调用 do_fpu_taskswitch(0)。最终,do_fpu_taskswitch(0) 调用 CLTS 指令,但这次是从环 0 调用的。注意:请确保 _VCPUF_fpu_dirtied 设置为启用此功能。
那些对更多细节感兴趣的人可以查看同一文件 xen/arch/x86/traps.c 中的 emulate_privileged_op() 方法。可能“静默失败”的指令通常会被其他指令替换。
拆分设备背后的思想是安全的硬件隔离。域 0 是唯一可以直接访问硬件设备的域,它使用原始的 Linux 驱动程序。但是域 0 还有另一层,即后端,其中包含 netback 和 blockback 虚拟驱动程序。(顺便说一句,对 usbback 的支持将在未来添加,Harry Butterworth 正在进行 USB 层的工作。)
同样,非特权域可以访问前端层,该层由 netfront 和 blockfront 虚拟驱动程序组成。非特权域以与将 I/O 请求发送到普通 Linux 内核相同的方式向前端发出 I/O 请求。但是,由于前端只是一个虚拟接口,无法访问真实硬件,因此这些请求被委托给后端。从那里,它们被发送到真实设备。
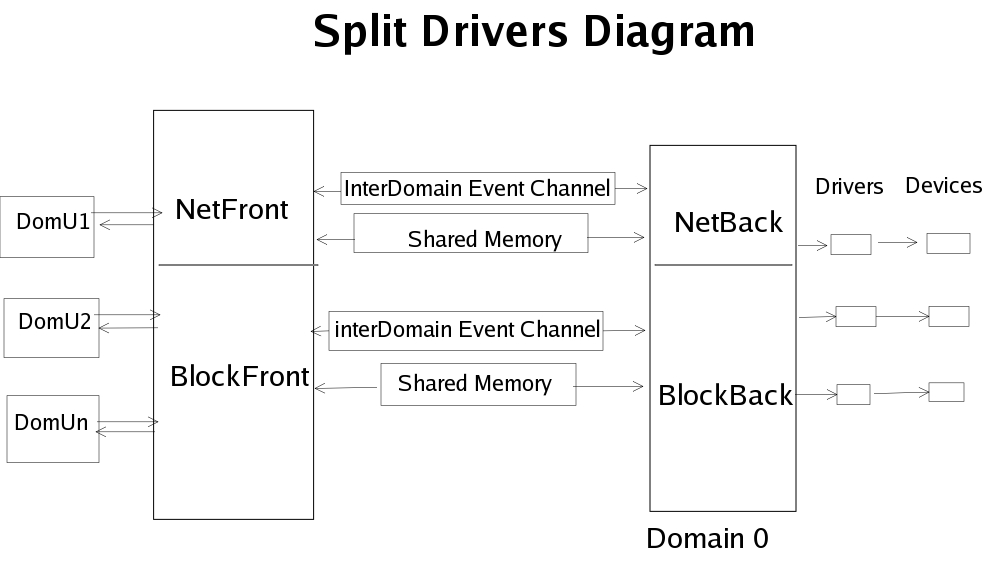
创建非特权域时,它会在自身和域 0 之间创建一个域间事件通道。这是通过 HYPERVISOR_event_channel_op hypercall 完成的,其中命令是EVTCHNOP_bind_interdomain。在网络虚拟驱动程序的情况下,事件通道由 sparse/drivers/xen/netback/interface.c 中的 netif_map() 创建。事件通道是一个轻量级通道,用于传递通知,例如说明何时完成 I/O 操作。
每个客户域和域 0 之间都存在一个共享内存区域。此共享内存用于传递请求和数据。共享内存是使用授权表 API 创建和处理的。
当控制器 APIC 断言中断时,我们到达 do_IRQ() 方法,该方法也可以在 Linux 内核(arch/x86/irq.c)中找到。hypervisor 仅处理定时器和串行中断。其他中断通过调用 __do_IRQ_guest() 传递给域。实际上,除了定时器和串行中断之外,所有中断都设置了 IRQ_GUEST 标志。
__do_IRQ_guest() 通过为在此 IRQ 上注册的所有客户调用 send_guest_pirq() 来发送中断。send_guest_pirq() 创建一个事件通道——evtchn 的一个实例——并通过调用 evtchn_set_pending() 设置此事件通道的 pending 标志。然后,Xen 异步通知此域中断,并对其进行适当处理。
英特尔目前正在开发用于 x86 和 Itanium 处理器的 VT-x 和 VT-i 技术,这将提供虚拟化扩展。对 VT-x/VT-i 扩展的支持是 Xen 3.0 官方代码的一部分;它可以在 xen/arch/x86/vmx*.c.、xen/include/asm-x86/vmx*.h 和 xen/arch/x86/x86_32/entry.S 中找到。
Xen 实现 VT-x/VT-i 中最重要的结构是 VMCS(代码中的 vmcs_struct),它代表 VMCS 区域。VMCS 区域包含六个逻辑区域;与我们的讨论最相关的是客户状态区域和主机状态区域。其他四个区域是 VM 执行控制字段、VM 退出控制字段、VM 进入控制字段和 VM 退出信息字段。
英特尔在 VT-x/VT-i 中添加了 10 个新操作码以支持英特尔虚拟化技术。让我们看一下代码中的新操作码及其包装器
VMCALL:(vmx.h 中的 VMCALL_OPCODE)这只是调用 VM 监视器,导致 VM 退出。
VMCLEAR:(vmx.h 中的 VMCLEAR_OPCODE)将 VMCS 数据复制到内存中,以防它被写入那里。包装器:vmx.h 中的 _vmpclear (u64 addr)。
VMLAUNCH:(vmx.h 中的 VMLAUNCH_OPCODE)启动虚拟机,并将 VMCS 的启动状态更改为已启动(如果它是清除状态)。
VMPTRLD:(vmx.h 中的 VMPTRLD_OPCODE)加载指向 VMCS 的指针。包装器:vmx.h 中的 _vmptrld (u64 addr)
VMPTRST:(vmx.h 中的 VMPTRST_OPCODE)存储指向 VMCS 的指针。包装器:vmx.h 中的 _vmptrst (u64 addr)。
VMREAD:(vmx.h 中的 VMREAD_OPCODE)从 VMCS 读取指定字段。包装器:vmx.h 中的 _vmread(x, ptr)
VMRESUME:(vmx.h 中的 VMRESUME_OPCODE)恢复虚拟机。为了恢复 VM,VMCS 的启动状态应为“清除”。
VMWRITE:(vmx.h 中的 VMWRITE_OPCODE)在 VMCS 中写入指定字段。包装器 _vmwrite (field, value)。
VMXOFF:(vmx.h 中的 VMXOFF_OPCODE)终止 VMX 操作。包装器:vmx.h 中的 _vmxoff (void)。
VMXON:(vmx.h 中的 VMXON_OPCODE)启动 VMX 操作。包装器:vmx.h 中的 _vmxon (u64 addr)。
使用此技术时,Xen 在 VMX 根操作模式下运行。客户域(未修改的操作系统)在 VMX 非根操作模式下运行。由于客户域在非根操作模式下运行,因此它们受到更多限制,这意味着某些操作会导致 VM 退出。
Xen 在 xen/arch/x86/vmx.c 的 start_vmx() 方法中进入 VMX 操作。此方法从 xen/arch/x86/cpu/intel.c 的 init_intel() 方法调用;应定义 CONFIG_VMX。
首先,我们检查 ecx 寄存器中的 X86_FEATURE_VMXE 位,以查看 cpuid 是否显示处理器中对 VMX 的支持。对于 IA-32,英特尔在 CR4 控制寄存器中添加了一个部分,用于指定我们是否要启用 VMX。因此,我们必须设置此位以通过调用 set_in_cr4(X86_CR4_VMXE) 在处理器上启用 VMX。它是 CR4 中的位 13 (VMXE)。
然后我们调用 _vmxon 来启动 VMX 操作。如果我们尝试在 CR4 中的 VMXE 位未设置的情况下使用 _vmxon 启动 VMX 操作,我们会得到一个 #UD 异常,告诉我们我们有一个未定义的操作码。
某些指令可能会无条件地导致 VM 退出,而某些指令可能会导致 VM 退出某些 VM 执行控制字段。(请参阅上面关于 VMX 区域的讨论。)以下指令无条件地导致 VM 退出:CPUID、INVD、从 CR3 的 MOV、RDMSR、WRMSR 以及上面列出的所有新的 VT-x 指令。其他指令,例如 HLT、INVPLG(使 TLB 条目指令无效)、MWAIT 等,如果设置了相应的 VM 执行控制,则会导致 VM 退出。
除了 VM 执行控制字段之外,还使用了两个位图来确定是否执行 VM 退出。第一个是异常位图(请参阅 xen/include/asm-x86/vmx_vmcs.h 中 vmcs_field 枚举中的 EXCEPTION_BITMAP),它是一个 32 位字段。当在此位图中设置一位时,如果发生相应的异常,则会导致 VM 退出。默认情况下,设置的条目是 EXCEPTION_BITMAP_PG(用于页错误)和 EXCEPTION_BITMAP_GP(用于一般保护)(请参阅 vmx.h 中的 MONITOR_DEFAULT_EXCEPTION_BITMAP)。
第二个位图是 I/O 位图。实际上,有两个 4KB I/O 位图,A 和 B,它们控制各种端口上的 I/O 指令。I/O 位图 A 包含 0000-7FFF 范围内的端口,I/O 位图 B 包含 8000-FFFF 范围内的端口。(请参阅 vmcs_field 枚举中的 IO_BITMAP_A 和 IO_BITMAP_B。)
当发生 VM 退出时,我们会发送到 vmx.c 中的 vmx_vmexit_handler()。我们根据提供的退出原因处理 VM 退出,我们可以在 VMCS 区域中看到该原因。有 43 个基本退出原因;您可以在 vmx.h 中找到其中一些。字段以 EXIT_REASON_ 开头,例如 EXIT_REASON_EXCEPTION_NMI(这是退出原因 0)等等。
使用 VT-x/VT-i 时,客户操作系统无法在实模式下工作。这就是我们使用特殊的加载程序 vmxloader 加载客户的原因。vmxloader 在 0xF0000 加载 ROMBIOS,在 0xC0000 加载 VGABIOS,然后在 D000:0000 加载 VMXAssist。VMXAssist 是实模式的模拟器,它使用 IA32 的虚拟 8086 模式。在设置虚拟 8086 模式后,vmxloader 在 16 位环境中执行。
但是,某些指令在虚拟 8086 模式下无法识别,例如 LIRT(加载中断寄存器表)和 LGDT(加载全局描述符表)。当尝试在保护模式下运行这些指令时,它们会产生 #GP(0) 错误。VMXAssist 检查正在执行的指令的操作码并处理它们,以使其不会导致 GPF。
VT-x/VT-i 和 AMD 的 SVM 架构有很多共同之处,这是开发其通用接口层硬件虚拟机(HVM)的动机。HVM 层的代码由 IBM 沃森研究中心的 Leendert van Doorn 编写,它位于 Xen 存储库中的单独分支中。
VT-x/VT-i 和 AMD SVM 的通用接口的一个示例是域构建器 xc_hvm_build(),它位于 xc_hvm_build.c 中。由于加载程序现在对两种架构都是通用的,因此 vmxloader 现在称为 hvmloader。hvmloader 仅通过调用其 CPUID 来识别处理器;请参阅 tools/firmware/hvmloader/hvmloader.c。
AMD SVM 具有分页实模式,它虚拟化了保护模式内部的实模式。因此,在 AMD SVM 的情况下,我们应该仅将操作设置为实模式 SVM_VMMCALL_RESET_TO_REALMODE。在 VT-x/VT-i 的情况下,我们应该使用 VMXAssist,如上所述。
HVM 定义了一个名为 hvm_function_table 的表,它是一个包含 VT-x/VT-i 和 AMD SVM 共有的函数的结构。这些方法,包括 initialize_guest_resources() 和 store_cpu_guest_regs(),在 VT-x/VT-i 和 AMD SVM 中的实现方式不同。
Xen 3.0 还包括对 AMD SVM 处理器的支持。SVM 的优势之一是标记的 TLB:客户被映射到与 VMM 设置的地址空间不同的地址空间。TLB 使用地址空间标识符(ASID)进行标记,因此当发生上下文切换时,不会发生 TLB 刷新。
实时迁移是 Xen 的一个令人着迷的功能,可以用作负载平衡和维护的解决方案。使用实时迁移时的停机时间非常低——数十毫秒。Xen 中实时迁移的实现由域 0 管理。
实时迁移分为两个阶段。第一阶段是“预复制”,其中在迁移域继续运行时,物理内存通过 TCP 复制到目标。在一些迭代之后,在此期间仅复制自上次迭代以来被弄脏的页面,迁移域停止运行。然后,在第二阶段,复制剩余的页面,域在目标计算机上恢复其工作。
此外,来自丹麦哥本哈根大学的 Jacob Gorm Hansen 正在进行一些关于“自迁移”的有趣工作。在自迁移中,正在迁移的非特权域自身处理迁移。虽然具有此能力有一些好处,例如安全性,但自迁移比实时迁移更复杂。例如,包含管理迁移的代码的内存页在传输过程中会被弄脏。
在未来,似乎英特尔的所有新型 64 位处理器都将具有虚拟化扩展支持,而 Xen 似乎主要采用具有虚拟化支持的 CPU。目前,Xen 在官方树中支持 VT-x 和 VT-i,并且存储库中的一个分支支持 AMD SVM。
总的来说,Xen 是一个有趣的虚拟化项目,具有许多特性和优势。并且,Xen 有机会在未来某个时候集成到官方 Linux 内核树中,就像 UML 和 LVS 一样。
Rami Rosen 是以色列理工学院 Technion 的计算机科学毕业生,该学院位于海法。他为一家网络初创公司担任 Linux 内核程序员,可以通过 ramirose@gmail.com 与他联系。在业余时间,他喜欢跑步、解决隐秘难题,并帮助他认识的每个人迁移到这个出色的操作系统 Linux。
