
面向商务人士的 Linux - Atlas:掀起搜索新世界
这里有一段历史。我们早在 2000 年 9 月号的 Linux Journal 上就报道过 Jabber,那是七年多以前。当时,Jabber 的发明者 Jeremie Miller 告诉我,至少还需要五年时间,Jabber 协议(后来被称为 XMPP,并于 2003 年获得 IETF 批准)才能确立其事实标准地位。他是对的。
多年来我们一直保持联系,Jeremie 的兴趣也从消息传递和在线状态扩展到其他主题,尤其是搜索。我猜大概是两年前,他开始质疑搜索是否需要成为单一来源的东西(例如,Google 或 Yahoo)。那时他也开始谈论他的新搜索项目,名为 Atlas。每当我问他在做什么时,他都会回答:“Atlas”。
我完全赞成,因为我从一开始就觉得搜索引擎本质上是用来克服 Web 本身目录缺陷的笨拙方法。我也认为,尽管在 Web 上每个 URL 中第一个单斜杠右侧的所有内容的混乱性质中可以找到好处,但仅仅为了找到东西,就依赖于大规模商业广告驱动的搜索引擎(及其机器人和爬虫程序以及专有的权重算法,在成千上万台服务器中存储的不断更新的索引中费力地工作)在本质上是错误的。而且,尽管我同意 David Weinberger 的观点,即万物皆可归类(他的优秀新书的书名),但我不喜欢仅仅依赖 Google、Yahoo 或 MSN(通常只是 Google)来告诉我搜索某些内容时我的意思是什么。没有什么比意义更重要,我不喜欢看到意义由 Jeremie 所说的“文本框独裁”来提供。在 2007 年 5 月 28 日的博客文章中,他问道
为什么在如此先进的文明中,我们已经沦为知识农民,如此容易被我们 Goovernor 的黑魔法所安抚?难道只有我一个人想知道,为什么这些商业盒子拥有如此重要的社会功能:一切事物的意义是什么?
他说,答案是
开放开放开放!开源、开放分布式网格、开放算法、开放排名、开放的人们合作提供资源的網絡。搜索的未来在于基于意义经济的开放合作(和竞争)——创造意义、交换意义、服务意义。
我的愿景始于一个开放协议,允许独立的搜索功能网络(爬取、索引、排名、服务等)进行对等互操作。这些网络之间的所有关系始终完全透明且公开。网络之间交换知识,每个网络都为信息添加新的意义,每个网络都对其参与者和同行的声誉负责。这是意义经济的基石。
现在,明天有了我们可以共同构建的意义。
Jeremie 并不是唯一关注开放搜索的人。维基百科的主要推动者 Jimmy Wales 在去年 12 月引起了人们的注意,当时他说,“我想创建一个完全透明、开源、自由许可的搜索引擎”——作为维基百科的社区发展伙伴 Wikia.org 的一部分。在 2006 年 12 月 29 日的采访 (www.wired.com/techbiz/it/news/2006/12/72376?currentPage=2) 中,Wired 向他询问了具体细节。Jimmy 的回答是,“我们不知道。目前这真的是非常开放的。这真的取决于社区,我怀疑不会有一个一刀切的答案。这将取决于主题和正在进行的搜索类型。”随后的采访也同样是推测性和开放式的。
然后,在 2007 年 5 月 1 日,有消息称 Jeremie 加入了 Wikia 项目。在准备好的声明 (news.com.com/2100-1032_3-6180379.html) 中,Jimmy Wales 说,“Jeremie 是一位杰出的思想家,是一位天然的合适人选,可以帮助彻底改变搜索世界……我相信互联网搜索目前已经崩溃,解决它的方法是建立一个社区,其使命是开发一个开放且完全透明的搜索平台。”
Atlas 在 2007 年 7 月 5 日发布到列表的帖子中公开 (lists.wikia.com/pipermail/atlas-l/2007-July/000000.html)。在该帖子中,Jeremie 说他的“宏大愿景”是“使搜索成为互联网基础设施的一部分。以 Atlas 作为开放协议为基础,搜索可以成为一个完全分布式和可互操作的全球社区。所有参与者都可以公开地、在他们认为可以为网络增加价值的任何角色中进行互动。”
至于架构,他提供了以下内容
Atlas 中有三个主要角色
工厂 (Factory)——对内容负责。
收集器 (Collector)——对关键词负责。
代理 (Broker)——对搜索者负责。
这些角色中的每一个都必须与其他角色交互才能完成任何搜索请求。任何两个角色都可以由单个实体执行(而如果所有三个角色都由一个实体执行,则结果将是传统的、单体式搜索引擎)。
工厂 (Factory) 类似于当今搜索引擎中的爬虫程序。Atlas 工厂 (Factory) 必须尽可能智能地获取和处理内容,执行分析(例如自然语言处理)并将其规范化为不同的单元。工厂 (Factory) 根据他们认为谁最能利用其高度精炼和处理后的输出,与一个或多个收集器 (Collector) 共享其输出。
收集器 (Collector) 吸收并索引来自一个或多个工厂 (Factory) 的输出,其主要目标是:排名。Atlas 收集器 (Collector) 必须提供最智能的排名和关系分析。收集器 (Collector) 必须竞争工厂 (Factory) 的输出,并竞争为代理 (Broker) 提供最佳排名质量。
代理 (Broker) 必须为搜索者提供最佳的搜索结果。它通过组合来自收集器 (Collector) 的各种排名结果,以及从原始工厂 (Factory) 检索内容来实现这一点。最后一步,代理 (Broker) 与工厂 (Factory) 互动,对于维护平衡的生态系统至关重要。所有工厂 (Factory) 都必须了解并批准其结果的使用方式和使用者。
声誉和奖励在所有各方(工厂-收集器、收集器-代理和代理-工厂)之间是双向的。每个实体可以选择基于原则(免费、公共领域)、署名(结果由...提供)或商业(作为付费服务)进行互动。Atlas 协议纯粹是一个促进者,不限制任何实体之间关系的形成方式。在考虑这些不同实体的动机时,基于免费的网络可能更倾向于专业化,商业网络将在质量上竞争,而基于署名的网络将在两个方向上都成熟。
这种简单而强大的角色、责任和关系划分将为互联网搜索基础设施带来分布式的经济基础。线路协议和这些实体之间交互的进一步定义正在公开演进;欢迎任何有兴趣的人加入讨论,并在未来几周内在 lists.wikia.com/mailman/listinfo/atlas-l 上查看初步提案。
作为一种挑战,Jeremie 提出了一个总结性的挑战,“没有人能击败 Google,但所有人都能。”
随之而来的是激烈的讨论,一个快速增长的开发者社区开始参与 Jeremie 所谓的“现在公开构建它的脏活累活”。当这项工作开始时,我问他是否可以将我们的一些对话转移到Linux Journal 这里。他说当然,所以它来了。
DS:单体和多体之间总是存在这种拉锯战。互联网作为巨型零(终点世界)的讽刺之处在于,它是完全多体的——或者想要成为多体的。将未来的多体协议集中到单体服务中是它开始的一种方式。但最终状态是多体的。
JM:我同意,这是不可避免的。最终是互联网本身的本质要求它这样做,但 Google 正在努力尽可能长时间地保持单体……这很好,当他们看到 Atlas 提供价值时,他们会拥抱它。
DS:在您的公告 [上面] 中,我看到了一个基于署名信用的经济系统的种子——在这个系统中,我们可能会获得中介费,或者类似的东西,因为为提供的服务赋予了价值。
JM:是的,基于署名的模型。绝对需要中间人参与交易。Atlas 不流通资金,但它流通信息并提供框架。广告也是如此。实际上,情境广告非常有用。我在使用 Google 搜索时将它们作为一种工具来依赖。事实上,这种模型是最好的打击网络垃圾邮件的形式。
系统如何工作,以及谁参与信息流是完全透明的,因此三个角色——工厂 (Factory)、收集器 (Collector) 和代理 (Broker)——都参与提供搜索结果。代理 (Broker) 代表搜索者工作。他们与合适的收集器 (Collector)(复数)建立关系,并执行查询——组装他们从收集器 (Collector) 返回的所有相关的“Knugget”,根据他们想要的任何指标对其进行估值,包括与仅提供商业结果的“赞助”收集器 (Collector)、任何区域领域的“本地”收集器 (Collector) 等进行对话。
当任何人都可以成为代理 (Broker) 时,竞争非常激烈,除了关系之外几乎没有成本。因此,收集器 (Collector) 只有一个工作,提供相关的结果,并且必须与任何其他人竞争才能做到这一点。而且,它可以根据任何算法、基于人类声誉的或两者的组合来判断相关性。
DS:生产端的开源一直是一个精英管理制度。在我看来,Atlas 的等同于“给我看代码”的是“给我看结果”。或者至少,“给我看相关性”。不是吗?
JM:工厂 (Factory) 正在管理对精炼内容的商品访问,完成规范化 Web 的所有工作。搜索结果只是优点:谁拥有最好的。而代理 (Broker) 访问许多来源,许多收集器 (Collector)(可以有很多)以不同的形式获得许多优点。因此,foxmarks 拥有一个很棒的深度链接数据库,这对人们非常重要。这样,Mitch 可以提供高质量的结果,但仅适用于某些类别的查询。维基百科可以为另一类查询提供高相关性——本地黄页式系统可以,社交网络对于人员查询也可以。
DS:我从中看到了对知识滚雪球本质的尊重,无论是对个人还是对群体。作为人类就是增长一个人所知道的。权威是我们授予某些其他人为我们所知贡献并在这个过程中改变我们的权利。知道更多让我变得不同。正如在其他地方所说,“我们都是彼此的作者”。
JM:是的,Atlas 的基本单元是“Knugget”,本质上是知识块,一个搜索结果。工厂 (Factory) 根据其对内容的了解增加价值;收集器 (Collector) 根据其对关键词和排名 Knugget 的了解增加价值;代理 (Broker) 根据其了解的收集器 (Collector) 以及他们在总体上提供的价值增加价值。
DS:维基百科在增长自身相关性方面是一个有趣的例子。我一直在关注广播电台和网络广播公司。维基百科总体上是一个很棒的信息来源,但远非完整。而且,它需要一种比仅仅依靠狭隘的主题痴迷者来掌握当前叙事更好的保持完整性的方法。提供更好的 Knugget 的搜索结果应该是一个好东西,这些 Knugget 会变成更好的维基百科条目,不是吗?
JM:是的。
DS:Knugget 是“某人想要知道的东西”吗?我喜欢这个词。如果它是随时间可能变化的关键词组合呢?
JM:Knugget 是我定义的上下文的一个单元。它可能是一个标题和一个链接;它可能是一个句子,说明关于名词的内容;它可能是一行来自事物表。它是人类定义的,因此,本质上非常模糊。它是“人类会识别并在脱离任何其他上下文的情况下理解的东西,除了它内部包含的东西?” Web 是人类的,而不是机器的,Atlas 反映了这一点。
DS:我喜欢情境性。珠穆朗玛峰峰顶可以是海拔、登山者总数、一个事实(例如,它是海相石灰岩)。
JM:是的。Atlas 的本质是要求工厂 (Factory) 生产最好的 Knugget,工厂 (Factory) “理解”内容的能力尽可能强。它是一个首先奖励人类理解和价值的模型。所有衍生知识都建立在这个基础之上,我们可以减少所有这些膨胀的 DB/schema 灾难,这些灾难都首先服务于机器。Atlas 的工作方式与互联网首先服务于人,其次是服务器/数据中心——以及 Web 内容首先服务于人,其次是软件的方式相同。作为互联网基础设施的搜索必须首先服务于人。
DS:是的。我认为这里存在静态(传统 Google)与动态(人类、现在、发展中)的区别。请允许我稍微引用一下自己的话:“至于随着 Knugget 的产生而产生的动态馈送,任何内容提供商都可以通过将这些 Knugget 的馈送生成到他们信任的收集器 (Collector) 中来获得最大价值,搜索结果可以立即获得奖励,搜索者可以立即找到突发新闻文章。”
我猜,只要参与其中,就会成为 Atlas 代理 (Broker)。
JM:只需搜索,并知道向谁索要结果。
DS:您想如何播种这个东西?实际使用首先从哪里开始?
JM:Atlas 代理 (Broker) 应该存在于我的 IM 客户端中,利用所有这些出色的上下文,在本地搜索我的 IM 历史记录,并从我想要的任何内容存储中提供最佳相关搜索结果。
DS:谁是代理 (Broker)?
JM:代理 (Broker) 是人。代理 (Broker) 只是一个服务,它使用尽可能多的上下文,就像您,搜索者,想要给它的那样,并且它与许多收集器 (Collector) 对话以合并/提供最佳结果。
DS:那么,您是如何播种这个东西的?
JM:我已经开始建立 Atlas 工厂 (Factory)。我们可能会宣布一项竞赛,以构建开源收集器 (Collector),这些收集器 (Collector) 可以使用 Internet Archive 做不同的/很酷的事情。一旦 Atlas 开始自主呼吸,并且可以公开或门控(基于署名或付费)发布该档案,或者如果它可以为特定类别的查询更好地对 Web 结果进行排名,它可以将该数据用作收集器 (Collector) 并再次提供该数据,公开或门控。但这只是推测和为时过早。目前一切都还很开放。
DS:太棒了。我知道一些投资者已经向 Technorati 施压,要求删除档案,因为那不是他们搜索的内容。然而。
我想我需要了解一下搜索可能是什么样子,以及它将如何提出与 Google 的静态搜索和 Technorati 的动态(按时间顺序)搜索不同的东西。我会去 atlas.wikia.org 搜索吗?还是去……哪里?或者这个问题太静态或基于站点了?
JM:我还没有 Atlas 的“静态”存在。出于某种原因,甚至拒绝这样做。目前只有一个指向邮件列表的链接。总有一天会有一个存在,但现在的讨论更重要。我喜欢目前所有人能做的就是讨论。
DS:我只是在研究如何帮助人们理解它是什么。它是一个站点吗?其他站点,甚至 IM 系统或手机应用程序可以使用的服务?
JM:Atlas 是一种想法、一种模型,最终是一种两个人之间的通信系统:一个想要学习的人和一个想要教/分享的人。它只是另一个通信平台,但对话的人们彼此还不认识。像所有优秀的互联网系统一样,它将生活在幕后,在各处的文本输入框后面。
DS:在这方面,它更像 Jabber “平台”而不是 AIM 或 Skype “平台”。
JM:是的,Google、Yahoo 和 Ask 是 IM 孤岛,而 Atlas 是分布式/开放的 Jabber 模型。
DS:好的。我明白了。Atlas 代码是否位于某个地方并被赋予一堆要查看的东西?如果是这样,它住在哪里?我们可以使用图纸吗?某种简单的白板?
JM:东西在哪里几乎无关紧要。就可视化而言,“逻辑”上的可视化确实是工厂 (Factory)→收集器 (Collector)→代理 (Broker),但技术上的可视化更像是一个三角形,因为代理 (Broker) 最终会与工厂 (Factory) 对话以获取 Knugget……但基本上没有,目前没有任何可视化。工厂 (Factory) 将“看起来”像一堆基于内容源本身排序的搜索结果。收集器 (Collector) 将聚合/排序它们。代理 (Broker) 将从许多收集器 (Collector) 聚合排序后的结果,合并它们,从它们来自的工厂 (Factory) 获取摘要,并呈现它们。顺便说一句,有人制作了该模型的第一个可视化图(图 1)。
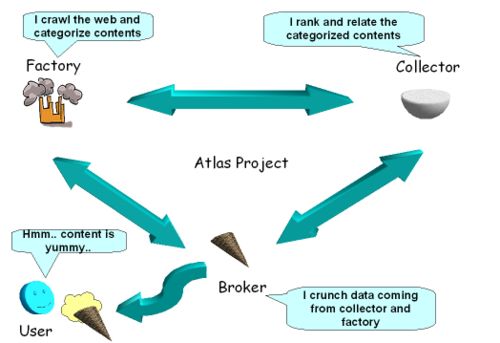
图 1. Atlas 模型的可视化图(来自 search.wikia.com/wiki/Atlas)
DS:它们会住在哪里?参与者……工厂 (Factory)、收集器 (Collector)、代理 (Broker)……或者所有这些的代码?
JM:哦,任何人都可以运行它们中的任何一个。将会有开源项目来提供它们中的每一个。但是,应该有成千上万个,在世界各地运行。就像 Jabber、电子邮件和 Web 服务器一样。他们只是通过协议相互交谈。可以有基于区域的特定实例,针对不同语言的实例,针对内容类型(图像、视频)的实例,针对主题(游戏、金融)的实例——无论人们想做什么/专攻什么。人们可以出于他们想要的任何原因运行它们。代理 (Broker) 确实是端点,因此搜索的性质是代理 (Broker) 与相关的收集器 (Collector) 接洽。代理 (Broker) 正在做这个词的真正含义,将您的搜索代理到许多来源以获得最佳结果。代理 (Broker) 很可能会内置到您的浏览器或任何驱动任何地方的输入框的东西中。
DS:我喜欢它映射到现实世界的方式。
JM:它不强制执行操作模型,并且它只是顺应人们运行它的任何动机。好处是,只有当人们发现它足够有价值来运行时,它才会起作用;这些是最好的系统类型。那么所有这些都像泥一样清晰吗?
DS:好泥!
JM:谢谢。
欲了解更多信息,请在 Google 上搜索 Jeremie 和 Atlas。
直到您可以反向操作。
Doc Searls 是Linux Journal的高级编辑。他还是加州大学圣巴巴拉分校的访问学者,以及哈佛大学伯克曼互联网与社会中心的研究员。
