
OpenOffice.org ODF, Python 和 XML
我的妻子是一位作家,在今天这意味着她使用文字处理程序。这是一个复杂而强大的程序——OpenOffice.org Writer——但偶尔它无法完成她想要做的事情。在本文中,我们将了解 OpenDocument 格式 (ODF) 文件的结构,并了解 Python 及其 XML 库如何提供帮助。图 1 显示了一个示例。
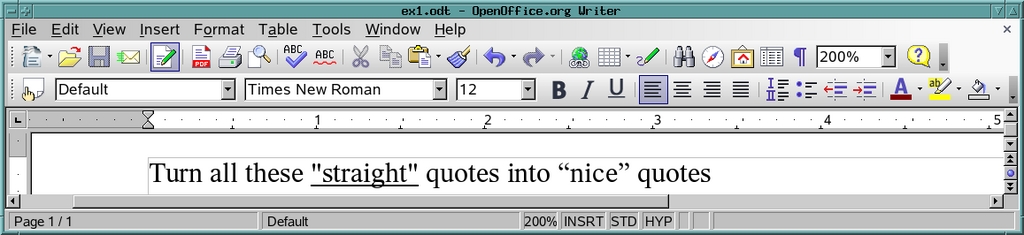
图 1. 转换引号
手动转换几个段落中的引号并不难——甚至几页也可以,如果我只做一次的话。但是,不得不在后续修订中重复这样的手动操作变得很乏味,尤其是在较长的文档中,例如诗集或小说。(例如,在从电子邮件消息导入纯文本后,我们可能必须重复这些操作。)
幸运的是,ODF 是 开放 的,因此我们应该能够在文字处理程序之外操作文件内容。
让我们看看我们是否可以手动完成,只是为了确保我们知道自己在做什么。一旦我们可以做到这一点,我们将创建一个脚本来对文档进行一些更雄心勃勃的操作。
我在某处读到 ODF 文件是 XML 文件的 zip 压缩包。那么,让我们看看它是否真的是一个——如果是,里面有什么
% unzip -l ex1.odt
Archive: ex1.odt
Length Date Time Name
-------- ---- ---- ----
39 11-15-06 01:55 mimetype
0 11-15-06 01:55 Configurations2/statusbar/
0 11-15-06 01:55 Configurations2/accelerator/current.xml
0 11-15-06 01:55 Configurations2/floater/
0 11-15-06 01:55 Configurations2/popupmenu/
0 11-15-06 01:55 Configurations2/progressbar/
0 11-15-06 01:55 Configurations2/menubar/
0 11-15-06 01:55 Configurations2/toolbar/
0 11-15-06 01:55 Configurations2/images/Bitmaps/
0 11-15-06 01:55 Pictures/
2872 11-15-06 01:55 content.xml
9786 11-15-06 01:55 styles.xml
1109 11-15-06 01:55 meta.xml
878 11-15-06 01:55 Thumbnails/thumbnail.png
6611 11-15-06 01:55 settings.xml
2037 11-15-06 01:55 META-INF/manifest.xml
-------- -------
23332 16 files
%好消息——它是一个 zip 压缩包。
所以,计划是这样的:解压缩它,修改一个(或多个)文件,然后将所有内容重新打包。我们将按相同的顺序打包文件,以防万一它很重要。因此,我们需要保存文件列表。
运行 unzip 的列表包含该文件列表,以及其他一些内容。让我们只选择包含文件名的行(在本例中,是带有 : 后跟数字的行),并仅打印文件名。一个简单的 sed 命令可以做到这一点
% unzip -l ex1.odt | sed -n '/:[0-9][0-9]/s|^.*:.. *||p' mimetype Configurations2/statusbar/ Configurations2/accelerator/current.xml Configurations2/floater/ Configurations2/popupmenu/ Configurations2/progressbar/ Configurations2/menubar/ Configurations2/toolbar/ Configurations2/images/Bitmaps/ Pictures/ content.xml styles.xml meta.xml Thumbnails/thumbnail.png settings.xml META-INF/manifest.xml %
看起来不错。让我们将列表保存在 shell 变量中——我们将使用 F(代表文件)
% F=$(unzip -l ex1.odt | sed -n '/:[0-9][0-9]/s|^.*:.. *||p')
解决这个问题后,下一个问题是,要修改哪个文件?为了找出答案,让我们找到包含单词 quotes 的文件,该单词出现在文档中。我们将 ex1.odt 解压缩到一个空目录中,并询问 grep,记住也要检查子目录中的文件
% cd TMP % unzip -q ~/oo/ex1.odt % find . -type f | xargs grep -l quote ./content.xml %
好的,content.xml 就是它。文本编辑器提供了一种操作 content.xml 的方法,所以让我们尝试一下。相关部分在 Emacs 中看起来像图 2。
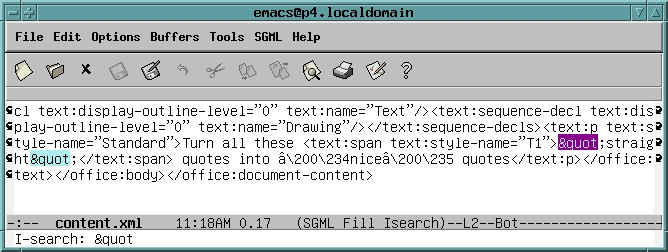
图 2. 在 Emacs 中编辑 XML
两个出现的 "(在图 2 中部分突出显示)代表直引号。
我将直引号更改为适当的弯引号或智能引号(在单词 nice 的两侧找到),如图 3 所示。更改的区域再次被部分突出显示。
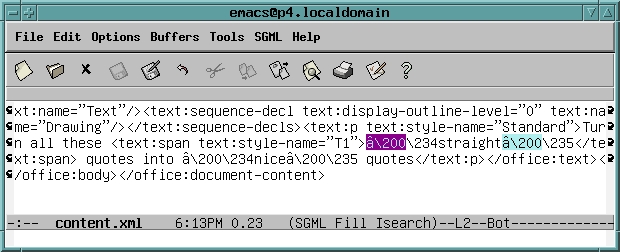
图 3. 使用智能引号编辑的 XML
完成此操作后,让我们压缩文件(保存在 $F 中的列表)以创建 ex2.odt,并看看 OpenOffice.org Writer 对此有何看法
% zip -q ~/oo/ex2.odt $F % oowriter ~/oo/ex2.odt
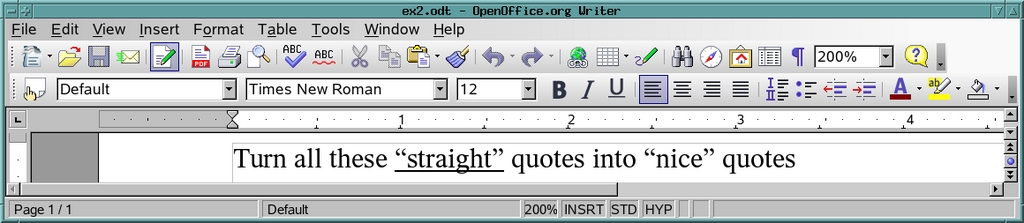
图 4. Writer 识别新引号
它成功了(图 4)!单词 straight 周围以前的直引号现在变成了弯引号,甚至以正确的方向弯曲。因此,回顾一下我们到目前为止所做的事情
创建了 ex1.odt 中文件的列表(将其保存在 $F 中)。
解压缩了 ex1.odt。
手动在 content.xml 中做了一个简单的更改。
创建了 ex2.odt(使用 $F)。
使用 OpenOffice.org Writer 验证了 ex2.odt。
该练习证明了这个概念,所以现在我们可以开始工作了。我妻子的诗集大约有 60 页长,需要解决以下问题
那些直引号,来自纯文本电子邮件消息或其他文字处理器。
撇号(或单引号),它们也是直的,而不是以正确的方式弯曲。
双连字符和较短的破折号(en dash),都应该更改为较长的 em dash。
OpenOffice.org Writer 具有用于创建 en dash 以及更长的 em dash 的击键序列。有时键入了错误的序列,因此出现了 en dash 而不是所需的 em dash。从电子邮件消息导入的纯文本有时带有双连字符(即 --)。
具体来说,我们想将图 5 中显示的内容转换为图 6 中显示的内容。
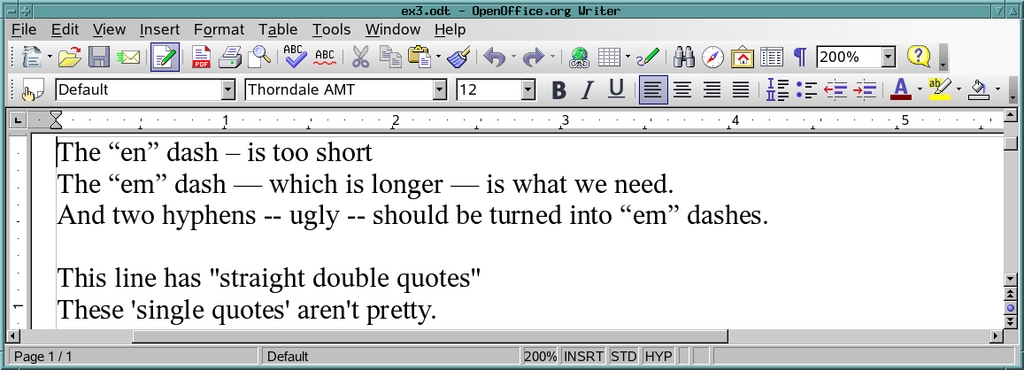
图 5. 之前...
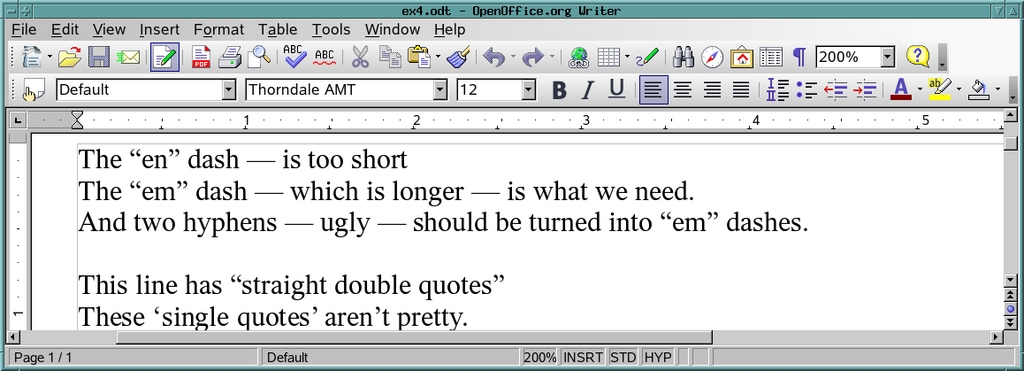
图 6. ...之后
让我们分两部分开发自动化脚本,并自上而下地进行。顶层将创建一个临时目录,解压缩原始文档,然后运行底层程序(指定为 fixit.py)来修改 content.xml。之后,它将文件打包到新文档中并清理。
我想为每个任务使用最合理的最高级语言;对于顶层,这可能是 shell。这个名为 fixit.sh 的脚本结果比我想象的要长,主要是因为所有的错误检查
#!/bin/bash
# Script to fix up OpenDocument Text (.odt) files
# "cd" to the directory containing "fixit.py".
# Make $TMPDIR, a new temporary directory
TMPDIR=/tmp/ODFfixit.$(date +%y%m%d.%H%M%S).$$
if rm -rf $TMPDIR && mkdir $TMPDIR; then
: # Be happy
else
echo >&2 "Can't (re)create $TMPDIR; aborting"
exit 1
fi
OLDFILE=$1
NEWFILE=$2
# Check number of parameters.
# Ensure $NEWFILE's dir exists and is writable.
# Quietly Unzip $OLDFILE. Whine and abort on error.
if [[ $# -eq 2 ]] &&
touch $NEWFILE && rm -f $NEWFILE &&
unzip -q $OLDFILE -d $TMPDIR ; then
: # All good; be happy.
else
# Trouble! Print usage message, clean up, abort.
echo >&2 "Usage: $0 OLDFILE NEWFILE"
echo >&2 " ... both OpenDocument Text (odt) files"
echo >&2 "Note: 'OLDFILE' must already exist."
rm -rf $TMPDIR
exit 1
fi
# Save file list in $F; is content.xml there?
F=$(unzip -l $OLDFILE |
sed -n '/:[0-9][0-9]/s|^.*:.. *||p')
if echo "$F" | grep -q '^content\.xml$'; then
: # Good news; we have content.xml
else
echo >&2 "content.xml not in $OLDFILE; aborting"
echo >&2 TMPDIR is $TMPDIR
exit 1
fi
# Now invoke the Python program to fix content.xml
mv $TMPDIR/content.xml $TMPDIR/OLDcontent.xml
if ./fixit.py $TMPDIR/OLDcontent.xml > \
$TMPDIR/content.xml; then
: # It worked.
else
echo >&2 "fixit.py failed in $TMPDIR; aborting"
exit 1
fi
if (cd $TMPDIR; zip -q - $F) | cat > $NEWFILE; then
# Everything worked! Clean up $TMPDIR
rm -rf $TMPDIR
else # something Bad happened.
echo >&2 "zip failed in $TMPDIR on $F"
exit 1
fi
它很长但很简单,所以我在这里只解释一些事情。
首先,临时目录名称包括日期和时间(date +%stuff),以及 shell 的进程 ID($$)防止名称冲突。
其次,grep 行看起来是这样的,因为我希望它接受 content.xml,但不接受类似 discontent.xml 或 content-xml 的东西。
最后,我们清理临时目录 ($TMPDIR),除非在某些错误情况下,我们在这些情况下保持完整以进行调试,并告诉用户它在哪里。
我们还不能运行此脚本,因为我们还没有让 fixit.py 实际修改 content.xml。但是,我们可以使用存根来验证我们目前拥有的内容。 fixit.sh 脚本假定 fixit.py 将接受一个参数(原始 content.xml 的路径名)并将结果放到 stdout 上。这恰好与 /bin/cat 的调用序列(带有一个参数)匹配;因此,如果我们使用 /bin/cat 作为我们的 fixit.py,fixit.sh 应该为我们提供一个新文档,其内容与旧文档相同。所以,让我们试一试
% ln -s /bin/cat fixit.py % ./fixit.sh ex1.odt foo.odt % ls -l ex1.odt foo.odt -rw-r--r-- 1 collin users 7839 2006-11-14 17:50 ex1.odt -rw-r--r-- 1 collin users 7900 2006-11-14 19:45 foo.odt % oowriter foo.odt
新文件 foo.odt 比 ex1.odt 稍大,但是当我用 OpenOffice.org Writer 查看它时,它具有正确的内容。
至于编写一个用于操作 content.xml 的程序——早在 1990 年代,我可能会花很多时间在 yacc(或 bison)上——但今天,带有 XML 库的 Python 是更自然的选择。
我的桌面发行版 (SUSE 9.3) 包括软件包 python-doc-2.4-14 和 python-doc-pdf-2.4-14。您也可以从 www.python.org 获取文档。在任何一种情况下,我们都需要库参考,其中包含有关 Python XML 库的信息;它们在“结构化标记处理工具”一章(当前为第 13 章)中描述。
列出了几个模块,我注意到一个标记为轻量级的:xml.dom.minidom——轻量级文档对象模型 (DOM) 实现。
轻量级听起来不错。库参考给出了这些示例
from xml.dom.minidom import parse, parseString
dom1 = parse('c:\\temp\\mydata.xml') # parse an XML file by name
datasource = open('c:\\temp\\mydata.xml')
dom2 = parse(datasource) # parse an open file因此,看起来 parse 可以接受文件名或文件对象。
一旦我们创建了一个 dom 对象,我们可以用它做什么?Python 的一个优点是交互式 shell,它允许您一次尝试一件事情。让我们解压缩第一个示例并查看内部
% mkdir TMP
% unzip -q -d TMP ex1.odt
% python
Python 2.4 (#1, Mar 22 2005, 21:42:42)
[GCC 3.3.5 20050117 (prerelease) (SUSE Linux)] on linux2
Type "help", "copyright", "credits" or "license"
for more information.
>>> import xml.dom.minidom
>>> dom=xml.dom.minidom.parse("TMP/content.xml")
>>> dir(dom)
[ --- a VERY long list, including ---
'childNodes', 'firstChild', 'nodeName', 'nodeValue', ... ]
>>> len(dom.childNodes)
1
>>> c1=dom.firstChild
>>> len(c1.childNodes)
4
>>> for c2 in c1.childNodes: print c2.nodeName
...
office:scripts
office:font-face-decls
office:automatic-styles
office:body
>>>请注意 Python 的 dir 函数如何告诉对象中有哪些字段(包括方法)。childNodes 字段看起来很有趣,而且实际上,文档似乎具有树结构。经过更多手动探索后,我发现文本包含在某些节点的 data 字段中。因此,我编写了一个简单的脚本 fix1-NAIVE.py
#!/usr/bin/python -tt
import xml.dom.minidom
import sys
DEBUG = 1
def dprint(what):
if DEBUG == 0: return
sys.stderr.write(what + '\n')
def handle_xml_tree(aNode, depth):
if aNode.hasChildNodes():
for kid in aNode.childNodes:
handle_xml_tree(kid, depth+1)
else:
if 'data' in dir(aNode):
dprint(("depth=%d: " + aNode.data) % depth)
def doit(argv):
doc = xml.dom.minidom.parse(argv[1])
handle_xml_tree(doc, 0)
# sys.stdout.write(doc.toxml('utf-8'))
if __name__ == "__main__":
doit(sys.argv)dprint 例程在 stderr 上打印调试信息;稍后我们将设置 DEBUG=0,它将保持静默。好的,让我们在上面的 content.xml 上尝试一下
% ./fix1-NAIVE.py TMP/content.xml
depth=5: Turn all these
depth=6: "straight"
Traceback (most recent call last):
File "./fix1-NAIVE.py", line 24, in ?
doit(sys.argv)
File "./fix1-NAIVE.py", line 20, in doit
handle_xml_tree(doc, 0)
File "./fix1-NAIVE.py", line 13, in handle_xml_tree
handle_xml_tree(kid, depth+1)
File "./fix1-NAIVE.py", line 13, in handle_xml_tree
handle_xml_tree(kid, depth+1)
File "./fix1-NAIVE.py", line 13, in handle_xml_tree
handle_xml_tree(kid, depth+1)
File "./fix1-NAIVE.py", line 13, in handle_xml_tree
handle_xml_tree(kid, depth+1)
File "./fix1-NAIVE.py", line 13, in handle_xml_tree
handle_xml_tree(kid, depth+1)
File "./fix1-NAIVE.py", line 16, in handle_xml_tree
dprint(("depth=%d: " + aNode.data) % depth)
File "./fix1-NAIVE.py", line 8, in dprint
sys.stderr.write(what + '\n')
UnicodeEncodeError: 'ascii' codec can't encode character
u'\u201c' in position 22: ordinal not in range(128)
%关于该错误是怎么回事?当尝试在 stderr 上打印该字符串时,我们遇到了一个非 ASCII 字符——可能是那些弯引号之一。快速的 Web 搜索给出了这个可能的解决方案
sys.stderr.write(what.encode('ascii', 'replace') + '\n')它说,如果出现非 ASCII Unicode 字符,请将其替换为 ASCII 中的某些内容——一个等效项,或至少是可打印的东西。
将第 8 行替换为该行会产生此输出
% ./fix1.py TMP/content.xml depth=5: Turn all these depth=6: "straight" depth=5: quotes into ?nice? quotes %
因此,弯引号被替换为 ? 字符,这对于我们的调试输出来说很好。请注意,文本不一定都位于树中的同一深度。
文档的结构也可以通过将 content.xml 文件的完整文件名键入 Firefox 窗口(图 7)来查看。这对于显示数据很有用;然而,重点是改变它!
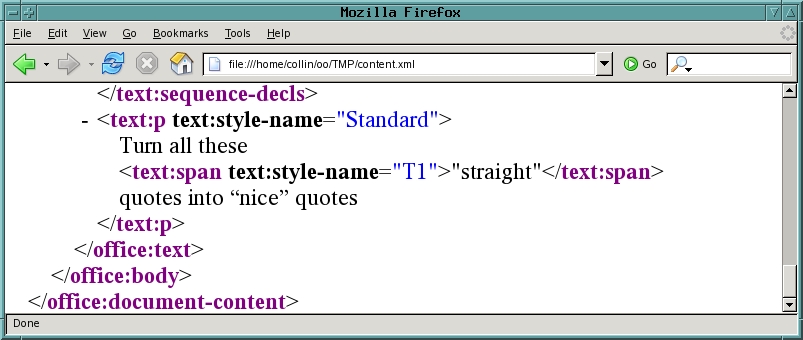
图 7. Firefox 更清晰地呈现 XML。
让我们采用 fix1.py 并进行简单的修改。每当出现两个连字符时,将其替换为 em dash。然后,当我们完成时,将 XML 写入 stdout——这正是 shell 脚本 (fixit.sh) 所期望的。
我们将通过给出其十六进制值来指定 em dash;要找到它,请在 OpenOffice.org Writer 的插入→特殊字符对话框中找到 em dash(图 8)。
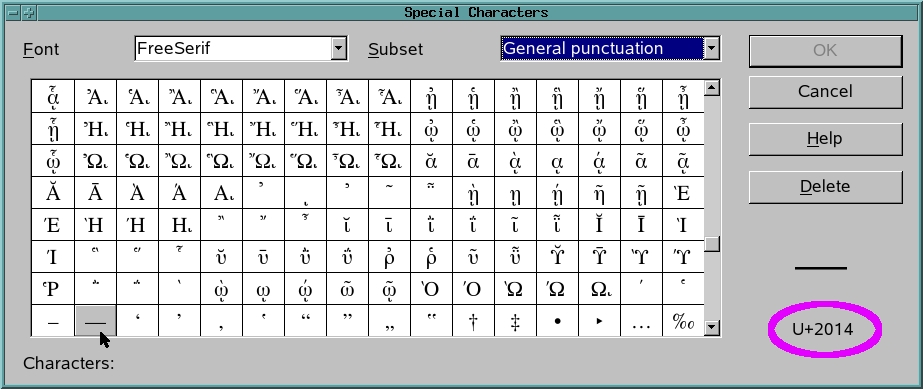
图 8. 选择和插入特殊字符
当我选择长破折号(em dash)时,其 Unicode 值出现在右下角,我在那里放了一个紫色椭圆;那是放入字符串中以代替双连字符的值。让我们将此脚本称为 fix2.py
#!/usr/bin/python -tt
import xml.dom.minidom
import sys
DEBUG = 1
def dprint(what):
if DEBUG == 0: return
sys.stderr.write(what.encode('ascii',
'replace') + '\n')
emDash=u'\u2014'
def fixdata(td, depth):
dprint("depth=%d: childNode: %s" %
(depth, td.data))
# OK, so '--' becomes em dash everywhere
td.data = td.data.replace('--', emDash)
def handle_xml_tree(aNode, depth):
if aNode.hasChildNodes():
for kid in aNode.childNodes:
handle_xml_tree(kid, depth+1)
else:
if 'data' in dir(aNode):
fixdata(aNode, depth)
def doit(argv):
doc = xml.dom.minidom.parse(argv[1])
handle_xml_tree(doc, 0)
sys.stdout.write(doc.toxml('utf-8'))
if __name__ == "__main__":
doit(sys.argv)请注意 Python 使替换字符串中的模式变得多么容易。最近 Python 版本中的字符串具有内置方法 replace,该方法导致一个子字符串被另一个子字符串替换
td.data = td.data.replace('--', emDash)让我们将 fix2.py 插入 fixit.sh 中,看看它的效果如何
% ln -sf fix2.py fixit.py % ./fixit.sh ex3.odt ex3-1.odt depth=5: childNode: The ?en? dash ? is too short depth=5: childNode: The ?em? dash ? which is longer ? is what we need. depth=5: childNode: And two hyphens -- ugly -- should be turned into ?em? dashes. depth=5: childNode: This line has "straight double quotes" depth=5: childNode: These 'single quotes' aren't pretty. % oowriter ex3-1.odt %
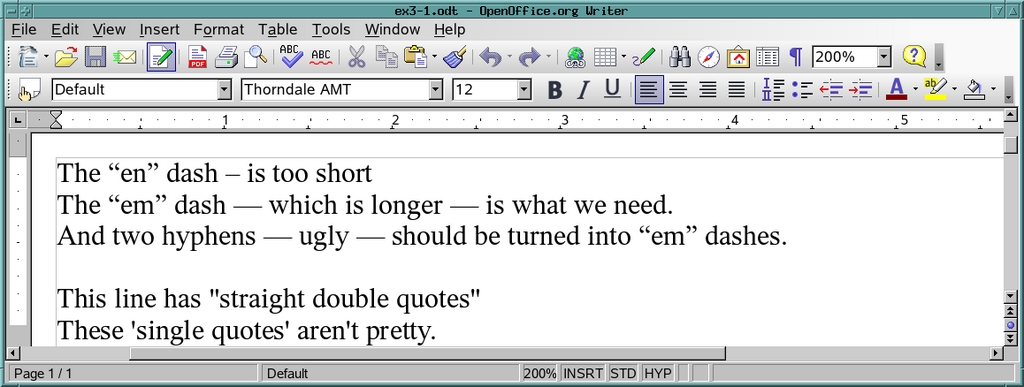
图 9. 这看起来像是 Python 的工作。
成功!现在是其余部分。除了双连字符之外,我们还想将 en dash 更改为 em dash。该语法与双连字符替换类似。
但是,用弯引号替换直引号更复杂,因为我们必须在起始双引号和结束双引号字符之间做出决定。如何判断?嗯,如果引号字符位于字符串的开头,并且后面有一个非空格字符,则它是左(或引号开头)弯引号。如果它前面有一个空格,后面有一个非空格,也是如此。
这是描述它的简单方法。我们可以像那样编写代码,或者我们可以简单地编写一个正则表达式。我查看了 Python 库文档第 4 章中标题为“re -- 正则表达式操作”的部分,最终提出了这个
sDpat = re.compile(r'(\A|(?<=\s))"(?=\S)', re.U)
让我从左到右解释一下。我们正在创建 sDpat,起始双引号或起始双引号模式的模式。我们通过调用 re 模块(用于正则表达式)中的方法 compile 来做到这一点。它分析模式一次并创建一个正则表达式对象。我们将使用 sDpat 来匹配应该变成漂亮的弯引号的起始直双引号。
现在,关于模式——模式包含一个双引号字符 ("),因此我们用单引号分隔它,'像这样'。此外,我们将传递一些转义符(例如 \A 和 \s)到 re.compile,因此让我们通过在其前面放置一个 r 使其成为原始字符串。
(给 Perl 用户的一点解释:在 Python 中,\ 转义符会被内插,除非在原始字符串中,无论是单引号还是双引号;分隔符不会像在 Perl 中那样影响内插。)
我们可以通过使用 Python 的 shell 来查看原始字符串的工作方式
>>> print 'normal string: \n is a newline' normal string: is a newline >>> print r'raw string: \n is not a newline' raw string: \n is not a newline >>>
那么,原始字符串中有什么?它由三个部分组成
引号字符之前的部分(\A|(?<=\s))。我们正在做的是匹配某些内容(在本例中为 '"'),但仅当它出现在字符串的开头或以空白字符开头时才匹配。\A 表示“匹配字符串的开头”,| 表示“或”,(?<=\s) 表示“如果紧接在空白(空格、制表符或换行符)之前则匹配,但不将该空白本身包含在匹配中”。外面的括号表示分组。
直双引号本身:"。这就是我们要匹配的内容。
'"' 之后的部分:(?=\S)。我们正在添加另一个条件——引号字符后跟一个非空白字符。
如果满足所有三个条件——即,如果那里有一个引号(条件 2),并且它要么在字符串的开头,要么以空白开头(条件 1),并且它后面跟着一些非空白字符(条件 3),我们想用一个起始双引号字符替换它。
除了模式之外,您还可以将标志传递给 re.compile。我们传递 re.U 以使某些转义符依赖于 Unicode 字符数据库。因为我们正在解析 Unicode 字符串,我认为我们需要它。
让我们将此脚本称为 fix3.py
#!/usr/bin/python -tt
import xml.dom.minidom
import sys
import re # new in fix3.py
DEBUG = 1
def dprint(what):
if DEBUG == 0: return
sys.stderr.write(what.encode('ascii',
'replace') + '\n')
emDash=u'\u2014'
enDash=u'\u2013' # new in fix3.py
sDquote=u'\u201c' # new in fix3.py
# sDpat: pattern for starting dbl quote, as
# "Go! <-- the quote there
# We look for it either at start (\A) or
# after a space (\s), and we want it to be
# followed by a non-space
sDpat = re.compile(r'(\A|(?<=\s))"(?=\S)', re.U) # new in fix3.py
def fixdata(td, depth):
dprint("depth=%d: childNode: %s" %
(depth, td.data))
# OK, so '--' becomes em dash everywhere
td.data = td.data.replace('--', emDash)
# Change 'en' dash to 'em' dash
td.data = td.data.replace(enDash , emDash) # new in fix3.py
# Make a nice starting curly-quote # new in fix3.py
td.data = sDpat.sub(sDquote, td.data) # new in fix3.py
def handle_xml_tree(aNode, depth):
if aNode.hasChildNodes():
for kid in aNode.childNodes:
handle_xml_tree(kid, depth+1)
else:
if 'data' in dir(aNode):
fixdata(aNode, depth)
def doit(argv):
doc = xml.dom.minidom.parse(argv[1])
handle_xml_tree(doc, 0)
sys.stdout.write(doc.toxml('utf-8'))
if __name__ == "__main__":
doit(sys.argv)
请注意,替换正则表达式的语法与子字符串替换的语法不同:我们使用正则表达式对象(在本例中为 sDpat)的 sub(替换)方法
td.data = sDpat.sub(sDquote, td.data)
在这里,我们采用 td.data,XML 树中此特定节点中的数据,查找由 sDpat 指定的正则表达式,并将匹配到的任何内容(适当上下文中的直 " 字符)替换为起始双引号 sDquote。
现在,如果我们尝试使用 fix3.py 作为底层程序的 fixit.sh
% ln -sf fix3.py fixit.py % ./fixit.sh ex3.odt ex3-2.odt depth=5: childNode: The ?en? dash ? is too short depth=5: childNode: The ?em? dash ? which is longer ? is what we need. depth=5: childNode: And two hyphens -- ugly -- should be turned into ?em? dashes. depth=5: childNode: This line has "straight double quotes" depth=5: childNode: These 'single quotes' aren't pretty. % oowriter ex3-2.odt %
OpenOffice.org Writer 显示了我们期望的内容。双连字符和 en dash 都变成了 em dash,并且起始双引号以正确的方向弯曲。
现在,这是其余部分。处理结束双引号的表达式是起始双引号的镜像。为了写入结束/闭合双引号,我们要求引号字符要么位于字符串的末尾 (\Z),要么后跟空格。同样,当我们进行替换时,我们只想替换引号本身,而不是空格。因此,结束双引号模式 (eDpat) 由以下给出
eDpat = re.compile(r'("\Z)|("(?=\s))', re.U)顺便说一句,我们编译所有这些模式是因为我们将在处理文档时一遍又一遍地使用它们。
为了处理单引号('像这样'),我们基本上可以做同样的事情,但有两个问题。首先,是收缩的问题。在处理双引号字符时,我们没有涵盖它两侧都被非空白包围的情况。对于单引号(或撇号),我们无法避免这种情况,因为存在诸如 can't 之类的单词。因此,尽管起始单引号模式可以匹配起始双引号模式,但另一个模式(在收缩中兼作撇号)具有更宽松的模式。这是我想出的
eSpat = re.compile(r"(?<=\S)'", re.U)
因为模式中有一个撇号,所以我们使用双引号字符分隔模式字符串。此表达式匹配单引号,但仅当紧接在非空白字符之前时才匹配。
代码未解决的第二个问题是以撇号开头的收缩,例如 'tis the season 或 stick 'em up。
脚本将前导撇号视为单引号短语的开头,并且单引号将朝错误的方向。这可能需要手动解决。
将所有这些放在一起,我们有 fix4.py
#!/usr/bin/python -tt
import xml.dom.minidom
import sys
import re # new in fix3.py
DEBUG = 1
def dprint(what):
if DEBUG == 0: return
sys.stderr.write(what.encode('ascii',
'replace') + '\n')
emDash=u'\u2014'
enDash=u'\u2013' # new in fix3.py
sDquote=u'\u201c' # new in fix3.py
eDquote=u'\u201d' # new in fix4.py
sSquote=u'\u2018' # new in fix4.py
eSquote=u'\u2019' # new in fix4.py
# sDpat: pattern for starting dbl quote, as
# "Go! <-- the quote there
# We look for it either at start (\A) or
# after a space (\s), and we want it to be
# followed by a non-space
sDpat = re.compile(r'(\A|(?<=\s))"(?=\S)', re.U) # new in fix3.py
eDpat = re.compile(r'("\Z)|("(?=\s))', re.U) # new in fix4.py
sSpat = re.compile(r"(\A|(?<=\s))'(?=\S)", re.U) # new in fix4.py
eSpat = re.compile(r"(?<=\S)'", re.U) # new in fix4.py
def fixdata(td, depth):
dprint("depth=%d: childNode: %s" %
(depth, td.data))
# OK, so '--' becomes em dash everywhere
td.data = td.data.replace('--', emDash)
# Change 'en' dash to 'em' dash
td.data = td.data.replace(enDash , emDash) # new in fix3.py
# Make a nice starting curly-quote # new in fix3.py
td.data = sDpat.sub(sDquote, td.data) # new in fix3.py
td.data = eDpat.sub(eDquote, td.data) # new in fix4.py
# Make nice curly single-quote characters
td.data = sSpat.sub(sSquote, td.data) # new in fix4.py
td.data = eSpat.sub(eSquote, td.data) # new in fix4.py
def handle_xml_tree(aNode, depth):
if aNode.hasChildNodes():
for kid in aNode.childNodes:
handle_xml_tree(kid, depth+1)
else:
if 'data' in dir(aNode):
fixdata(aNode, depth)
def doit(argv):
doc = xml.dom.minidom.parse(argv[1])
handle_xml_tree(doc, 0)
sys.stdout.write(doc.toxml('utf-8'))
if __name__ == "__main__":
doit(sys.argv)
让我们在我们的示例中尝试一下
% ln -sf fix4.py fixit.py % ./fixit.sh ex3.odt ex3-4.odt depth=5: childNode: The ?en? dash ? is too short depth=5: childNode: The ?em? dash ? which is longer ? is what we need. depth=5: childNode: And two hyphens -- ugly -- should be turned into ?em? dashes. depth=5: childNode: This line has "straight double quotes" depth=5: childNode: These 'single quotes' aren't pretty. % oowriter ex3-4.odt
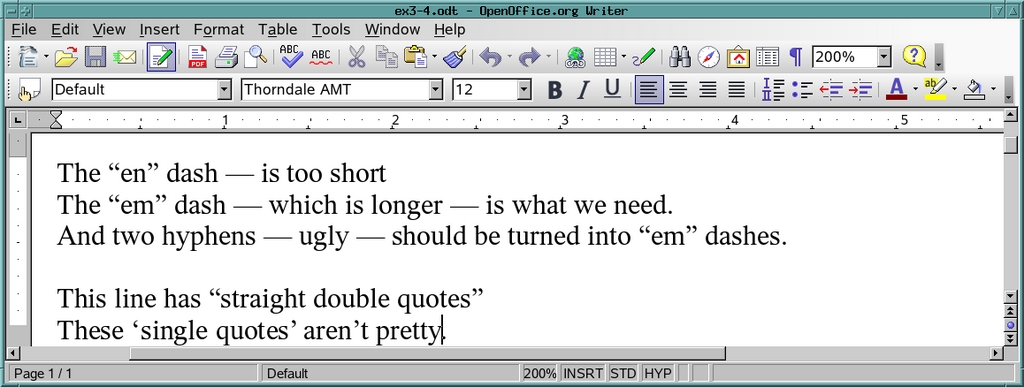
图 10. Python 字符串处理获得结果。
让我们回顾一下我们在这里所做的事情
编写了脚本来解压缩和重新打包 ODF 文件。
了解了如何使用 Python 来理解 ODF 文件的结构。
编写了一个 Python 程序,使用正则表达式和内置字符串方法对 OpenOffice.org Writer 文件执行有用的转换。
我希望这个介绍对您有所帮助,但这只是 Python/XML 如何与 ODF 文件一起工作的开始。
例如,我有一个 OpenDocument 电子表格,我想将所有具有黄色背景的单元格的值加起来,Python/XML 允许我这样做。我也需要从电子表格的一列中获取所有电子邮件地址,但斜体或删除线类型中的电子邮件地址除外。我认为 OpenOffice.org 不会让我这样做,但 Python/XML 会。
资源
当前 Python 库参考:docs.python.org/lib
旧版本 (pre-2.5) 的 Python 文档:www.python.org/doc/versions
Dave Taylor 在 Linux Journal 中的 Work the Shell 专栏为 shell 脚本编写提供了出色的介绍。
“为什么不选择 Python?”(老 C 程序员拖着自己进入 1990 年代后期):linuxjournal.com/article/8794, linuxjournal.com/article/8729, linuxjournal.com/article/8858 和 linuxjournal.com/article/8859
Collin Park 自 1976 年以来一直是一名计算机工程师,目前在 Network Appliance 工作。他在家里的四台计算机上运行 Linux,他与妻子和两个十几岁的女儿共享这些计算机。
