
C 语言高性能网络编程
在 Linux 上使用 C 语言进行 TCP/IP 网络编程非常有趣。您可以随意使用协议栈的所有高级功能,并且可以在用户空间中完成许多有趣的事情,而无需深入内核编程。
性能提升既是一门艺术,也是一门科学。这是一个迭代过程,类似于艺术家用精细的画笔小心翼翼地描绘一幅画,从不同的角度和距离观察作品,直到对结果感到满意。
这种艺术性的比喻是 Linux 提供的一系列丰富的工具,用于衡量网络吞吐量和性能。基于此,程序员可以调整某些参数,有时甚至重新设计他们的解决方案,以达到预期的结果。
我不会进一步赘述高性能编程的艺术性方面。在本文中,我将重点介绍某些通用的机制,这些机制保证能提供明显的改进。基于此,您应该能够在正确工具的帮助下完成最后的润色。
我主要处理 TCP,因为内核为我们完成了带宽管理和流量控制。当然,我们也不再需要担心可靠性。如果您对性能和高流量感兴趣,无论如何您都会选择 TCP。
一旦我们回答了这个问题,我们可以问自己另一个有用的问题:“我们如何才能充分利用可用的带宽?”
维基百科对带宽的定义是通信信道的较高截止频率和较低截止频率之间的差值。截止频率由基本的物理定律决定——我们对此无能为力。
但是,在其他方面我们有很多可以做的。根据克劳德·香农的说法,实际可实现的带宽取决于信道中的噪声水平、使用的数据编码等等。借鉴香农的想法,我们应该以这样一种方式“编码”我们的数据,使协议开销最小,并且大部分比特用于携带有用的有效载荷数据。
TCP/IP 数据包在分组交换环境中工作。我们必须与网络上的其他节点竞争。在您的产品最有可能驻留的 LAN 环境中,没有专用带宽的概念。这是我们可以通过一些编程来控制的。
如果瓶颈是您的本地 LAN(在某些拥挤的 ADSL 部署中也可能是这种情况),这是一种最大化吞吐量的方法。只需使用多个 TCP 连接。这样,您可以确保您获得所有关注,而牺牲 LAN 中其他节点的利益。这就是下载加速器的秘密。它们打开与 FTP 和 HTTP 服务器的多个 TCP 连接,并将文件分成几块下载,并在多个偏移量处重新组装。但这并不是“友好的游戏”。
我们希望成为行为良好的公民,这就是非阻塞 I/O 的用武之地。在网络上进行阻塞读取和写入的传统方法非常容易编程,但是如果您有兴趣通过泵送数据包来填充可供您使用的管道,则必须使用非阻塞 TCP 套接字。列表 1 显示了一个简单的代码片段,使用非阻塞套接字进行网络读取和写入。
列表 1. nonblock.c
/* set socket non blocking */
fl = fcntl(accsock, F_GETFL);
fcntl(accsock, F_SETFL, fl | O_NONBLOCK);
void
poll_wait(int fd, int events)
{
int n;
struct pollfd pollfds[1];
memset((char *) &pollfds, 0, sizeof(pollfds));
pollfds[0].fd = fd;
pollfds[0].events = events;
n = poll(pollfds, 1, -1);
if (n < 0) {
perror("poll()");
errx(1, "Poll failed");
}
}
size_t
readmore(int sock, char *buf, size_t n) {
fd_set rfds;
int ret, bytes;
poll_wait(sock,POLLERR | POLLIN );
bytes = readall(sock, buf, n);
if (0 == bytes) {
perror("Connection closed");
errx(1, "Readmore Connection closure");
/* NOT REACHED */
}
return bytes;
}
size_t
readall(int sock, char *buf, size_t n) {
size_t pos = 0;
ssize_t res;
while (n > pos) {
res = read (sock, buf + pos, n - pos);
switch ((int)res) {
case -1:
if (errno == EINTR || errno == EAGAIN)
continue;
return 0;
case 0:
errno = EPIPE;
return pos;
default:
pos += (size_t)res;
}
}
return (pos);
}
size_t
writenw(int fd, char *buf, size_t n)
{
size_t pos = 0;
ssize_t res;
while (n > pos) {
poll_wait(fd, POLLOUT | POLLERR);
res = write (fd, buf + pos, n - pos);
switch ((int)res) {
case -1:
if (errno == EINTR || errno == EAGAIN)
continue;
return 0;
case 0:
errno = EPIPE;
return pos;
default:
pos += (size_t)res;
}
}
return (pos);
}
请注意,您应该使用 fcntl(2) 而不是 setsockopt(2) 来将套接字文件描述符设置为非阻塞模式。使用 poll(2) 或 select(2) 来确定套接字何时准备好读取或写入。select(2) 无法确定套接字何时准备好写入,因此请注意这一点。
非阻塞 I/O 如何提供更好的吞吐量?在阻塞和非阻塞 I/O 的情况下,操作系统调度用户进程的方式不同。当您阻塞时,进程“睡眠”,这会导致上下文切换。当您使用非阻塞套接字时,可以避免这个问题。
另一种有趣的技术是散射/聚集 I/O 或使用 readv(2) 和 writev(2) 进行网络和/或磁盘 I/O。
不是使用缓冲区作为数据传输的单位,而是使用缓冲区数组。每个缓冲区的长度可以不同,这使得它非常有趣。
您可以从/向网络传输在多个源/目标之间分割的大量数据块。这可能是一种有用的技术,具体取决于您的应用程序。列表 2 显示了一个代码片段,用于说明其用法。
列表 2. uio.c
#include <sys/types.h>
#include <sys/uio.h>
#include <unistd.h>
size_t
writeuio(int fd, struct iovec *iov, int cnt)
{
size_t pos = 0;
ssize_t res;
n = iov[0].iov_cnt;
while (n > pos) {
poll_wait(fd, POLLOUT | POLLERR);
res = writev (fd, iov[0].iov_base + pos, n - pos);
switch ((int)res) {
case -1:
if (errno == EINTR || errno == EAGAIN)
continue;
return 0;
case 0:
errno = EPIPE;
return pos;
default:
pos += (size_t)res;
}
}
return (pos);
}
当您将散射/聚集 I/O 与非阻塞套接字结合使用时,事情会变得有点复杂,如图 1 所示。解决这个棘手问题的代码如列表 3 所示。
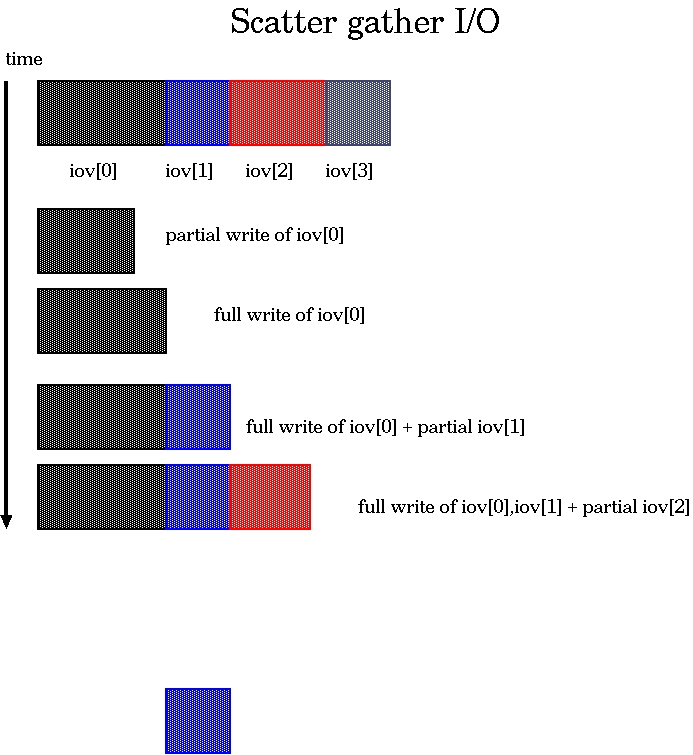
图 1. 使用散射/聚集 I/O 进行非阻塞写入的可能性
列表 3. nonblockuio.c
writeiovall(int fd, struct iov *iov, int nvec) {
int i, bytes;
i = 0;
while (i < nvec) {
do
{
rv = writev(fd, &vec[i], nvec - i);
} while (rv == -1 &&
(errno == EINTR || errno == EAGAIN));
if (rv == -1) {
if (errno != EINTR && errno != EAGAIN) {
perror("write");
}
return -1;
}
bytes += rv;
/* recalculate vec to deal with partial writes */
while (rv > 0) {
if (rv < vec[i].iov_len) {
vec[i].iov_base = (char *)
vec[i].iov_base + rv;
vec[i].iov_len -= rv;
rv = 0;
}
else {
rv -= vec[i].iov_len;
++i;
}
}
}
/* We should get here only after we write out everything */
return 0;
}
可能会发生任何缓冲区的局部写入,或者您可以获得一些完整写入和一些局部写入的任意组合。因此,while 循环必须处理所有这些可能的组合。
然而,网络编程不仅仅是关于套接字。我们仍然没有解决必须使用硬盘的问题,硬盘是机械设备,因此在许多情况下(如果不是大多数情况),硬盘比主内存甚至网络慢得多(尤其是在高性能计算环境中)。
您可以使用其他形式的持久存储,但是今天,没有哪种存储能与硬盘提供的大容量存储相媲美。目前,Internet 上的大多数应用程序都推送了几个 GB 的数据,最终您仍然需要大量的存储。
要测试磁盘性能,请输入
$ hdparm -rT /dev/sda (/dev/hda if IDE)
检查您是否获得了良好的吞吐量。如果不是,请使用此命令启用 DMA 和其他安全选项
$ hdparm -d 1 -A 1 -m 16 -u 1 -a 64 /dev/sda
我们还需要能够避免冗余副本和其他耗时的 CPU 操作,以从网络中榨取最大的带宽。实现这一目标的非常有效的工具是通用的 mmap(2) 系统调用。这是一种非常有用的技术,可以避免复制到缓冲区缓存,从而提高网络 I/O 的性能。但是,如果您将 mmap(2) 与 NFS 一起使用,那您就是在自找麻烦。列表 4 显示了一个代码片段,说明了如何使用 mmap(2) 进行文件读取和写入。
列表 4. mmap.c
/******************************************
* mmap(2) file write *
* *
*****************************************/
caddr_t *mm = NULL;
fd = open (filename, O_RDWR | O_TRUNC | O_CREAT, 0644);
if(-1 == fd)
errx(1, "File write");
/* NOT REACHED */
/* If you don't do this, mmapping will never
* work for writing to files
* If you don't know file size in advance as is
* often the case with data streaming from the
* network, you can use a large value here. Once you
* write out the whole file, you can shrink it
* to the correct size by calling ftruncate
* again
*/
ret = ftruncate(ctx->fd,filelen);
mm = mmap(NULL, header->filelen, PROT_READ | PROT_WRITE,
MAP_SHARED, ctx->fd, 0);
if (NULL == mm)
errx(1, "mmap() problem");
memcpy(mm + off, buf, len);
off += len;
/* Please don't forget to free mmap(2)ed memory! */
munmap(mm, filelen);
close(fd);
/******************************************
* mmap(2) file read *
* *
*****************************************/
fd = open(filename, O_RDONLY, 0);
if ( -1 == fd)
errx(1, " File read err");
/* NOT REACHED */
fstat(fd, &statbf);
filelen = statbf.st_size;
mm = mmap(NULL, filelen, PROT_READ, MAP_SHARED, fd, 0);
if (NULL == mm)
errx(1, "mmap() error");
/* NOT REACHED */
/* Now onward you can straightaway
* do a memory copy of the mm pointer as it
* will dish out file data to you
*/
bufptr = mm + off;
/* You can straightaway copy mmapped memory into the
network buffer for sending */
memcpy(pkt.buf + filenameoff, bufptr, bytes);
/* Please don't forget to free mmap(2)ed memory! */
munmap(mm, filelen);
close(fd);
Linux 下的 TCP 套接字带有一组丰富的选项,您可以使用这些选项来操作 OS TCP/IP 协议栈的功能。一些选项对于性能很重要,例如 TCP 发送和接收缓冲区大小
sndsize = 16384; setsockopt(socket, SOL_SOCKET, SO_SNDBUF, (char *)&sndsize, (int)sizeof(sndsize)); rcvsize = 16384; setsockopt(socket, SOL_SOCKET, SO_RCVBUF, (char *)&rcvsize, (int)sizeof(rcvsize));
我在这里使用了保守的值。显然,对于千兆网络,它应该更高。这些值由带宽延迟乘积决定。有趣的是,我从未发现这是一个问题,因此我怀疑这是否会给您带来性能提升。但仍然值得一提,因为仅 TCP 窗口大小就可以为您提供最佳吞吐量。
可以使用 Linux 下的 /proc 伪文件系统设置其他选项(包括以上两个),除非您的 Linux 发行版关闭了某些选项,否则您不必调整它们。
启用 PMTU(路径最大传输单元)发现以避免 IP 分片也是一个好主意。IP 分片不仅会影响性能,而且肯定比其他任何事情都更重要。为了不惜一切代价避免分片,一些 HTTP 服务器使用了保守的数据包大小。这样做不是一件好事,因为协议开销会相应增加。更多的数据包意味着更多的标头和浪费的带宽。
您可以不使用 write(2) 或 send(2) 进行传输,而是可以使用 sendfile(2) 系统调用。这在避免冗余副本方面提供了可观的节省,因为位直接在文件描述符和套接字描述符之间传递。请注意,这种方法在 UNIX 中不具有可移植性。
应用程序应该设计良好,以充分利用网络资源。首先,对于顺序处理,在相同的两个端点之间使用多个短寿命的 TCP 连接是错误的。它可以工作,但会损害性能并导致其他几个头痛的问题。最值得注意的是,TCP TIME_WAIT 状态的超时时间是最大段生存期的两倍。由于往返时间在繁忙的网络和高延迟网络中差异很大,因此此值通常不准确。还有其他问题,但是如果您设计好您的应用程序,使用正确的协议标头和 PDU 边界,则永远不需要使用不同的 TCP 连接。
以 SSH 为例。仅使用一个连接就复用了多少个不同的 TCP 流?从中吸取教训。
您不必在客户端和服务器之间按部就班地工作。仅仅因为协议和算法以固定的顺序可视化,并不意味着实现也应该遵循。
通过并行执行操作——在读取网络上的下一个数据包之前不等待处理完成,您可以出色地利用可用带宽。图 2 说明了我的意思。
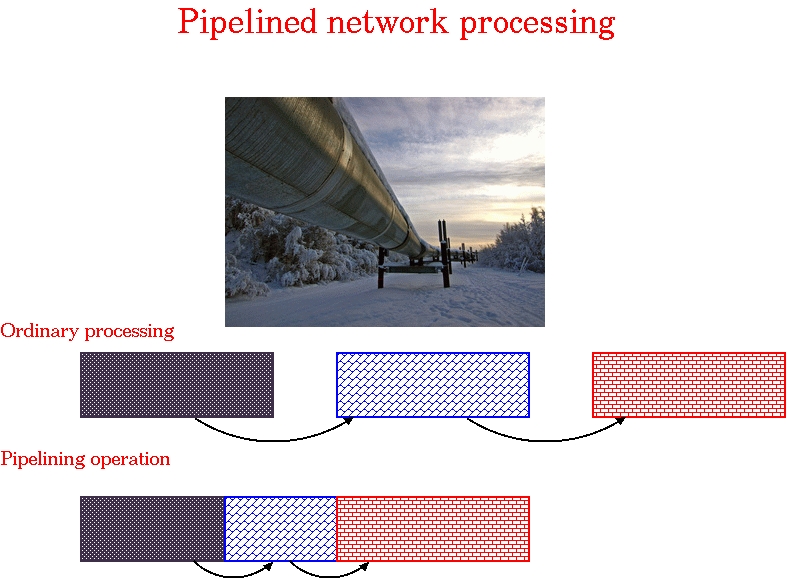
图 2. 流水线
流水线是 CPU 中使用的一种强大技术,用于加速 FETCH-DECODE-EXECUTE 周期。在这里,我们将相同的技术用于网络处理。
显然,您的线路协议应具有最小的开销,并且应在很大程度上独立于未来的输入而工作。通过保持状态机相当独立和隔离,您可以高效地处理。
避免冗余的协议标头或大多为空或未使用的字段可以为您节省宝贵的带宽,用于携带真实的数据有效载荷。标头字段应在 32 位边界对齐,表示它们的 C 结构也应如此。
如果您的应用程序已经投入生产并且您想提高其性能,请尝试上述一些技术。如果您一次处理一个问题,那么重新设计应用程序的问题应该不会太麻烦。请记住,永远不要相信任何理论——甚至包括本文。亲自测试一切。如果您的测试没有报告性能提升,请不要这样做。另外,请确保您的测试用例考虑了 LAN、WAN 以及必要的卫星和无线环境。
几十年来,TCP 一直是深入研究的领域。它是一种极其复杂的协议,在 Internet 上肩负着重大的责任。我们经常忘记,TCP 是将 Internet 凝聚在一起而不因拥塞而崩溃的原因。IP 将网络连接在一起,而 TCP 确保路由器不会过载,并且数据包不会丢失。
因此,TCP 对性能的影响高于当今任何其他协议。难怪顶尖研究人员撰写了多篇关于该主题的论文。
Internet 绝不是同质的。如今,TCP/IP 在其上工作的物理层技术应有尽有。但是,TCP 的设计目的不是为了在无线网络中良好工作。即使是高延迟卫星链路也会质疑 TCP 对窗口大小和往返时间测量的一些假设。
而且,TCP 并非没有缺陷。拥塞控制算法,例如慢启动、拥塞避免、快速重传、快速恢复等等,有时会失败。当这种情况发生时,会损害您的性能。通常,三个重复的 ACK 数据包足以触发拥塞控制机制。无论您做什么,这些机制都可能急剧降低性能,特别是如果您拥有非常高速的网络。
但是,在所有其他条件相同的情况下,以上技术是为您的应用程序实现良好性能的一些最有效的方法。
追求极高的性能不是一件可以掉以轻心的事情。它依赖于启发式方法和经验数据以及经过验证的技术。正如我之前提到的,这是一种最好通过实践来完善的艺术,并且也是一个迭代过程。但是,一旦您对事物的运作方式有所了解,一切都会一帆风顺。当您像这样为快速客户端/服务器交互构建了一个稳定的基础时,在其之上构建强大的 P2P 框架就不是什么大问题了。
资源
Polipo 用户手册: www.pps.jussieu.fr/~jch/software/polipo/manual
TCP 调优和网络故障排除: www.onlamp.com/pub/a/onlamp/2005/11/17/tcp_tuning.html
维基百科对带宽的定义: en.wikipedia.org/wiki/Bandwidth
高级网络技术: beej.us/guide/bgnet/output/html/multipage/advanced.html
TCP 和拥塞控制幻灯片: www.nishida.org/soi1/mgp00001.html
Girish Venkatachalam 是一位对 UNIX 深感兴趣的开源黑客。在他的空闲时间,他喜欢烹饪素食菜肴并真正吃掉它们。可以通过 girish1729@gmail.com 与他联系。
