
集群并非高深学问
设计和开发超音速燃烧冲压发动机(scramjets)所涉及的火箭科学是一项棘手的业务。高性能 Linux 集群用于辅助研究超燃冲压发动机,通过促进对通过超燃冲压发动机的气流进行详细计算。这种计算需求以及其他实际问题超出了办公桌下几台 PC 的能力。在 Linux 集群时代之前,研究人员常常不得不缩小问题规模或简化正在研究的机制,从而损害解决方案的准确性。现在,例如,可以以相当高的分辨率研究整个超燃冲压发动机。
在本文中,我们尝试达到两个目的:我们描述了我们作为一个研究小组运营大型集群的经验,并演示了 Linux 和配套软件如何在不需要专业 HPC 知识的情况下实现这一点。随着 HPC Linux 集群的成熟,它已成为火箭科学的辅助工具,而无需本身成为火箭科学。
最后这句话可能需要一些澄清。当集群首次构建时,它们因提供无与伦比的性价比或“物有所值”而闻名。然而,当您尝试扩展到大量节点时,大型集群的运行开始变得相当复杂。由于多种原因,包括缺乏集群软件工具,大型集群需要一名专职系统管理员。我们认为,由于为 Linux 编写的旨在集群操作和管理的简单有效工具,这种情况现在已经改变。
2004 年 6 月,昆士兰大学的两个研究小组,超音速中心和计算分子科学中心,联手从 Sun Microsystems 购买了一个由 66 个双 Opteron 节点组成的集群。Sun 公司慷慨地赞助了该机器三分之二的成本。昆士兰智能州研究设施基金的拨款支付了机器成本的剩余三分之一。此外,昆士兰大学还提供了基础设施,例如空调和专门设计的机房。我们突然面临着运营一个 66 节点集群的挑战,尽管这是一个令人愉快的挑战,它比我们以前的五个或六个台式机的集群大了一个数量级。我们没有资源获得昂贵的专有集群控制套件,也没有大型集群管理方面的经验或专业知识。然而,我们高度意识到 Linux 在成本、可扩展性、灵活性和可靠性方面的优势。
我们强调,我们最终建立的设置是一个简单但有效的 Linux 集群,它使该小组能够继续进行研究工作。在下文中,我们将讨论我们作为一个研究小组扩展到大型集群时面临的挑战,以及我们如何利用开源解决方案来发挥我们的优势。我们所做的工作只是集群操作的一种解决方案,但我们认为这是一种为研究小组提供灵活性且易于实施的解决方案。我们应该指出,对于我们有限的预算而言,配备所有花哨功能的昂贵集群控制套件并不是我们的选择。此外,在最初部署时,开源 Rocks 集群工具包尚未为我们的 64 位 Opteron 硬件做好准备,因此我们需要找到一种使用最新的 64 位就绪内核的方法。打包集群部署工具包的吸引力在于它们隐藏了一些幕后细节。缺点可能是集群构建器被锁定在非常特定的集群使用和管理方式中,并且当出现问题时很难诊断问题。在设置我们的集群时,我们坚持 UNIX 的“简单工具协同工作”的格言,这为我们提供了一个高度可配置、易于维护且操作透明的设置。
在构建由五个节点组成的集群时,我们的 IT 管理员给了我们网络上的五个 IP 地址。这很简单——我们的机器有一个 IP,我们将安全和防火墙的细节留给了我们的网络管理员。现在有 66 个节点加上前端文件服务器和另外 66 个服务处理器,每个都需要一个 IP 地址,很明显我们将不得不使用私有网络。基本上,我们的 IT 管理员不想认识我们,并且含糊地嘟囔着关于我们尝试网络地址转换 (NAT) 防火墙的事情。所以这就是我们所做的;我们抓起一台旧 PC 并安装了 Firestarter,并在大约半小时内为我们的集群创建了一个防火墙。Firestarter 为 Linux 的 iptables 提供了直观的界面。我们创建了我们的 NAT 防火墙,并且能够将一些端口转发到前端,从而允许 SSH 访问。
在网络拓扑结构整理好后,下一个挑战是在所有 66 台服务器上安装操作系统。以前,我们很乐意花一个上午的时间在驱动器中换入换出 CD,以便在少数几台机器上安装操作系统。我们很快意识到我们将需要某种自动化流程来处理 66 个节点。我们发现 SystemImager 软件包完全符合我们的要求。使用 SystemImager 软件包,我们只需要在一个节点上安装操作系统。在摆弄了该节点的配置后,我们有了我们的黄金客户端,正如他们在 SystemImager 术语中所说的那样,准备就绪。SystemImager 工具允许我们获取映像并在需要时推送映像。我们还需要一种通过网络执行操作系统安装的机制,以便我们可以避免 CD 交换。SystemImager 脚本之一帮助我们设置了预启动执行环境 (PXE) 服务器。此执行环境在启动期间分发给节点,并允许节点继续进行网络安装。在这种最小的环境下,节点对其磁盘进行分区,然后从前端服务器传输组成操作系统的文件。对于记录,我们在集群上使用 Fedora Core 3。选择它的动机是我们自己熟悉该发行版,并且它足够接近 Red Hat Enterprise Linux,以至于我们能够运行安装在集群上的少数商业科学应用程序。
由于我们对大规模并行计算感兴趣,我们需要配置服务器以相互通信。我们安装了 lam-mpi 以用作消息传递接口,并且我们配置了每个节点上的 SSH 服务,以通过使用基于主机的身份验证来允许节点之间进行无密码访问。请注意,lam-mpi 并没有完成并行化应用程序的所有工作;您仍然需要编写或拥有可用的 MPI 感知代码。
我们配置了一个 NFS(网络文件系统)服务器,为所有集群计算节点提供共享文件系统。我们在所有节点上共享用户的主目录以及我们用于科学计算的一些专业应用程序。用户帐户由网络信息服务 (NIS) 管理,NIS 是大多数 Linux 发行版的标准配置。
以前,我们的计算小组大约有四个人共享五台节点上的时间。我们有一个非常可靠的作业调度系统,其中涉及一块白板和一些记号笔。显然,随着我们将用户群扩展到大约 40 个用户,这种作业调度方法将无法扩展。我们选择安装在集群上的 Sun Grid Engine 调度和批处理软件。
用户群扩大带来的另一个挑战是,大多数用户在使用 HPC 设施方面的经验有限,并且几乎没有或根本没有使用 Linux 的经验。我们认为,分享有关使用集群信息的最佳方法之一是使用 wiki 页面。我们使用 MediaWiki 软件包设置了一个 wiki 页面。wiki 页面包含有关集群的各种信息——从关于将文件复制到集群的基本新手类型信息到关于各种编译器的高级用法信息。wiki 页面在弥合系统管理员和新手用户之间的知识差距方面非常有用。wiki 允许没有经验的集群用户修改文档,使其对其他新玩家更简单,并添加他们自己可能设计的巧妙技巧。wiki 页面的动态特性在保持集群设施文档更新方面具有明显的优势。
wiki 的第二个目的是维护管理员在集群上工作的日志。由于我们位于不同的建筑物中,因此保留传统的(物理)日志簿是不切实际的。相反,我们使用 wiki 页面来让彼此了解集群的变化。我们实际上对网页的这一部分进行了密码保护,以防止任何 wiki 破坏。
有时需要在集群的每个节点上发出命令或将一些文件复制到所有节点上。同样,对于五台或六台机器来说,这不是问题——我们只需单独登录到机器并执行任何必要的操作即可。但是对于 66 台机器,单独登录到每台机器变得既繁琐又容易出错。我们这里的解决方案是使用橡树岭国家实验室小组开发的 C3 软件包。C3 代表集群命令和控制。它提供了一组 Python 脚本,允许跨集群远程执行命令。还有一个工具允许将文件复制到计算节点组。这是一个 Python 脚本,它使用 rsync 来执行传输。
说到 Python 脚本,我们发现 Python 是一种用于集群工作的有用的通用脚本语言。Python 特别吸引人的地方在于它对字符串操作的复杂支持。这使我们能够获取来自多个独立程序的基于文本的输出,并将其解析为更有意义的信息。例如,排队系统提供了一些关于集群状态的详细信息,例如每个节点上的可用处理器和每个节点上的队列可用性。使用 Python,我们可以从这样的命令中获取详细的输出,并提供一些摘要统计信息,让我们一目了然地了解集群负载。Python 脚本在运行中的另一个例子是我们对计算节点上温度的监控。此脚本显示在清单 1 中。Python 的字符串处理的简易性和对系统服务的访问在集群上的许多脚本编写任务中都派上用场。
清单 1. 使用 Python 脚本进行温度监控
---- monitor_temp.py ----
SHUTOFF_TEMP = 50.0
mail_list = ['fake.email@fakedomain.com']
import os, re, smtplib
def send_mail(toaddrs, msg):
fromaddr = 'sysadmin@fakedomain.com'
server = smtplib.SMTP('smtp.uq.edu.au')
server.sendmail(fromaddr, toaddrs, msg)
server.quit()
f = os.popen('hostname', "r")
hostname = f.readline().split()[0]
svc_proc = hostname[:4] + 'sp' + hostname[4:]
f.close()
f = os.popen("ipmitool -I lan -P password -H %s sensor | grep
'cpu[0-1].memtemp'" % svc_proc, "r")
mail_sent = False
for line in f.readlines():
if mail_sent:
break
tokens = line.split()
str = tokens[2]
if str == 'NA':
temp = 1.0
else:
temp = float(str)
if temp >= SHUTOFF_TEMP:
msg = 'Re: hot temperature initiated shutdown for %s\n' %
hostname
msg += 'The CPU memtemp for %s exceeded %.1f.\n' % (hostname,
SHUTOFF_TEMP)
msg += 'This node has been shutdown.\n'
for address in mail_list:
send_mail(address, msg)
# Clean up scratch and power down
os.system('rm -rf /scratch/*')
os.system('/sbin/shutdown now -h')
mail_sent = True
温度监控脚本利用智能平台管理接口 (IPMI)。通过使用 IPMI 规范,我们实现了监控子系统,该子系统允许对计算节点进行完全远程和可定制的管理。每个计算节点都配备了一个 PowerPC 服务处理器,该处理器在与主集群分离的网络上进行通信。通过结合 Python 和 IPMItool 的开源工具的强大功能,我们创建了一个完全自主的热监控系统。如果单个计算节点超过预定温度或服务器未响应关机命令,则系统可以关闭单个计算节点或切断电源。还会使用 Python smtplib 发送电子邮件给管理员团队,告知情况。
在我们收到第一批 66 个节点大约 12 个月后,由于昆士兰大学的资助,我们有机会购买另外 60 个双 Opteron 节点。应用刚刚描述的相同工具和技术,我们能够在最短的时间和精力内将额外的 60 个节点集成到我们的集群中。随着我们扩展计算资源,我们面临的主要技术难题是文件服务器上的额外负载。众所周知,Linux 捆绑的当前 NFS 版本 (v3) 无法很好地随着节点数量的增加而扩展。我们通过使用两个文件服务器来分担负载来规避这种情况。理想的情况是投资于专用存储区域网络 (SAN)。对于 66 个节点来说,这有点过分了,而且由于大学环境中研究资金的反复无常,我们永远无法预测我们是否有钱购买额外的 60 个节点。
尽管集群设置涉及更多细节,例如使用 NTP 在集群中设置公共时间,但刚刚描述的工具集合构成了集群操作和管理的基础。这为研究留出了时间,并有机会将集群用于一些有趣的科学和工程。
在昆士兰大学超音速中心,有两个主要研究领域:行星进入飞行器和超燃冲压发动机。行星进入飞行器在进入大气层期间会经历巨大的热负荷,这是航空航天工程师的主要设计考虑因素。使用集群,我们可以对典型航天器周围的高温气体流进行大规模并行计算。到目前为止,我们已经研究了航天器重返地球、进入火星和土星最大的卫星土卫六。除了对真实航天器配置进行计算外,我们还研究了球体和圆柱体等简化的几何形状,以便更好地了解这些高温下的基本流动物理学。
超音速中心的另一个主要研究重点是超燃冲压发动机的研究、设计和优化。当以比协和飞机快许多倍的速度飞行时,超燃冲压发动机会受到大量空气动力阻力的影响。所经历的阻力在确定这些发动机的性能能力方面起着主导作用。集群允许非常详细地检查诸如近壁氢气燃烧等减阻理论。使用复杂的三维湍流模型,我们可以研究控制阻力大小的非常精细的流动尺度。
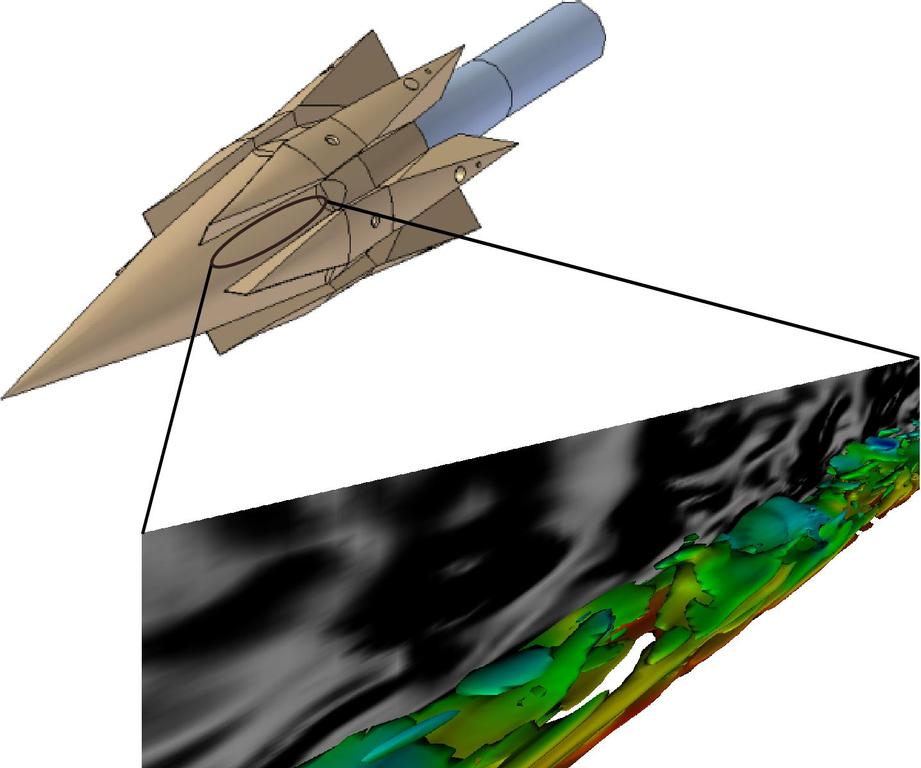
图 1. 湍流计算
图 1 显示了超燃冲压发动机燃烧室内部计算结果的示例。彩色轮廓表示涡度,这是混合的指示,阴影图案显示流动密度变化。
计算分子科学中心 (CCMS) 从事分子尺度计算所涉及领域的跨学科研究。研究领域多种多样,包括电子结构、量子和分子动力学、计算纳米技术和生物分子建模研究。当前的项目包括对珊瑚礁中发现的红色荧光蛋白进行计算建模,该蛋白在深层组织生物医学成像中具有应用。另一个项目正在研究未来燃料电池技术中的储氢材料。
量子和分子动力学小组对气相反应的详细动力学和机制进行研究。这些仅涉及少量原子的反应通常在大气或燃烧循环中起关键作用。详细的量子级计算本质上是并行的,并且串行执行是不切实际的,因为内存需求远远超过普通桌面电脑。当前感兴趣的是氢气与分子氧气的反应研究。它是碳氢燃料燃烧中最重要的反应之一。
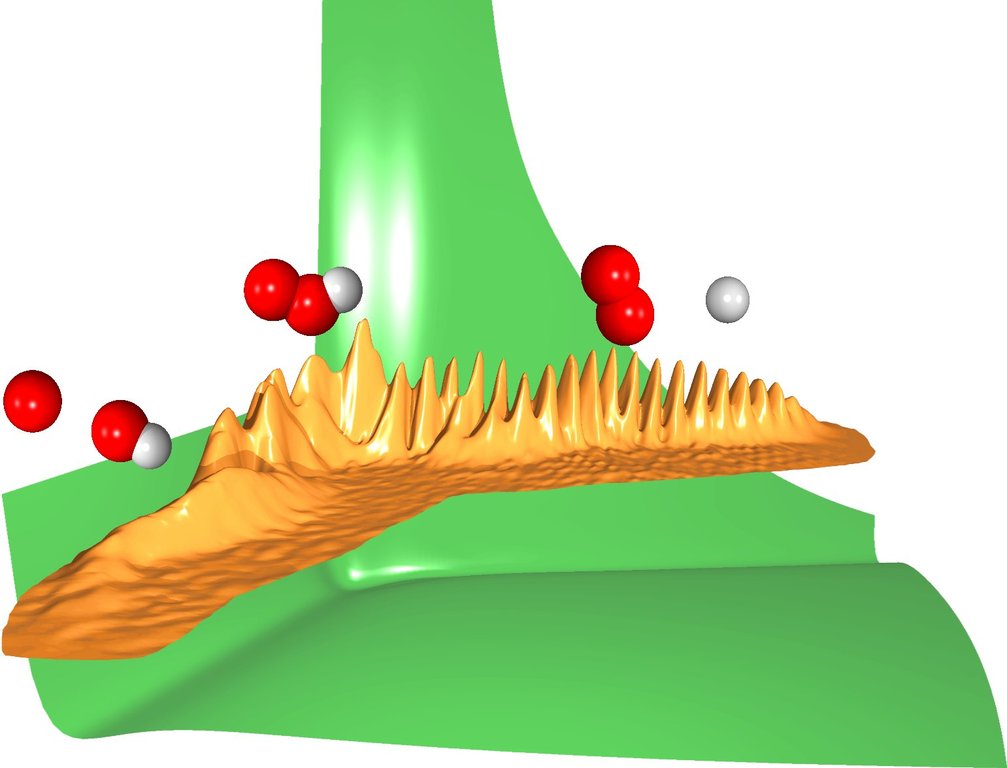
图 2. 量子动力学碰撞
图 2 提供了氢原子和氧分子量子动力学碰撞的图形表示。该图显示了 HOO 系统的波函数和势能。从右到左:氢原子接近氧分子,形成 HOO 复合物(在势能表面可以看到一个深势阱),复合物分解,形成产物 O 和 OH(羟基自由基)。
在本文中,我们概述了昆士兰大学的 Opteron 集群设置。我们描述了几个系统管理员每周只需花费几个小时查看集群,即可有效地管理大型集群计算。集群部署的成功部分归功于可用于集群操作的高质量开源 Linux 工具,例如 SystemImager 映像套件和用于远程命令执行的 C3 软件包。我们认为,与集群部署工具包相比,使用这些简单工具具有显着优势。这些优势是高度可配置且易于升级的系统。我们的集群非常可靠,最大的停机时间来源是昆士兰夏季典型的风暴造成的电力中断。
至于未来,我们可能正在接近需要认真考虑使用某种类型的并行文件系统的时候了。到目前为止,我们的 NFS 文件服务器一直很幸运,但我们不得不教育我们的用户关于文件暂存,并要求他们稍微尊重文件服务器。但就目前而言,一切系统都在运行。
本文的资源: /article/9133。
Rowan Gollan 是澳大利亚昆士兰大学超音速中心的博士生。当不研究行星进入飞行器周围的辐射流时,他的职责包括兼职监督集群和一些部门 Linux 服务器。
Andrew Denman 也是超音速中心的博士生。Andrew 的博士学位是关于湍流可压缩流的计算。他也是集群上所有事件的最终权威。
Marlies Hankel 是计算分子科学中心的博士后研究员。Marlies 代表计算科学家的利益,并防止他们受到工程师的欺负。Marlies 当前的研究重点是与燃烧和大气化学相关的反应散射过程的量子动力学。




