
使用 libferris 的联邦桌面和文件服务器搜索
libferris 项目有两个主要目标:将任何内容挂载为文件系统,并为其可以挂载的任何内容提供索引和搜索。在我的 2005 年 2 月发表于Linux Journal的文章“使用 libferris 进行文件系统索引”中描述了使用 libferris 提供桌面搜索。自那时以来,libferris 的索引功能得到了增长。一项新功能是允许一组索引在逻辑上充当单个“联邦”索引。这使您可以为您的文件服务器创建一个索引,为您的 man 页面创建另一个索引,并为您的个人文档创建第三个索引。然后,您可以针对所有这三个索引运行查询,就像它们是一个单一索引一样。
libferris 使用插件系统处理其索引和搜索。目前有 db4、PostgreSQL、ODBC、Redland (RDF)、Xapian、Beagle、Yahoo、LDAP、CLucene、Lucene 和外部进程的索引插件。在 libferris 中形成联邦索引的索引可以使用这些索引插件的任意混合。
libferris 有两种不同类型的索引插件:全文和元数据。libferris 的元数据接口基于扩展属性 (EA) 内核接口。拥有两种索引插件类型允许索引插件在磁盘上组织数据,以最好地支持查询。
全文索引通常会为人类语言中的每个单词维护一个列表,其中列出哪些文件包含该单词,以及该单词对于文档的重要性统计度量。该统计信息允许在结果中首先呈现“更相关”的文档。此类统计信息通常与文件的大小、单词在该文件中出现的频率以及该单词在所有索引文件中出现的稀有程度有关。
元数据索引必须将 docid 与关键字和值关联起来。例如,/tmp/foo 的大小为 145。元数据索引必须能够处理诸如 size>=4kb && modified this week 之类的查询,并有效地返回满足此查询的文件的 docid。元数据和全文索引插件之间的主要区别在于,元数据查询包含对元数据的值比较(例如,mtime>=上周),而全文查询通常更关注单词在文件中的存在。
从索引用户的角度来看,这种区别是一个令人恼火的实现产物。为了解决这个问题,可以使用feaindex-attach-fulltext-index命令将全文索引链接到元数据索引。然后可以在元数据索引上执行结合了元数据和全文搜索的查询。将元数据索引视为拥有全文索引是很方便的。
元数据查询格式保留任何以 ferris- 开头的元数据名称具有特殊含义。元数据名称 ferris-fulltext-query 或 ferris-ftx 将执行其查询值作为链接的全文索引上的全文查询。清单 1 显示了一个元数据查询,它查找给定大小以下且包含两个给定单词的所有文件。如果我们在查询中使用 or 运算符 | 而不是用 & 组合结果,则将返回与任一子查询匹配的任何结果。要查询全文索引,请使用findexquery命令。组合的元数据和全文索引使用元数据查询命令feaindexquery.
清单 1. 组合的全文和元数据索引查询
$ feaindexquery \ '(&(size<=250k)(ferris-ftx==alice wonderland))'
当像这样组合两种类型的索引插件时,上面对 docid 的讨论变得相关。当元数据和全文索引插件都使用相同的存储时,可以获得最大的效率——例如,PostgreSQL(元数据)和 TSearch2(全文)插件使用相同的底层 PostgreSQL 数据库,或者两个索引都使用相同的 CLucene 存储。
获得效率的原因是每个 URL 都具有相同的 docid。以 PostgreSQL 组合为例,为了解决清单 1 中的查询,将针对 TSearch2 插件运行全文子查询,从而获得一组匹配的 docid。获得与大小查询匹配的 docid 集合,并返回大小查询和全文查询结果的交集。只有在已知元数据索引和全文索引对于相同的 URL 具有相同的 docid 时,才能完成最后一步。否则,全文查询中的 docid 必须首先转换为 URL 字符串,然后再转换为元数据索引的 docid。
当像这样一起使用元数据和全文插件时,请确保每个文件都添加到两个索引中。
每个元数据索引插件都会自动检测到直接使用链接到它的全文索引的 docid 是否安全。
联邦索引插件是一个元数据插件。联邦是使用多个元数据索引形成的,其中一个被指定为可写索引。由于每个元数据索引都可以拥有一个全文索引,因此这允许任意数量的全文和元数据索引的联邦。联邦中的每个索引都可以独立于联邦进行更新。
索引是使用 fcreate 或 gfcreate 工具创建的。前者是命令行工具,后者具有 GTK+ 2 GUI。在本文中,我使用 fcreate 命令。要了解索引创建期间可用的其他选项,只需将 fcreate 替换为 gfcreate,就会显示一个 GUI。元数据索引和全文索引都驻留在目录中,即使只有配置设置保存在该目录中也是如此。例如,使用 PostgreSQL 插件,索引数据将位于 PostgreSQL 数据库中,并且只有一个小配置文件将位于文件系统目录中。像这样使用目录允许您通过传递文件系统路径来告诉 libferris 要使用哪个索引。
libferris 附带了一些 shell 脚本,以帮助设置索引。对于 PostgreSQL 和 CLucene,这些脚本以 ferris-recreate-primary-fulltext-and-eaindex-as 开头,并以 clucene 或 postgresql 结尾。两者都旨在设置您默认的元数据和全文索引,使用指定的索引插件。您的默认索引存储在 ~/.ferris 的子目录中。
我们将使我们的默认索引成为本地 CLucene 索引(用于个人文件)和 PostgreSQL(用于文件服务器)的联邦。这意味着我们总共将有五个索引:联邦元数据索引、元数据和全文 CLucene 索引以及元数据和全文 PostgreSQL 索引。
两个 CLucene 索引将链接在一起,两个 PostgreSQL 索引将相互链接。我们可以使用 ~/.ferris 中的默认路径作为联邦索引。我们将把 CLucene 索引放在 ~/clucene-index 中。我假设将运行 PostgreSQL 并维护文件服务器索引的机器是一台名为 fshost 的服务器。如果需要,索引可以与实际文件服务器位于不同的机器上。如果您愿意,可以将许多文件服务器机器和其他文档的内容添加到文件服务器索引中。
对于 PostgreSQL 索引,索引的目录中将只有一个配置文件。此文件将包含信息,告诉索引插件数据库的位置以及要使用的用户名和密码以进行连接。我假设我们在文件服务器上的 /ferris-index 中创建 PostgreSQL 文件服务器索引,尽管任何路径都可以。为了使打算使用此索引的人员更简单,将其目录放在文件服务器上使其在联邦中的使用变得简单。我们将使用 PostgreSQL 数据库名称 ferrisindex。设置如图 1 所示。
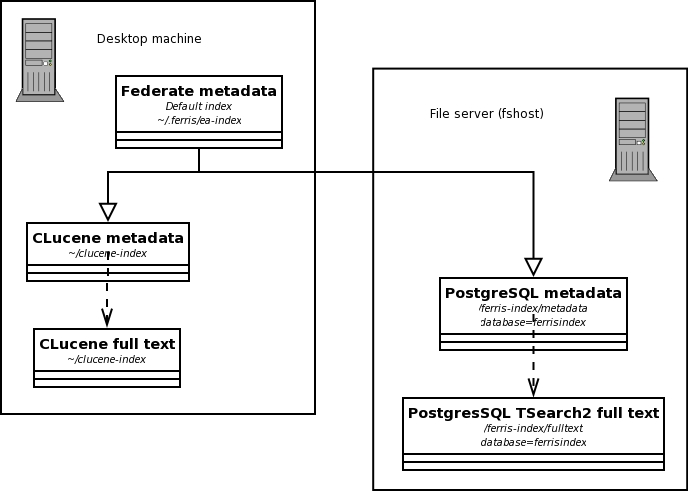
图 1. 索引联邦
要使用 CLucene 进行本地索引,我们可以使用clucene recreate脚本,并对索引路径进行少量修改,如清单 2 所示。请注意,第二个 fcreate 具有 db-exists=1 参数,以告知索引插件在此路径下存在现有的 CLucene 索引。这会将元数据和全文信息都放入同一个 CLucene 索引中。
确保您要在查询中使用的元数据未在 attributes-not-to-index 中列出,并且不会与索引的 attributes-not-to-index-regex 匹配。运行gfcreate /tmp --create-type=eaindexclucene以查找这些参数的当前默认值。
清单 2. 设置两个 CLucene 索引
$ mkdir -p ~/clucene-index
$ cd ~/clucene-index
$ fcreate `pwd` \
--create-type=fulltextindexclucene
$ fcreate `pwd` \
--create-type=eaindexclucene db-exists=1
$ feaindex-attach-fulltext-index \
--ea-index-path `pwd` \
--fulltext-index-path `pwd`
设置 PostgreSQL/TSeach2 组合是一个两步过程。第一步,使用 ferris-setup-template-findex-database.sh 脚本,创建一些模板数据库,并且只需要执行一次。该脚本假定它正在具有 PostgreSQL 数据库的主机上运行。此脚本将通用索引搜索树、TSearch2 和 PL/pgSQL 安装到元数据和全文插件利用的两个模板数据库中。其中一些功能存在于许多发行版中的 postgresql-contrib 包中。
清单 3 中显示的命令在主机 fshost 上的同一数据库中创建 TSearch2 全文索引和元数据索引。这些索引将如前所述位于 /ferris-index 中。此目录应可通过网络供打算使用该索引的人员读取。下面,我假设这是使用 NFS 导出的,并使用fshost:/ferris-index访问该路径。然后将这些索引链接在一起以允许组合查询。确保 /ferris-index 中的 db 文件对于应该能够访问此索引的人员是可读的。
清单 3. 在文件服务器上运行以创建 PostgreSQL 索引的命令
$ ferris-setup-template-findex-database.sh $ mkdir -p /ferris-index/metadata $ mkdir -p /ferris-index/fulltext $ cd /ferris-index $ fcreate /ferris-index/fulltext \ --create-type=fulltextindextsearch2 \ dbname=ferrisindex host=fshost $ fcreate metadata \ --create-type=eaindexpostgresql \ host=fshost dbname=ferrisindex db-exists=1 $ feaindex-attach-fulltext-index \ --ea-index-path metadata \ --fulltext-index-path fulltext
回到桌面机器上,然后我们创建一个联邦索引,将本地 CLucene 和远程 PostgreSQL 索引组合在一起,如清单 4 所示。
清单 4. 使用 PostgreSQL 重新创建默认索引
$ mount fshost:/ferris-index /ferris-index $ fcreate ~/.ferris/ea-index \ --create-type=eaindexfederation \ primary-write-index-url=~/clucene-index \ read-only-federates=\ "~/clucene-index,/ferris-index/metadata"
这假设用于创建 PostgreSQL 索引的参数对于桌面用户有效。由于 libferris 知道如何挂载 db4 文件,因此可以使用 libferris 客户端完成对配置设置的更改。请参阅清单 5,其中使用了 ferris-redirect 命令以允许 shell 重定向到任何 libferris 文件中。
清单 5. 检查索引元数据并更改用户名
$ cd /ferris-index/metadata
$ ferrisls -lh ea-index-config.db
11 cfg-idx-dbname
6 cfg-idx-host
...
$ fcat ea-index-config.db/cfg-idx-host
fshost
$ echo -n foouser | ferris-redirect \
--trunc ea-index-config.db/cfg-idx-user
联邦索引插件将其所有工作委派给其他现有索引。因此,我们指定当文件添加到联邦索引时,联邦插件应将添加操作委派给维护我们个人索引的 CLucene 插件。
大多数索引插件都会检测文件自上次索引以来是否未更改,并在重新索引时自动跳过该文件。至少 Xapian、Redland、CLucene 和 PostgreSQL 插件支持此功能。目前不支持此功能的插件将发出警告。这允许 cron 作业只需运行 find 来列出应包含在索引中的文件,并将它们通过管道传递给 feaindexadd。
清单 6 显示了填充两个索引的命令。请注意,当在共享数据库中将 CLucene 用于全文索引和元数据索引时,您必须首先将文件添加到全文索引。此限制是由于 CLucene API 造成的。
清单 6. 将文件添加到索引
# Local index $ find ~ -name ".*" -prune -o -print | findexadd \ -P ~/clucene-index --filelist-stdin $ find ~ -name ".*" -prune -o -print | feaindexadd \ -P ~/clucene-index --filelist-stdin # File server index, run on fshost $ find /documents | findexadd \ -P /ferris-index/fulltext \ --filelist-stdin $ find /documents | feaindexadd \ -P /ferris-index/metadata \ --filelist-stdin
现在我们可以选择在我们的个人文件、文件服务器或两者中查找我们的查询。所有三个的查询语法都是相同的;我们只需要指定要使用哪个索引。如果我们不指定索引,我们将使用默认索引,在我们的桌面机器上,默认索引是我们的联邦。清单 7 显示了一些示例查询。最后一个示例中的 =~ 运算符是正则表达式匹配。
清单 7. 组合的全文和元数据索引查询
# Federation query $ feaindexquery \ '(&(size<=250k)(ferris-ftx==alice wonderland))' # Recently modified local files with a given URL $ feaindexquery \ -P ~/clucene-index \ '(&(mtime>=begin last week)(url=~journal))'
libferris 可以将查询结果呈现为文件系统。这可以为网络上的客户端提供一个快速界面来查询文件服务器。ferrisls 命令可以将其结果输出为 XML 文件。给定一个 Web 表单和你最喜欢的 Web 脚本语言,可以使用 ferrisls 运行查询,并将生成的 XML 文件 XSL 转换为客户端的漂亮 HTML。
FUSE 模块还允许通过内核直接访问搜索结果,以便导出到网络。
eaq:// 虚拟文件系统将查询作为目录名,并将使用与查询匹配的文件填充虚拟目录。其他密切相关的查询文件系统是 eaquery:// 树。eaquery:// 文件系统具有稍长的 URL,但它允许您设置返回的结果数量限制,并设置如何解决冲突的文件名。清单 8 中显示了一些示例查询。通常,文件的 URL 用作 eaquery:// 文件系统的文件名。shortnames 选项仅使用文件名,并且当来自不同目录的两个结果恰好具有完全相同的文件名时,它会在其中一个结果的文件名后附加一个唯一编号。这很可能发生在常见文件名上,例如 README。
清单 8. 作为文件系统的查询结果
# All files modified recently $ ferrisls -lh "eaq://(mtime>=begin last week)" # Same as above but limited to 100 results # as an XML file $ ferrisls --xml \ "eaquery://filter-100/(mtime>=begin last week)" # limit of 10, # resolve conflicts with version numbers # include the desired metadata in the XML result $ ferrisls --xml \ --show-ea=mtime-display,url,size-human-readable \ "eaquery://filter-shortnames-10/(mtime>=blast week)"
默认的联邦插件假定对于任何文件,都使用相同的 URL 从联邦中的所有索引访问它。例如,考虑文件服务器上 URL 为 file://doc/lj.txt 的文件。如果此文件作为联邦查询的匹配项返回,则执行搜索的人员将希望相对于他或她的本地机器在 file://doc/lj.txt 处找到该文件。如果 /doc 目录作为桌面机器的 NFS 共享导出,则应将其挂载为客户端上的 /doc。
如果文件服务器和客户端之间的路径不同,则可以通过联邦插件完成 URL 修改。受支持的 URL 修改 Perl 用户会很熟悉。对于联邦中的每个索引,可以提供正则表达式和格式字符串来重写从该索引返回的 URL。URL 重写如清单 9 所示。此示例将更改文件服务器上 /tmp 中的任何文件,使其成为桌面机器上的 mytmp。
清单 9. 更改文件服务器为本地 NFS 挂载点返回的 URL
$ feaindex-federation-add-url-substitution-regex-for-index \ --sub-index-path /ferris-index/metadata \ --regex '^file:[/]+tmp/(.*)' \ --format 'file:///mytmp/\1' $ feaindexquery '(ferris-ftx==alice)' file:///mytmp/alice13a.txt
为了确定文档自上次索引以来是否未更改,PostgreSQL 索引插件会将数据库中的一些信息加载到 RAM 缓存中。如果多个进程正在更新 PostgreSQL 索引,则可能会完成比严格意义上必要的工作更多的工作。PostgreSQL 索引插件可以安全地在客户端执行查询时更新索引。许多其他插件仅提供底层索引库提供的并发访问级别。这通常相当于多个索引读取器或一个独占写入器。
有用于元数据和全文索引的 Xapian 索引插件。不幸的是,Xapian 对元数据查询的支持有限,主要仅限于相等性。对于元数据和全文组合,如果同时使用 Xapian,则必须先将文件添加到元数据索引,然后再添加到全文索引。
CLucene 插件比 Lucene 插件更容易使用。后者依赖于 GCJ 和 Lucene 的安装,GCJ 可以针对 Lucene 编译 C++ 代码。
需要额外的努力才能将 PostgreSQL 索引插件用于支持 emblem 和地理空间查询的文件服务器索引。
本文的资源: /article/9390。
Ben Martin 从事文件系统工作已超过十年。他目前正在攻读博士学位,将语义文件系统与形式概念分析相结合,以改善人与文件系统的交互。

