
Ajax 增强的 Web 版以太网分析器
在过去的六个月左右,我一直在玩 Ruby。我将此从我选择的编程语言 Perl 的中断归咎于 2006 年 7 月刊的 Linux Journal,因为那一期让我看到了使用 Ruby 作为严肃工具的可能性。我仍然热爱、使用和教授 Perl,但我花在 Ruby 编程上的时间越来越多。
在学习任何新的编程技术时,我都遵循相同的流程:我找到一本好书并通读它,然后开始使用该语言构建一些我喜欢用 Perl 构建的东西。找到书很容易。《Programming Ruby》第二版,作者 Dave Thomas(被称为 The PickAxe),对于任何编程语言来说,都是你能找到的最好的入门书,不仅仅是 Ruby。一旦我完成了 The PickAxe——并在过程中创建了一个 Ruby 教程(见资源)——我就渴望编写一些真正的代码。我从一种我喜欢用 Perl 构建的工具开始:自定义以太网分析器。
在这一点上,可能有很多读者会对自己说:既然 tcpdump 和 Ethereal/Wireshark 已经存在,为什么还要费心创建以太网分析器呢?这些解决方案都是优秀的工具——我经常使用——但是,我经常希望构建一些涉及额外处理以及以太网数据包的捕获和解码的东西,而这种自定义总是需要求助于自定义代码。幸运的是,事实证明,tcpdump 和 Ethereal/Wireshark 以及非常流行的 Snort IDS 背后的技术都可以作为一个库使用,并且存在许多语言绑定。数据包捕获库,称为 libpcap,可从 tcpdump 的同一个项目获得,并且可以轻松地从 Web 下载。事实上,它很可能包含在您的发行版的软件包管理系统中;如果您运行的是最新版本的 Ubuntu(就像我一样),情况就是这样。显然,有魄力的程序员可以使用 C 和 libpcap,但是——说实话——当需要更敏捷的东西时,在 C 抽象级别工作实在太浪费时间了。值得庆幸的是,Perl 提供了一组与 libpcap 配合使用的出色模块,我在我的第一本书中用六分之一的篇幅详细讨论了 Perl 技术。令我欣喜的是,经过一番挖掘,我还找到了一组与 libpcap 接口的 Ruby 类(见资源)。
为了真正测试 libpcap 技术,我决定使用 Ruby 重新开发几年前我用 Perl 创建的一个工具,我曾在 The Perl Review 的页面中写过关于它的文章(见资源)。我的 Perl 工具名为 wdw(who's doing what 的缩写),它分析对 LAN 的 DNS 服务发出的请求,并报告客户端正在请求 DNS 解析的站点名称。在不到 100 行 Perl 代码中,我就编写了一个功能齐全且有用的 DNS 以太网分析器。我想知道使用 Ruby 会有怎样的比较。
现在,我展示了大约 20 行 Ruby 代码,我用它重新创建了 wdw(完整程序见列表 1)。不要将我的数字解释为任何试图声称 Ruby 可以在五分之一 Perl 代码行数内完成 Perl 所做的事情的尝试。它不能。但重要的是要注意,Ruby 的 libpcap 接口比 Perl 提供的接口抽象得多,因此 Ruby 在一次调用中完成的工作比 Perl 多,但这更多与每种语言的 libpcap 绑定的创建者所做的选择有关,而不是任何基本的语言差异。
列表 1. dns-watcher.rb 源代码
#! /usr/bin/ruby -w
require 'pcap'
require 'net/dns/packet'
dev = Pcap.lookupdev
capture = Pcap::Capture.open_live( dev, 1500 )
capture.setfilter( 'udp port 53' )
NUMPACKETS = 50
puts "#{Time.now} - BEGIN run."
capture.loop( NUMPACKETS ) do |packet|
dns_data = Net::DNS::Packet.parse(packet.udp_data)
dns_header = dns_data.header
if dns_header.query? then
print "Device #{packet.ip_src} "
print "(to #{packet.ip_dst}) looking for "
question = dns_data.question
question.inspect =~ /^\[(.+)\s+IN/
puts $1
STDOUT.flush
end
end
capture.close
puts "#{Time.now} - END run."在执行此代码之前,请下载并安装 Ruby 的 libpcap 库。访问 Ruby libpcap 网站(见资源),并获取 tarball。或者,如果您使用的是 Ubuntu,请使用 Synaptic Package Manager 下载并安装 libpcap-ruby1.8 软件包。如果发行版软件包不可用,请以通常的方式安装 tarball。
您还需要一个 Ruby 库来解码 DNS 消息。幸运的是,Marco Ceresa 一直在努力将 Perl 出色的 Net::DNS 模块移植到 Ruby,并且他最近在 RubyForge 上发布了他的 alpha 代码,所以您也需要它(见资源)。尽管是 alpha 版,但 Marco 的代码非常可用,并且 Marco 擅长在任何问题引起他的注意后快速发布修补后的库。下载后,使用以下命令将 Marco 的 Net::DNS 库安装到您的 Ruby 环境中
tar zxvf net-dns-0.3.tgz cd net-dns-0.3 sudo ruby setup.rb
我的 Ruby DNS 分析器名为 dns-watcher.rb,它首先引入所需的 Ruby 库:一个用于使用 libpcap,另一个用于解码 DNS 消息
#! /usr/bin/ruby -w require 'pcap' require 'net/dns/packet'
我可以告诉我的程序使用哪个网络连接来捕获流量,或者我可以让 libpcap-ruby 为我解决这个问题。以下代码行让 Ruby 完成这项工作
dev = Pcap.lookupdev
在识别设备(并存储在 dev 中)后,我们需要启用以太网的混杂模式,这对于捕获在我们的 LAN 上传输的所有流量至关重要。以下是执行此操作的 Ruby 代码
capture = Pcap::Capture.open_live( dev, 1500 )
open_live 调用接受两个参数:要使用的设备和一个值,该值指示要处理的每个捕获数据包的数量。将后者设置为 1500 可确保每次发生捕获时都从网络中抓取整个以太网数据包。只有当程序有能力打开混杂模式时,对 open_live 的调用才会成功——也就是说,它必须以 root 用户身份或使用 sudo 运行。在识别出网卡并准备好捕获流量后,下一行代码应用数据包捕获过滤器
capture.setfilter( 'udp port 53' )
我要求 libpcap 库仅关注捕获与过滤器匹配的数据包,在本例中,过滤器是包含 UDP 数据报且源或目标协议端口值为 53 的以太网数据包。正如所有网络专家所知,53 是为 DNS 系统保留的协议端口。所有其他流量都将被忽略。setfilter 方法的酷之处在于,它可以接受 tcpdump 技术理解的任何过滤器规范。有动力的读者可以从 tcpdump 手册页中了解有关编写过滤器的更多信息。
然后定义一个常量来设置我感兴趣的捕获数据包的数量,然后将带有时间戳的消息发送到 STDOUT,以指示分析器已启动并正在运行
NUMPACKETS = 50
puts "#{Time.now} - BEGIN run."libpcap-ruby 库包含 loop 迭代器,它为数据包捕获技术提供了方便的 API,并且它接受一个参数,即要捕获的数据包数量。每个捕获的数据包都作为命名参数传递到迭代器的正文中,我在代码中将其称为 packet
capture.loop( NUMPACKETS ) do |packet|
在迭代器中,首要任务是将捕获的数据包解码为 DNS 消息。Marco 的 Net::DNS 库中的 Packet.parse 方法正是这样做的
dns_data = Net::DNS::Packet.parse( packet.udp_data )
解码 DNS 消息后,我们可以通过调用 header 方法来提取 DNS 标头信息
dns_header = dns_data.header
对于我的目的,我只对发送到 DNS 服务器的查询感兴趣,因此我可以忽略所有其他内容,方法是检查 query? 方法是否返回 true 或 false
if dns_header.query? then
在此 if 语句的主体中,我打印出 IP 源地址和目标地址,然后从查询中提取 IP 名称,该名称通过调用 dns_data.question 方法返回。请注意使用正则表达式从查询中提取 IP 名称
print "Device #{packet.ip_src}
↪(to #{packet.ip_dst}) looking for "
question = dns_data.question
question.inspect =~ /^\[(.+)\s+IN/
puts $1
STDOUT.flush程序代码以所需的 end 块终止符结束,然后关闭捕获对象,并将另一个时间戳发送到 STDOUT
end
end
capture.close
puts "#{Time.now} - END run."现在是时候让 dns-watcher.rb 运行起来了
sudo ruby dns-watcher.rb
图 1 显示了其中一个调用的输出。请注意,输出行数不是预期的 50 行。请记住,程序的 if 语句检查捕获的 DNS 消息是否是发送到服务器的查询,并且仅当它是查询时才处理该消息。所有其他 DNS 消息都会被程序忽略,即使它们仍然计入处理的 DNS 数据包的总数。
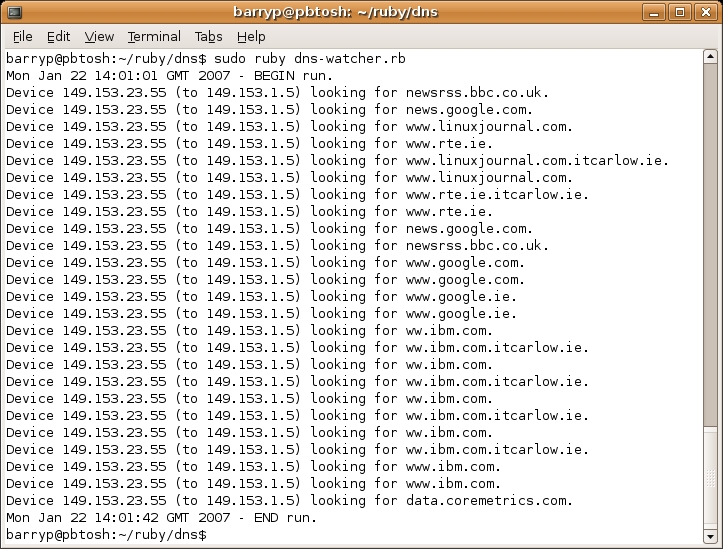
图 1. 从命令行运行 dns-watcher.rb
要运行分析器更长的时间,请将 NUMPACKETS 常量更改为大于 50 的某个值。如图 1 所示,分析器仅用了 40 多秒就处理了 50 条 DNS 消息(在我的 PC 上,在我的网段上——您的结果可能会有所不同)。假设将常量值更改为 250 之类的数值可能会导致几分钟的处理时间,这是合理的。显然,将输出管道传输到磁盘文件或 less 可以让您在闲暇时查看任何结果。
在我的小分析器启动并运行后,我开始思考,如果我能为其提供一个基于 Web 的界面,那就太酷了。正如每个 Web 开发人员都知道的那样,长时间运行的、服务器绑定的进程和 Web 往往不能很好地协同工作,因为没有什么比在浏览器中长时间等待此类进程执行更糟糕的了。多年来,已经提出了许多针对此问题的解决方案,其中包括采用重定向、cookie、会话等技术的技术。尽管这些技术有效,但我一直认为它们相当笨拙,并且我一直在寻找更优雅的东西。在刚刚完成 Reuven M. Lerner 关于 Ajax 编程的优秀 LJ 系列文章 [参见 LJ 2006 年 10 月、11 月和 12 月刊] 之后,我想知道我是否可以将我的分析器与启用 Ajax 的 Web 页面结合起来,并在生成分析器输出时立即使用该输出更新 Web 页面的一部分。
列表 2. 启动分析器的简单 HTML Web 页面
<html>
<head>
<title>Start a new DNS Analysis</title>
</head>
<body>
Click to
<a href="/cgi-bin/startwatch.cgi">start</a>.
</body>
</html>
我的策略足够简单。我提供一个启动器 Web 页面,该页面在 Web 服务器上以后台 CGI 进程启动网络分析,然后重定向到另一个 Web 页面,该页面在 HTML 文本区域小部件中显示结果,并使用来自网络分析的结果更新文本区域。列表 2 中的小型 HTML Web 页面使事情开始运转。此 Web 页面真正做的只是提供一个链接,单击该链接时,会调用 startwatch.cgi 脚本。后者本身是简单的 CGI,编写为 bash 脚本。以下是整个脚本
#! /bin/sh
echo "Content-type: text/html"
echo ""
sudo /usr/bin/ruby /var/www/watcher/dns-watcher.rb \
> /var/www/watcher/dns-watcher.log &
echo '<html><head>'
echo '<title>Fetching results ... </title>'
echo '<meta http-equiv="Refresh" content="1;'
echo 'URL=/watcher.html">'
echo '</head><body>Fetching results ... </body>'
echo '<html>'
脚本的关键行是调用 Ruby 并将 dns-watcher.rb 程序馈送到解释器的行,并将后者的标准输出重定向到名为 dns-watcher.log 的文件。请注意此命令末尾的尾随 & 符号,它将分析器作为后台进程运行。脚本继续向浏览器发送一个类似 HTML 的 Web 页面,该页面重定向到分析结果页面,名为 watcher.html,如列表 3 所示。
列表 3. 网络分析结果 Web 页面
<html>
<head>
<title>Web-based DNS Watcher</title>
<script language=javascript src="/js/dns-watcher.js">
</script>
</head>
<body>
<h1>Web-based DNS Watcher</h1>
Here are the results of your DNS analysis:
<p>
<textarea name="watcherarea" cols="100"
rows="20" id="watcherarea">
Waiting for results ...
</textarea>
<script>
startWatcher();
</script>
<p>Start
<a href="/startwatcher.html">another analysis</a>
(which stops this one).
</body>
</html>
结果 Web 页面在其标头部分加载了一些 JavaScript 代码 (dns-watcher.js),然后创建一个简单的 HTML 结果页面,其中包含一个最初为空的名为 watcherarea 的文本区域小部件。一旦浏览器加载结果 Web 页面的正文部分,就会调用 startWatcher JavaScript 方法。
列表 4. 启用 Ajax 的 JavaScript 代码
var capturing = false;
var matchEnd = new RegExp( "END run" );
var r = new getXMLHttpRequest();
function startWatcher() {
setInterval( "updateCaptureData()", 1500 );
capturing = true;
}
function getXMLHttpRequest() {
try {
return new ActiveXObject("Msxml2.XMLHTTP");}
catch(e) {};
try {
return new ActiveXObject("Microsoft.XMLHTTP");}
catch(e) {}
try {
return new XMLHttpRequest(); }
catch(e) {};
return null;
}
function updateCaptureData() {
if (capturing) {
r.open( "GET",
"/cgi-bin/get_watcher_data.cgi",
false );
r.send( null );
displayCaptureData();
}
}
function displayCaptureData() {
var te = document.getElementById("watcherarea");
if ( r.readyState == 4 ) {
if ( r.status == 200 ) {
te.value = r.responseText;
te.scrollTop = te.scrollHeight;
if ( matchEnd.test( te.value ) ) {
capturing = false;
}
}
else
{
te.value =
"Web-based DNS Analysis unavailable.";
}
}
}列表 4 包含 dns-watcher.js 代码。Reuven 的优秀 Ajax 文章已经涵盖了此处发生的大部分内容。代码首先声明一些全局变量,这些变量在代码的其余部分中使用
var capturing = false; var matchEnd = new RegExp( "END run" ); var r = new getXMLHttpRequest();
capturing 布尔值在分析器捕获流量时设置为 true,否则设置为 false。创建一个正则表达式以匹配包含单词“END run”的字符串。最后,通过调用 getXMLHttpRequest 方法创建一个 Ajax 请求对象,该方法直接取自 Reuven 的示例。
startWatcher 方法通过每 1.5 秒调用一次 updateCaptureData 方法并将 capturing 设置为 true 来开始繁重的工作
function startWatcher() {
setInterval( "updateCaptureData()", 1500 );
capturing = true;
}Ajax 调用发生在 updateCaptureData 方法中,其中请求对象用于执行另一个 CGI 脚本,该脚本访问 dns-watcher.log 磁盘文件并返回其内容。(列表 5 包含 get_watcher_data.cgi 脚本,该脚本是用 Ruby 编写的。)一旦 CGI 脚本在 Web 服务器上被调用,就会调用 displayCapture
function updateCaptureData() {
if (capturing) {
r.open( "GET",
"/cgi-bin/get_watcher_data.cgi",
false );
r.send( null );
displayCaptureData();
}
}列表 5. 用于检索捕获数据的简单 CGI
#! /usr/bin/ruby -w
puts "Content-type: text/plain\n\n"
IO.foreach("/var/www/watcher/dns-watcher.log") do |l|
puts l
enddisplayCaptureData 方法改编自 Reuven 的代码,并处理 Ajax 调用的结果,这些结果可从请求对象获得。这些结果用于更新结果 Web 页面中的 watcherarea 文本区域小部件
te.value = r.responseText;
请注意使用以下 JavaScript 行将文本区域滚动到结果底部
te.scrollTop = te.scrollHeight;
最后,请注意 displayCaptureData 方法在与 Ajax 请求中的数据匹配的正则表达式的行出现后立即将 capturing 布尔值设置为 false(请参见图 1 和图 2,以使自己确信这实际上在网络捕获结束时匹配)
if ( matchEnd.test( te.value ) ) {
capturing = false;
}此检查非常重要。如果没有它,即使在分析器完成并且不再生成任何数据之后,Web 浏览器也会每 1.5 秒继续向服务器发送 Ajax 请求,只要 watcher.html 结果页面显示在浏览器中即可。有了代码中的此检查,Ajax 行为将被关闭,从而减少 Web 服务器上的负载(并防止 Apache2 访问日志快速增长)。
为了部署我的解决方案,我创建了一个简单的 shell 脚本,将所需的组件复制到 Web 服务器(它是 Ubuntu 上的 Apache2)上的相应目录位置
sudo cp watcher.html /var/www/ sudo cp startwatcher.html /var/www/ sudo cp dns-watcher.js /var/www/js/ sudo cp dns-watcher.rb /var/www/watcher/ sudo cp get_watcher_data.cgi /usr/lib/cgi-bin/ sudo cp startwatch.cgi /usr/lib/cgi-bin/
这些目录位置可能与您的 Apache2 安装的位置不匹配,因此请进行相应调整。您可能还需要创建 js 和 watcher 目录。当然,请确保 CGI 具有其可执行位集。
最后一个难题是 dns-watcher.rb 程序需要以 root 权限执行,才能将 Web 服务器的 NIC 切换到混杂模式。正如预期的那样,Apache2 默认情况下不会以 root 权限执行 CGI 脚本,这是有充分理由的。为了使我的基于 Web 的分析器工作,我在我的 /etc/sudoers 文件中添加了以下行
%www-data ALL=(root) NOPASSWD: /usr/bin/ruby
这允许 www-data 用户(执行 Apache2 的用户)以 root 权限执行 Ruby,因为正是 Ruby 解释器代表 Apache2 执行 dns-watcher.rb 代码。由于引发的安全问题,这种情况可能是您无法接受的——我很想知道是否有任何读者有解决方案,可以让我更安全地以 root 权限执行分析器。
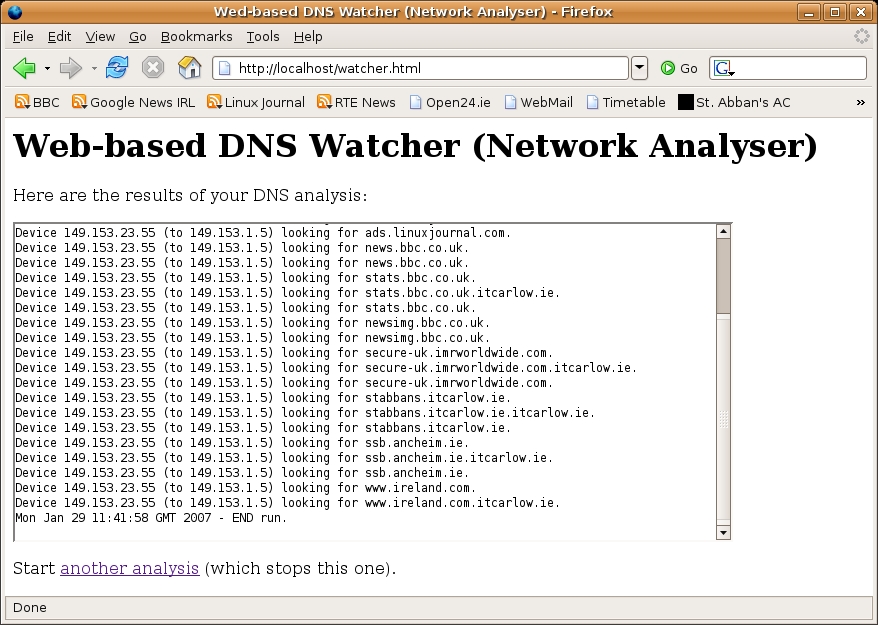
图 2. 从 Web 运行 dns-watcher.rb
图 2 显示了基于 Web 的网络分析的结果。长时间运行的、服务器绑定的进程由 Web 服务器启动,在后台运行,并且——随着结果的生成——任何和所有输出都会出现在基于 Web 的前端中。感谢 Ajax,用户的体验与同一程序的命令行执行非常相似——一旦数据准备就绪,就会立即显示出来。将我的解决方案应用于其他用途并不困难;所需的只是一个机制,用于将一些长时间运行的、服务器绑定的进程的输出重定向到一个文件,然后通过 CGI 脚本访问该文件的内容,该 CGI 脚本作为单个 Ajax 调用的结果执行。正如我希望我已经证明的那样,Ruby 和 Ajax 为这种特定的 Web 开发模式提供了一个简洁的解决方案。
资源
Paul 的 Ruby 教程:glasnost.itcarlow.ie/~barryp/ruby-tut.html
tcpdump/libpcap:www.tcpdump.org
Ruby 的 libpcap 库:raa.ruby-lang.org/project/pcap
Ruby Net::DNS 页面在 RubyForge 上:rubyforge.org/projects/net-dns
Ethereal:www.ethereal.com
Wireshark:www.wireshark.org
“who is doing what?”Perl 脚本:www.theperlreview.com/Issues/v0i6.shtml
Paul Barry (paul.barry@itcarlow.ie) 在爱尔兰卡洛理工学院任教。在 glasnost.itcarlow.ie/~barryp 了解更多关于他所做的事情。

