
BPF 可观测性:快速入门
BPF 的原理和原因
BPF 是 Linux 内核中的一个强大组件,利用它的工具种类繁多且数量庞大。在本文中,我们将探讨 BPF 的通用实用性,并引导您走上利用 BPF 的实用性和强大功能的道路。与许多技术一样,BPF 的一个方面是乍一看可能会让人感到难以承受。我们力求消除这种感觉,并帮助您入门。
什么是 BPF?
BPF 是名称,不再是首字母缩写词,但最初是 Berkeley Packet Filter,然后是 eBPF(Extended BPF),现在只是 BPF。BPF 是 Linux 的内核和用户空间可观测性方案。
一个描述是,BPF 是一种经过验证安全、快速切换的机制,用于在 Linux 内核空间中运行代码,以响应诸如函数调用、函数返回以及内核或用户空间中的跟踪点等事件。
要使用 BPF,需要运行一个程序,该程序被翻译成将在内核空间中运行的指令。这些指令可以被解释或翻译成原生指令。对于大多数用户来说,确切的性质并不重要。
在内核中,BPF 代码可以为事件执行操作,例如,创建堆栈跟踪、计数事件或将计数收集到直方图的桶中。
通过这种方式,BPF 程序为深入观测 Linux 内核或用户空间中正在发生的事情提供了快速、极其强大和灵活的手段。从内核空间观测用户空间当然是可能的,因为内核可以控制和观测在用户模式下执行的代码。
运行 BPF 程序相当于让用户程序发出 BPF 系统调用,这些调用会检查适当的权限并验证是否在限制范围内执行。例如,在 Linux 内核版本 5.4.44 中,BPF 系统调用使用以下方式检查权限
if (sysctl_unprivileged_bpf_disabled && !capable(CAP_SYS_ADMIN)) return -EPERM;
BPF 系统调用检查 sysctl 控制的值和能力。sysctl 变量可以使用以下命令设置为 1
sysctl kernel.unprivileged_bpf_disabled=1
但是要将其设置为零,您必须重新启动,并确保您的系统配置为在启动时不将其设置为 1。
由于 BPF 在内核空间中完成工作,因此节省了大量时间和开销,避免了上下文切换,并且无需将大量数据传输回用户空间。
并非所有内核函数都可以被跟踪。例如,如果您尝试 funccount-bpfcc '*_copy_to_user',您可能会得到如下输出
cannot attach kprobe, Invalid argument Failed to attach BPF program b'trace_count_3' to kprobe b'_copy_to_user'
这有点神秘。如果您检查 dmesg 的输出,您会看到类似
[686890.989521] trace_kprobe: Could not probe notrace function _copy_to_user
阻止探测的一个很好的理由是避免无限递归。
何时何地可以使用 BPF?
BPF 程序在内核中经过验证,以避免各种风险,例如无限循环。因此,与任意 Linux 可加载内核模块相比,BPF 程序的风险更低。与 strace 或通过 tracefs 进行跟踪等相关工具相比,BPF 程序对于许多观测任务的开销更低。
BPF 工具可以引用内核或用户空间中旨在提供稳定接口的功能——内核和用户空间跟踪点。BPF 工具还可以引用功能,例如函数或字段的名称,这些名称可能不稳定。因此,BPF 程序可能无法跨内核移植。此外,较旧的内核将不具备该功能,并且内核可能未配置为支持 BPF,因此 BPF 并非普遍可移植或可用。
但是,发行版似乎定期支持 BPF,并提供 BPF 工具包以便于安装。
因此,只要您可以作为特权用户调用 BPF,并且您正在运行最新的内核,您就应该可以使用 BPF 功能。但是,某些单独的 BPF 工具可能无法在您的内核上运行。目前正在努力使 BPF 程序更具可移植性 [2]。使用内核数据结构的工具面临的一个自然挑战是,字段的偏移量可能因内核版本和配置而异。
您的 BPF 熟练程度进阶
使用 BPF 可能涉及不同的熟练程度级别。例如,要使用 BPF 分析 Linux 内核问题,可能需要丰富的内核经验。您是否知道可能值得观测的内核函数的名称?您是否知道它们的参数是什么?因此,即使运行 BPF 工具可能很简单,但知道要让工具观测什么以及如何解释结果可能非常具有挑战性。
尽管存在这些挑战,但让我们考虑以下使用 BPF 的熟练程度级别。
从最简单到最具挑战性
- 使用软件包中的基于 BPF 的工具。
- 使用来自其他来源的 BPF 工具,例如 Brendan Gregg [7] 的工具。
- 使用 bpftrace 编写简单的脚本,甚至是一行代码的脚本。
- 用 Python [3] 编写 BCC 工具。
- 用 C/C++ [4] 编写 BPF 工具。
要学习使用软件包中的 BPF 工具,第一步是快速研究提供了哪些工具。这些工具实际上为您的工作提供了词汇表,因此您需要了解可以使用哪些工具来表达您的需求。
例如,目前我主要使用 Ubuntu 20.04.01 系统,对于该系统,当前的 bpfcc-tools 软件包提供了 118 个“二进制文件”,全部安装在 /usr/sbin 中。其中,1 个 /usr/sbin/deadlock.c-bpfcc 实际上是 C 源代码,29 个是 BASH 脚本,所有这些脚本都是调用 Python bcc 实用程序(ucalls、uflow、ugc、uobjnew、ustat 或 uthreads)之一的简单包装器。所有剩余的文件都是 Python 脚本本身。bpftrace 软件包有 35 个程序。加上 88 个 Python BCC 程序、29 个 shell 包装器以及 35 个 bpftrace,您总共有 152 个实用程序需要熟悉。这需要超过一下午的工作时间。但是,老实说,一旦您开始尝试这些工具,您会发现它们非常棒,您会想花大量时间在它们身上。
我,以及毫无疑问的您,都会发现搜索与我想做的事情相关的 bpftrace 或 bpfcc 程序非常方便。每个打包的实用程序都有一个手册页,位于第 8 节中,因此,例如,当我执行 ‘man -k "file operations" -s 8’ 时,我得到了 btrfsslower-bpfcc、ext4slower-bpfcc、nfsslower-bpfcc、xfsslower-bpfcc 和 zfsslower-bpfcc。但是,有时手册页中的内容令人惊讶。例如,如果我搜索手册页中的“network”,我没有得到任何 bpfcc-tools 或 bpftrace 命令(但有很多其他命令)。但是,如果我搜索“tcp”,我会得到 16 个 bpfcc-tools 或 bpftrace 命令。我用关键字“socket”得到了 3 个 bpfcc 程序。
命令的名称也倾向于包含关键字,因此类似 “ls /usr/sbin/*bpfcc | grep $keyword” 的命令也运行良好。
Gregg [1] 将命令分为 CPU、内存、文件系统、磁盘 I/O、网络和安全类别,但这些不一定是最佳关键字。
Debian FAQ /usr/share/doc/libbpfcc/FAQ.txt 对于帮助您解决尝试运行工具时可能遇到的问题非常有用。
使用来自其他来源的 BPF 工具bcc 工具和 bpftrace 工具的重要存储库是 [5] https://github.com/iovisor/bcc 和 [6] https://github.com/iovisor/bpftrace。从 Brendan Gregg 的书 [1] 中,您可以在 [7] https://github.com/brendangregg/bpf-perf-tools-book 找到许多其他工具。
bpf-perf-tools-book 仓库大约有 130 个 bpftrace 工具和 2 个 Python bcc 程序。那里有各种非常有价值的工具,值得安装此仓库中的工具,并至少了解它们并选择一些用于您的监控或问题调查。
不幸的是,Gregg 书籍仓库中的页面不多,因此您可能需要使用 Gregg 的书来获得好的解释。幸运的是,这些工具按章节组织,例如 Ch07_Memory,因此您可以利用这种组织快速找到在特定情况下可能有用的工具。
bash bpftrace 程序 bashfunc.bt、bashfunc2.bt 和 bashfunclat.bt 依赖于 Brendan Gregg 构建的 Bash 版本,并引用了 /home/bgregg/Build/bash-4.4.18,因此它们不能立即使用。
BPF 工具是命令,与任何命令一样,您在命令行上调用它们并提供选项和参数。当您运行这些工具时,您可能需要成为 root 用户,因为 BPF 系统调用会检查如上所示的适当能力。
所有工具都会生成文本输出,因此您可以像往常一样将它们通过管道传输到另一个实用程序,例如 sed、awk、sort 等。但是,由于 BPF 相对于 perf 或 ftrace 的主要优势之一是数据可以在内核空间中减少,例如减少到直方图计数,因此实用程序要完成的后处理被设计为最少的。
由于这些工具会一直运行到您按下 ctrl-c,因此我经常使用 timeout 命令运行它们,以秒为单位指定时间,并且要发送的信号是 SIGINT。
我有时对中断处理程序中花费的时间感兴趣,因此 hardirqs-bpfcc 命令非常方便。例如,我这样运行它
timeout -s INT 100 hardirqs-bpfcc -d
输出示例为
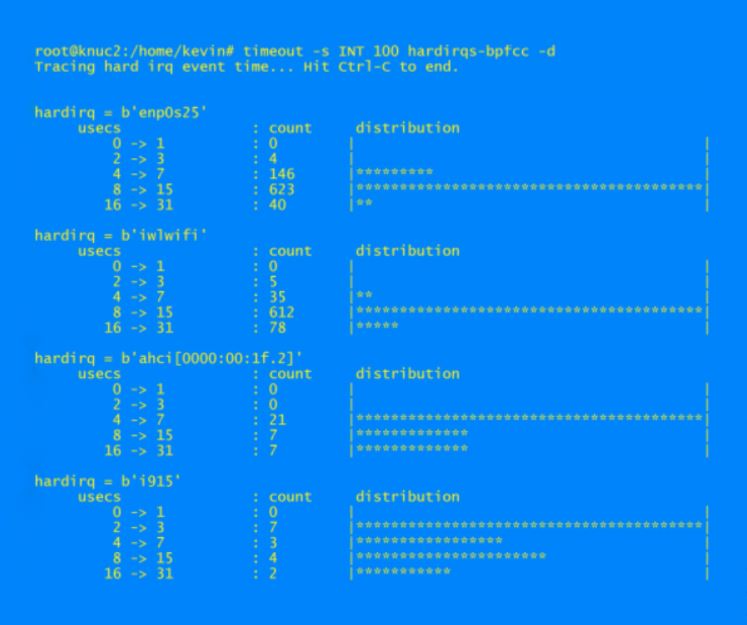
BPF 程序对事件做出反应。事件类型包括 kprobes [8]、uprobes、内核跟踪点、用户空间跟踪点(USDT,User-level Statically Defined Tracing,用户级静态定义跟踪)、动态 USDT 和性能监控计数器(例如,perf 与 BPF)。
某些工具,例如 funccount-bpfcc 是通用的,并且具有指定探测或跟踪点的语法。某些工具仅使用一种事件类型,例如,vfscount-bpfcc(内核中 vfs 函数上的 kprobe)、memleak-bpfcc(uprobe 和 uretprobe,用于探测用户空间中的分配和释放)和 mysqld_qslower-bpfcc(用于查询开始和停止的 usdt 探测)。
内核和用户空间中的跟踪点是添加到源代码中的,代表旨在用于监控的稳定位置。探测涉及可能或可能不(尤其是在内核中)保持稳定的函数。
您可以使用工具来获取可用探测、跟踪点和 PMC 的列表。tplist-bpfcc 命令将列出内核跟踪点和 USDT(用户空间)探测。perf list 命令显示性能监控计数器 (PMC)。perf 基础设施和 PMC 可以用于 BPF 程序中,例如 profile-bpfcc 和 llcstat-bpfcc。
必备知识BPF 工具经常使用和报告深奥的知识。要编写或使用工具,您可能需要熟悉内核数据结构或函数。当内核函数和数据结构发生变化时,这些工具可能会中断。数据结构可能会根据内核版本和内核配置而变化。
例如,tcptracer-bpfcc 和 udplife.bt 工具包含来自内核的头文件 net/sock.h。该文件中有一些结构,例如 sock_common,它们的字段可能存在也可能不存在,具体取决于内核的配置方式。例如,是否设置了 CONFIG_XPS(在我的 Ubuntu 内核中已设置)。
您应该得出结论,这些工具既强大又可能需要深入的知识。
使用示例来帮助与编程一样,要编写程序,首先找到另一个与您要编写的程序尽可能相似的程序,并从该程序开始。
软件包附带了大量示例。每个工具都有一个示例,并附带说明。您可以在 /usr/share/doc/bpfcc-tools 和 /usr/share/doc/bpftrace 中找到示例以及更多文档。/usr/share/doc 中还有 libbpfcc 和 python3-bpfcc 的目录。这些是运行工具的示例。当您找到一个看起来类似于您想做的工具时,您可以查看 /usr/sbin 中的工具,它将是 Python、bpftrace 或 Bash 中的包装器。
您可能会发现 llcstat-bpfcc 很有趣。我也是。此工具报告每个进程和 CPU 的 CPU 缓存命中和未命中。该程序有参数来指定运行秒数和采样率。参数的描述和一些解释可以在 /usr/share/doc/bpfcc-tools/examples/doc/llcstat_example.txt. 中找到。
程序 llcstat-bpfcc 可以作为如何使用 perf 硬件计数器的示例。您可以在 dist-packages/bcc/__init__.py 中找到 PerfHWConfig 的值,可能在 /usr/lib/python3 下。
Gregg [1] 给出了许多“一行代码”示例,这些示例非常棒且有帮助。因此,您不必编写复杂的脚本来创建用于观测行为的自定义工具。
BCC 的一行代码示例使用涉及指定事件类型或有时使用 glob 来匹配函数名称的语法的命令。
例如
funccount-bpfcc 't:syscalls:*umask*'
将报告跟踪点 sys_enter_umask 和 sys_exit_emask 被命中的次数。“t:” 表示内核跟踪点。您可以使用 “bpftrace -l” 获取可用跟踪点和探测等的列表。
要报告传递给 umask 系统调用的掩码(在内核中),我们需要查看代码以获取参数的名称。然后我们可以执行类似的操作
argdist-bpfcc -i 100 -H 't:syscalls:sys_enter_umask():int:args->mask'
入门工具
以下是八个工具的列表,供您今天开始使用。在您安装 bpftrace、BCC 和 Brendan Gregg 的 BPF 程序后,请尝试这些工具。我根据以下标准选择了这些工具:哪些工具具有广泛的实用性、哪些工具展示了重要的功能以及哪些工具我发现特别有趣和有价值。其他一些工具具有广泛的适用性或其他不错的功能,但它们可能存在诸如输出混乱或令人困惑的问题。例如,profile-bpfcc 具有巨大的潜力,但我发现它不合并堆栈跟踪并且打印了很多未知内容。Brendan Gregg 的书 [7] 中的工具页面不多,但您可以阅读源代码以获取有关它们的功能以及如何使用的文档。
今天尝试的工具(按字母顺序排列)
argdist-bpfcc此工具使您可以检查函数的参数。您可以计数或对值进行直方图分析。这适用于内核中的函数或库函数中的函数。这可以是针对特定进程或系统范围的。此程序也是一个很好的入门程序,因为要使用它,您需要熟悉内核和用户空间跟踪点或探测。您可以在 /sys/kernel/debug/tracing/events 下找到作为文件名的内核跟踪点名称。可以使用 bpftrace -l ‘usdt:<library path>’ 找到库的 USDT 跟踪点,例如 bpftrace -l 'usdt:/lib/x86_64-linux-gnu/libc.so.6'。您将看到 glibc 中几乎所有的跟踪点都用于内存分配相关函数。您可以将探测用于其他函数。
要通过 c 库中的探测使用 argdist-bpfcc,以打印每次传递给 umask 函数的掩码值的计数,打印间隔为 10 秒,循环 50 次,请执行
argdist-bpfcc -i 10 -n 50 -C 'p:c:umask(u32 mask):u32:mask'
请记住,并非所有应用程序都使用标准 C 库。例如,对于分析 Golang 程序的开发人员,请注意 Go 使用自己的库,因此对于标准库函数,您将使用 “go” 而不是 “c” 作为库。
biolatency-bpfccbiolatency-bpfcc 工具将打印磁盘设备的延迟直方图。我喜欢这样运行它
biolatency-bpfcc -D
-D 选项将使该工具为每个在您查看的间隔内有 I/O 的磁盘设备打印单独的直方图。
与著名的工具 “top” 类似,biotop-bpfcc 工具显示自上次刷新以来累积的数据的多列刷新显示。biotop 工具显示磁盘设备和 I/O 统计信息。如果进程是短暂的,那么您可能需要使用 -C 选项来防止 biotop 清除屏幕。
bpftrace 工具是功能强大的 bpftrace 语言的解释器。后缀为 “.bt” 的程序是 bpftrace 程序。您也可以在命令行上执行简单的一行代码程序。请注意,Brendan Gregg 的书 [7] 的附录 A 中有很多 bpftrace 一行代码示例。这是一个将打印块大小直方图的示例。按 ctrl-c 停止它并让它打印直方图。
bpftrace -e 't:block:block_rq_issue { @bytes = hist(args->bytes); }'
您会发现修改 bpftrace 程序比修改 bpfcc 程序更简单。bpftrace 语言有自己的语法来指定事件(usdt、uretprobe、interval、uprobe、kretprobe、tracepoint、kprobe)。最常用的是 tracepoint 和 kprobe。
例如,hfaults.bt 程序通过计算对 hugetlb_fault() 的调用来执行其工作,如下所示
kprobe:hugetlb_fault
{
@[pid, comm] = count();
}
cachestat-bpfcc
cachestat-bpfcc 程序用于跟踪磁盘缓存性能。我喜欢使用间隔和迭代次数以及时间戳来运行它。像这样
cachestat-bpfcc -T 30 5
您可以轻松地尝试类似递归 grep 的操作。在大型目录上背靠背运行两次 grep,并且您最近没有读取过。第一次您应该看到很多未命中,第二次您的命中应该明显更高。您也可以通过告诉内核首先刷新其缓存来进行实验。例如
echo 3 >/proc/sys/vm/drop_caches; cachestat-bpfcc -T 10 20filetop-bpfcc
filetop-bpfcc 程序是一个刷新的类似 top 的程序,显示命令和文件 I/O,包括文件名统计信息。当您执行长时间的递归 grep 时,您可以通过运行 filetop-bpfcc 来查看递归 grep 正在读取的大量内容。
funccount-bpfccfunccount-bpfcc 程序计算内核或用户空间中函数的调用次数。函数名称可以使用 globbing 或使用 “-r” 选项的正则表达式。您可以使用 “-p” 选项指定特定进程,或使库调用成为系统范围的。您可以使用跟踪点或探测。
例如,要跟踪内核中所有以 iwl_trans 开头的函数(在 iwlwifi 驱动程序内部),请执行
funccount-bpfcc "iwl_trans*"trace-bpfcc
trace-bpfcc 程序比仅仅计算函数调用更强大。trace 程序可以打印参数、返回值和评估表达式,以确定是否显示跟踪信息。trace 命令每个事件可能会产生大量开销,因此它最适合不经常发生的事件。由于 trace 可以使用函数的参数,因此它可能需要知道类型。例如,结构是什么样的。您可以告诉 trace 包含头文件以提供该信息。
BPF 程序可能会因各种约束而失败,例如,如上所述,某些函数不可跟踪。作为另一个示例,当我尝试像这样跟踪时
'tcp_select_initial_window(const struct sock *sk, int __space, u32 mss, u32 *rcv_wnd, u32 *window_clamp, int wscale_ok, u8 *rcv_wscale, u32 init_rcv_wnd) "%d", arg2'
我得到了
error: too many arguments, bcc only supports in-register parameters
但我不需要参数列表,所以我可以只做
'tcp_select_initial_window() "%d", arg2'
这工作正常。
下一步做什么
当然,学习使用工具需要使用该工具。前进并进行 BPF 实践。BPF 工具旨在安全运行,即使在生产环境中也是如此,但也许您可能希望从上面选择的程序开始,在开发系统上,甚至可能是您的 Linux 笔记本电脑上。我建议使用 5.4 或更高版本的内核的系统。
如果您想要客观衡量您的 BPF 知识——为了说服自己,或其他人(例如潜在的雇主),您对 BPF 及其工具具有丰富的知识,那么您可能需要参加您可以在 aardfoss.com 上找到的性能测量和调优评估考试。要更快且有重点地学习 BPF,您可以参加培训。例如,我教授一个关于 BPF 的公开注册课程。
Brendan Gregg 的《BPF Performance Tools: Linux System and Application Observability》[1] 是许多工具、技术和 BPF 技术解释的权威书籍。
参考文献
[1] Gregg, Brendan. BPF Performance Tools: Linux System and Application Observability. Addison-Wesley, 2020.
[2] BPF 可移植性和 CO-RE
[3] bcc Python 开发者教程
[4] BPF C
[5] BCC git 仓库
[6] BPFtrace git 仓库
[7] Gregg, Brendan BPF Performance Tools 书籍 git 仓库
[8] 内核探测 (Kprobes)






