
主流并行编程
当唐纳德·贝克尔在 20 世纪 90 年代初在 NASA 工作时提出了 Beowulf 集群的想法时,他永远改变了高性能计算的面貌。机构不必再花费数百万美元购买最新的超级计算机,现在他们可以花费数十万美元就能获得相同的性能。事实上,快速浏览一下 TOP500 项目的世界最快超级计算机列表,就能看出计算机集群的概念已经普及到何种程度。Beowulf 集群(一种由现成的组件创建并运行 Linux 的计算机集群)的出现也产生了一个意想不到的效果。它吸引了各地计算机极客的想象力,尤其是那些经常光顾 Slashdot 新闻网站的人。
不幸的是,许多人认为 Beowulf 集群不太适合日常任务。这确实有一定的道理。至少我个人不会花钱购买在 Beowulf 上运行的Quake 4版本!一方面,像皮克斯这样的公司使用这些计算机系统来渲染他们最新的电影,另一方面,世界各地的科学家都在使用它们进行各种工作,从核反应模拟到人类基因组的解密。好消息是,高性能计算不必局限于学术机构和好莱坞工作室。
在您将应用程序并行化之前,您应该考虑它是否真的需要这样做。并行应用程序通常是由于它们处理的数据对于传统 PC 来说太大,或者程序中涉及的过程需要大量时间而编写的。为了提高一秒钟的速度,是否值得付出并行化代码和管理 Beowulf 集群的努力?在许多情况下,答案是否定的。然而,正如我们将在本文后面看到的那样,在少数情况下,并行化您的代码可以用最少的努力完成,并产生可观的性能提升。
您可以应用相同的方法来处理图像处理、音频处理或任何其他容易分解成若干部分的任务。作为如何针对您手头的任何任务执行此操作的示例,我考虑将图像滤镜应用于您的朋友和我,企鹅 Tux 的一张相当大的图像。
我们首先需要的是一组运行 Linux 的相同计算机,它们通过高速以太网相互连接。千兆以太网是最好的。网络连接的速度是将快速集群拖入困境的一个因素。我们还需要某种共享文件系统和一些集群软件/库。大多数集群使用 NFS 共享硬盘驱动器,尽管也存在更奇特的文件系统,如 IBM 的通用并行文件系统 (GPFS)。对于集群软件,有几个可用的选择。目前的标准是消息传递接口 (MPI),但并行虚拟机 (PVM) 库也应该可以正常工作。MOSIX 和 openMOSIX 最近受到了很多关注,但它们主要用于并非专门为在集群上运行而编写的程序,并且它们通过将多线程程序中的线程分发到其他节点来工作。本文假设您已安装 MPI,尽管使用 PVM 并行化算法的过程完全相同。如果您从未安装过 MPI,Stan Blank 和 Roman Zaritski 都曾在Linux Journal网站上撰写过关于如何设置基于 MPI 的集群的精彩文章(请参阅在线资源)。
每个 MPI 程序的开头都会调用一些子程序,这些子程序会初始化计算机之间的通信,并确定每个节点的“等级”。节点的等级是一个数字,它唯一地标识节点给其他计算机,其范围从 0 到小于集群总大小的数字。节点 0 通常称为主节点,是该过程的控制器。程序完成后,您需要再调用一次以完成该过程,然后再退出。下面是它的完成方式
#include <mpi.h>
#include <stdlib.h>
int main (void) {
int myRank, clusterSize;
int imgHeight, lowerBoundY, upperBoundY,
boxSize;
// Initialize MPI
MPI_Init((void *) 0, (void *) 0);
// Get which node number we are.
MPI_Comm_rank(MPI_COMM_WORLD, &myRank);
// Get how many total nodes there are.
MPI_Comm_size(MPI_COMM_WORLD, &clusterSize);
// boxSize - the amount of the image each node
// will process
boxSize = imgHeight / clusterSize;
// lowerBoundY - where each node starts processing.
lowerBoundY = myRank*boxSize;
// upperBoundY - where each node stops processing.
upperBoundY = lowerBoundY + boxSize;
// Body of program goes here
// Clean-up and exit:
MPI_Finalize(MPI_COMM_WORLD);
return 0;
}
此代码在作为该过程一部分的每台机器上独立运行,因此 lowerBoundY 和 upperBoundY 的值在每台机器上都会有所不同。这些将在下一节中使用。
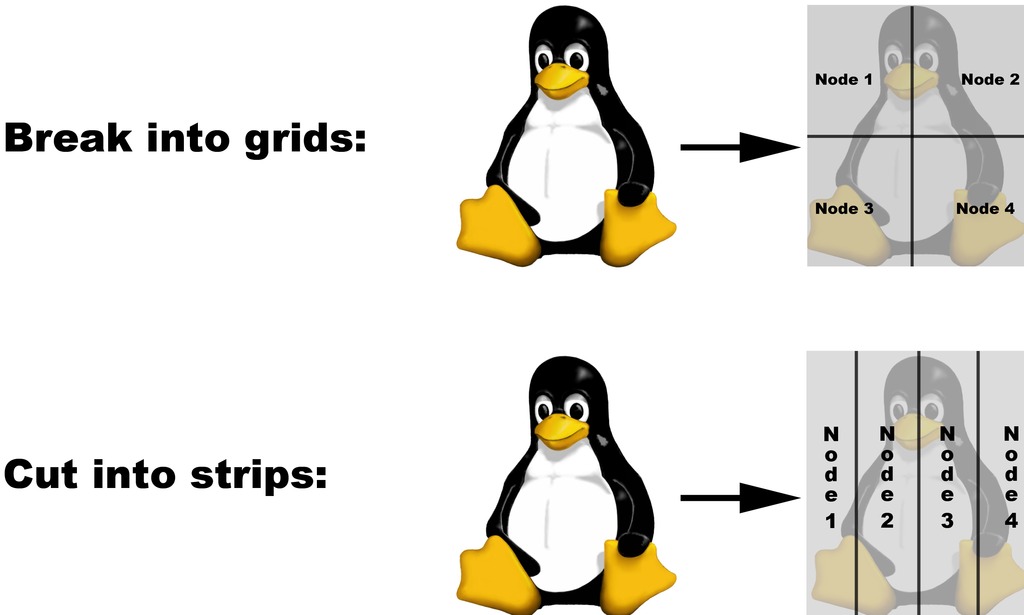
图 1. 将问题分解成更小块的过程称为域分解,通常如图所示完成。
根据滤镜的复杂性、图像的大小和计算机的速度,将滤镜应用于图像可能需要几分钟甚至几个小时才能完成。为了解决这些问题,我们需要将图像的较小块发送到多台计算机,以帮助加快任务速度。图 1 显示了执行此操作的常用方法——我们将图像切割成条带。如果我们有一个大的图像文件,我们可以在 C/C++ 中这样做,如下所示
FILE *imageFile = fopen("image_in.ppm", "rb");
// Safety check.
if (imageFile != NULL) {
// Read in the header.
fread(imageHeader, sizeof(char),
HEADER_LENGTH, imageFile);
// fseek puts us at the point in the image
// that this node will process.
fseek(imageFile, lowerBoundY*WIDTH*3,
SEEK_SET);
// Here is where we read in the colors:
// i is the current row in the image.
// j is the current column in the image.
// k is the color, 0 for red, 1 for blue,
// and 2 for green.
for (i=0; i<boxSize+1; i++) {
for (j=0; j<WIDTH; j++) {
for(k=0; k<3; k++) {
fread(&byte, 1, 1, imageFile);
pixelIndex = i*WIDTH+j+k;
origImage[pixelIndex] = byte;
}
}
}
}
fclose(imageFile);
现在我们有了每个节点存储用于处理的图像片段,我们需要将滤镜应用于图像。《GIMP 文档团队》在 GIMP 文档中很好地描述了如何使用卷积矩阵来完成此操作。许多图像效果(如锐化、模糊、高斯模糊、边缘检测和边缘增强)都具有提供所需效果的独特矩阵。卷积矩阵的工作原理是研究图像的每个像素,并根据相邻像素的值更改其值。我们在本文中考虑边缘检测矩阵,如图 2 所示。

图 2. 此矩阵表示边缘检测滤镜。红色方块表示要考虑的像素,其他数字表示相邻像素。
当我们将此滤镜应用于图像时,我们将每个像素乘以 -4,并将上方、下方以及左侧和右侧像素的值添加到该值。这将成为像素的新值。由于矩阵的角中有零,我们可以简化我们的程序,并通过跳过这些计算来获得更好的性能。下面我展示了如何在实践中完成此操作。在图 3 中,我展示了滤镜对我们的 Tux 图像所做的处理。
for (i=0; i<boxSize; i++) {
for (j=0; j<WIDTH; j++) {
if (i>0 && i<(HEIGHT-1) &&
j>0 && j<(WIDTH-1)){
// Now we apply the filter matrix
// First to the current pixel.
pixelIndex = i*WIDTH + j;
r = origImage[pixelIndex];
g = origImage[pixelIndex+1];
b = origImage[pixelIndex+2];
filter_r = -4*r;
filter_g = -4*g;
filter_b = -4*b;
// Next to the left neighbor.
pixelIndex = i*WIDTH + j - 1;
r = origImage[pixelIndex];
g = origImage[pixelIndex+1];
b = origImage[pixelIndex+2];
filter_r += 1*r;
filter_g += 1*g;
filter_b += 1*b;
// Next to the right neighbor.
pixelIndex = i*WIDTH + j + 1;
r = origImage[pixelIndex];
g = origImage[pixelIndex+1];
b = origImage[pixelIndex+2];
filter_r += 1*r;
filter_g += 1*g;
filter_b += 1*b;
// The neighbor above.
pixelIndex = (i-1)*WIDTH + j;
r = origImage[pixelIndex];
g = origImage[pixelIndex+1];
b = origImage[pixelIndex+2];
filter_r += 1*r;
filter_g += 1*g;
filter_b += 1*b;
// The neighbor below.
pixelIndex = (i+1)*WIDTH + j;
r = origImage[pixelIndex];
g = origImage[pixelIndex+1];
b = origImage[pixelIndex+2];
filter_r += 1*r;
filter_g += 1*g;
filter_b += 1*b;
}
// Record the new pixel.
pixelIndex = i*WIDTH + j;
filterImage[pixelIndex] = filter_r;
filterImage[pixelIndex+1] = filter_g;
filterImage[pixelIndex+2] = filter_b;
}
}
我们可以模仿 readImage() 子程序来创建一个 writeImage() 子程序,以分块形式将图像写入磁盘。
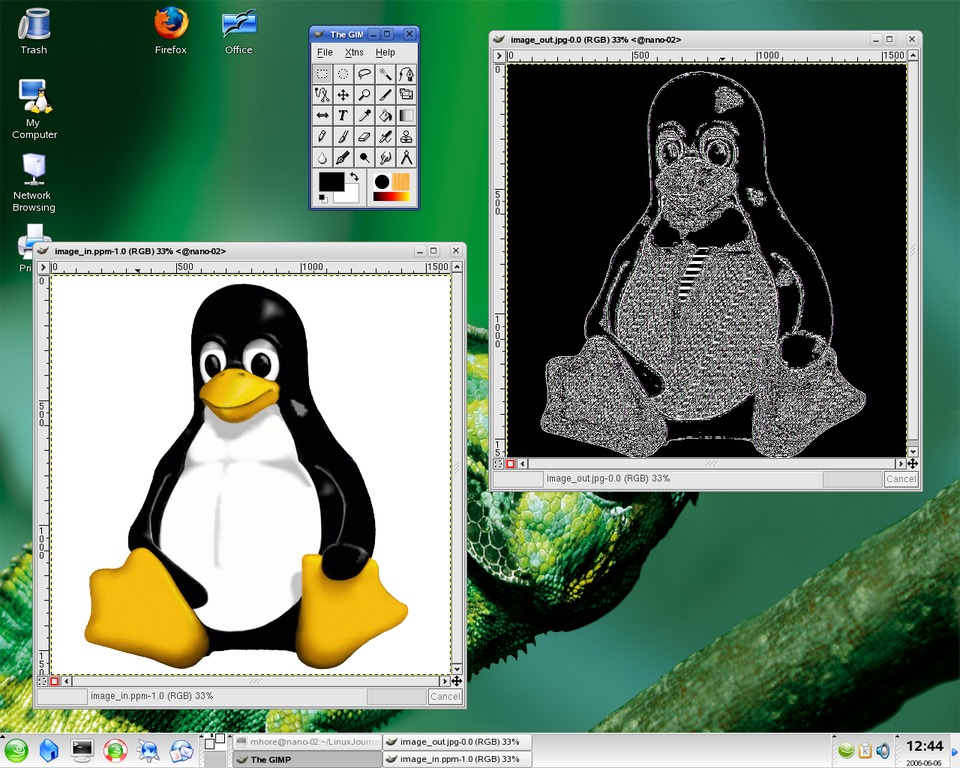
图 3. 左侧是我们 Tux 的原始图像,右侧是应用边缘检测滤镜后的图像。
流行的 MPI 发行版 LAM 和 MPICH 都包含包装脚本,允许用户使用所需的 MPI 库轻松编译他们的程序。这些包装脚本允许您像往常一样将参数传递给 GCC
mpicc:用于 C 程序
mpi++:用于 C++ 程序
mpif77:用于 FORTRAN 77 程序
使用 mpirun 执行您新编译的程序。例如,我使用以下命令编译了我的代码mpicc -O3 -o parallel parallel.c然后使用以下命令执行它mpirun n0 ./parallel。n0 表示该程序仅在节点 0 上运行。要在其他节点上运行它,您可以指定一个范围,如 n0-7(用于八个处理器),或使用mpirun C表示该程序将在所有可用节点上运行。
因此,仅使用几个简单的 MPI 调用,我们就非常轻松地并行化了我们的图像滤镜算法,但我们是否获得了任何性能提升?我们可以通过几种方式获得性能提升。第一种是速度,第二种是我们可以完成多少工作。例如,在单台计算机上,16,000 x 16,000 像素的图像将需要一个包含 768,000,000 个元素的数组!对于许多计算机来说,这太多了——GCC 向我抱怨说数组太大了!通过像我们在上面所做的那样分解图像,我们可以减轻应用程序的内存需求。
我在运行 Fedora Core 1 的 16 节点 Beowulf 集群上测试了上面的代码。每个节点都有 1.0GB 的 RAM、一个 3.06GHz Pentium 4 处理器,并通过千兆以太网连接到其他节点。这些节点还通过 NFS 共享一个公共文件系统。图 4 显示了读取图像、处理图像并将其写回磁盘所需的时间量。
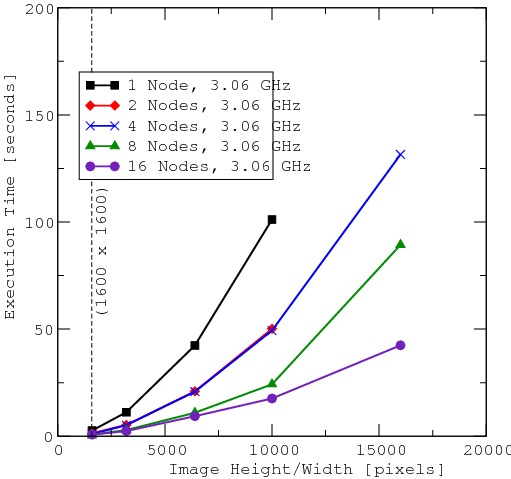
图 4. 这里显示的是程序对于各种图像尺寸和各种集群尺寸所花费的时间。图像尺寸范围从 1,600 x 1,600 像素到 16,000 x 16,000 像素。最大的图像至少需要四个节点。
从图 4 中我们可以看出,即使对于中等大小的图像,并行化此图像滤镜也加快了速度,但真正的性能提升发生在最大的图像上。此外,对于超过 10,000 x 10,000 像素的图像,由于内存限制,至少需要四个节点。此图还显示了在何处并行化代码是一个好主意,以及在何处不是。特别是,从 1,600 x 1,600 像素图像到大约 3,200 x 3,200 像素图像,程序的性能几乎没有任何差异。在此区域中,图像太小,从内存角度来看,并行化代码也没有任何好处。
为了给我们的图像处理程序的性能提供一些数字,一台 3.06GHz 的机器大约需要 50 秒才能读取、处理并将 6,400 x 6,400 的图像写入磁盘,而 16 个节点协同工作则大约需要十秒钟才能完成此任务。即使在 16,000 x 16,000 像素的情况下,16 个节点协同工作也可以比一台机器处理小 6.25 倍的图像更快地处理图像。
本文仅演示了一种利用 Beowulf 集群高性能的可能方法,但相同的概念几乎用于所有并行程序中。通常,每个节点读取一小部分数据,对其执行一些操作,然后将其发送回主节点或将其写入磁盘。以下是我认为非常适合并行化的四个领域示例
图像滤镜:我们在上面看到了并行处理如何极大地加快图像处理速度,并且还可以让用户能够处理巨大的图像。一套利用集群优势的 GIMP 等应用程序的插件可能非常有用。
音频处理:将效果应用于音频文件也可能需要大量时间。Audacity 等开源项目也有望从并行插件的开发中受益。
数据库操作:需要处理大量记录的任务可能会受益于并行处理,方法是让每个节点构建一个仅返回所需完整集合一部分的查询。然后,每个节点根据需要处理记录。
系统安全:系统管理员可以看到其用户的密码有多安全。尝试使用 Beowulf 集群对 /etc/shadow 进行暴力破解解码,方法是将检查范围分配到多台机器上。这将节省您的时间,并让您安心(但愿如此),您的系统是安全的。
我希望本文已经展示了并行编程是如何面向所有人的。我已经列出了一些我认为是应用此处介绍的概念的良好领域的示例,但我相信还有许多其他领域。
确保您成功并行化正在处理的任何任务有几个关键。首先是将计算机之间的网络通信保持在最低限度。与单节点上发生的事情相比,在节点之间发送数据通常需要相对较长的时间。在上面的示例中,节点之间没有通信。但是,某些任务可能需要它。其次,如果您要从磁盘读取数据,请仅读取每个节点需要的数据。这将帮助您将内存使用量保持在最低限度。最后,在执行需要节点彼此同步的任务时要小心,因为这些进程默认情况下不会同步。有些机器的运行速度会略快于其他机器。在侧边栏中,我包含了一些常用的 MPI 子程序,您可以利用这些子程序,包括一个可以帮助您同步节点的子程序。
展望未来,我预计计算机集群将在我们的日常生活中发挥更加重要的作用。我希望本文已经让您相信,为这些机器开发应用程序非常容易,并且它们所展示的性能提升足以在各种任务中使用它们。我还要感谢孟菲斯大学物理系 Mohamed Laradji 博士允许我在他小组的 Beowulf 集群上运行这些应用程序。
一些必要且有用的 MPI 子程序
MPI 中包含 200 多个子程序,它们在某些方面都很有用。之所以有这么多调用,是因为 MPI 在各种系统上运行,并满足各种需求。以下是一些对于本文演示的这类算法最有用的调用
MPI_Init((void*) 0, (void*) 0)— 初始化 MPI。
MPI_Comm_size(MPI_COMM_WORLD, &clstSize)— 返回 clstSize 中的集群大小(整数)。
MPI_Comm_rank(MPI_COMM_WORLD, &myRank)— 返回 myRank 中节点的等级(整数)。
MPI_Barrier(MPI_COMM_WORLD)— 暂停,直到集群中的所有节点都到达代码中的此点。
MPI_Wtime()— 返回自过去某个未定义事件以来的时间。可用于计时子程序和其他进程。
MPI_Finalize(MPI_COMM_WORLD)— 停止所有 MPI 进程。在您的进程终止之前调用此函数。
本文资源: /article/9135。
Michael-Jon Ainsley Hore 是孟菲斯大学的一名学生,也是一个全面的好人,正在攻读计算物理学专业的物理学硕士学位。他将于 2007 年 5 月毕业,并计划在毕业后立即开始攻读博士学位。
