
糟糕!调试内核崩溃
深入了解内核崩溃的原因以及一些帮助获取更多信息的实用程序。
在 Linux 环境中工作,您多久会看到内核崩溃?当它发生时,您的系统会处于瘫痪状态,直到您完全重启它。而且,即使在您使系统恢复到功能状态后,您仍然会留下疑问:为什么?您可能不知道发生了什么或为什么会发生。这些问题是可以回答的,以下指南将帮助您找出导致原始崩溃的某些条件的原因。
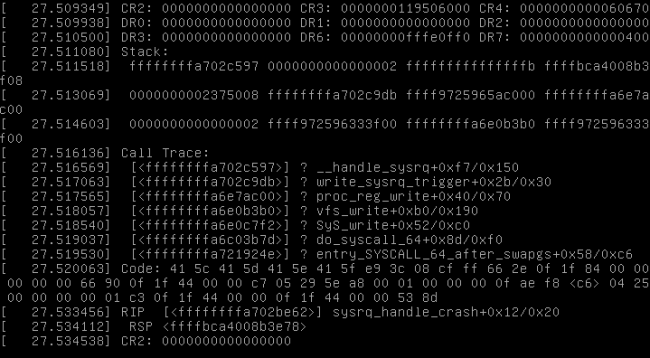
图 1. 典型的内核崩溃
让我们首先看看一组称为 kexec 和 kdump 的实用程序。 kexec 允许您从现有(且正在运行的)内核引导到另一个内核,而 kdump 是一个基于 kexec 的 Linux 崩溃转储机制。
首先,您的内核应在其映像中静态构建以下组件
CONFIG_RELOCATABLE=y
CONFIG_KEXEC=y
CONFIG_CRASH_DUMP=y
CONFIG_DEBUG_INFO=y
CONFIG_MAGIC_SYSRQ=y
CONFIG_PROC_VMCORE=y
您可以在 /boot/config-`uname -r` 中找到它。
确保您的操作系统已更新到最新和最佳的软件包版本
$ sudo apt update && sudo apt upgrade
安装以下软件包(我目前正在使用 Debian,但这应该并且将适用于 Ubuntu)
$ sudo apt install gcc make binutils linux-headers-`uname -r`
↪kdump-tools crash `uname -r`-dbg
注意:软件包名称可能因发行版而异。
在安装过程中,系统会提示您回答一些问题,以启用 kexec 来处理重启(您可以随意回答,但我回答了“否”;参见图 2)。
图 2. kexec 配置菜单
并启用 kdump 在系统启动时运行和加载,回答“是”(图 3)。
图 3. kdump 配置菜单
配置 kdump打开 /etc/default/kdump-tools 文件,在最顶部,您应该看到以下内容
USE_KDUMP=1
#KDUMP_SYSCTL="kernel.panic_on_oops=1"
最终,您将编写一个自定义模块,该模块将触发 OOPS 内核状况,为了让 kdump 收集并保存系统状态以进行事后分析,您需要启用内核在此 OOPS 状况下发生崩溃。为了做到这一点,请取消注释以 KDUMP_SYSCTL 开头的行
USE_KDUMP=1
KDUMP_SYSCTL="kernel.panic_on_oops=1"
初始测试将需要启用 SysRq。有很多方法可以做到这一点,但这里我提供了在系统重启时启用对此功能支持的说明。打开 /etc/sysctl.d/99-sysctl.conf 文件,并确保取消注释以下行(靠近文件底部)
kernel.sysrq=1
现在,打开此文件:/etc/default/grub.d/kdump-tools.default。您将找到一行看起来像这样的行
GRUB_CMDLINE_LINUX_DEFAULT="$GRUB_CMDLINE_LINUX_DEFAULT
↪crashkernel=384M-:128M"
修改读取 crashkernel=384M-:128M 的部分为 crashkernel=128M。
现在,更新您的 GRUB 引导配置檔案
$ sudo update-grub
[sudo] password for petros:
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.9.0-8-amd64
Found initrd image: /boot/initrd.img-4.9.0-8-amd64
done
然后,重启系统。
验证您的 kdump 环境从重启返回后,dmesg 将记录以下内容
$ sudo dmesg |grep -i crash
[ 0.000000] Command line: BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64
↪root=UUID=bd76b0fe-9d09-40a9-a0d8-a7533620f6fa ro quiet
↪crashkernel=128M
[ 0.000000] Reserving 128MB of memory at 720MB for crashkernel
↪(System RAM: 4095MB)
[ 0.000000] Kernel command line: BOOT_IMAGE=/boot/
↪vmlinuz-4.9.0-8-amd64
↪root=UUID=bd76b0fe-9d09-40a9-a0d8-a7533620f6fa ro
↪quiet crashkernel=128M
而您的内核将启用以下功能(“1”表示已启用)
$ sudo sysctl -a|grep kernel|grep -e panic_on_oops -e sysrq
kernel.panic_on_oops = 1
kernel.sysrq = 1
您的 kdump 服务应该正在运行
$ sudo systemctl status kdump-tools.service
kdump-tools.service - Kernel crash dump capture service
Loaded: loaded (/lib/systemd/system/kdump-tools.service;
↪enabled; vendor preset: enabled)
Active: active (exited) since Tue 2019-02-26 08:13:34 CST;
↪1h 33min ago
Process: 371 ExecStart=/etc/init.d/kdump-tools start
↪(code=exited, status=0/SUCCESS)
Main PID: 371 (code=exited, status=0/SUCCESS)
Tasks: 0 (limit: 4915)
CGroup: /system.slice/kdump-tools.service
Feb 26 08:13:34 deb-panic systemd[1]: Starting Kernel crash
↪dump capture service...
Feb 26 08:13:34 deb-panic kdump-tools[371]: Starting
↪kdump-tools: loaded kdump kernel.
Feb 26 08:13:34 deb-panic kdump-tools[505]: /sbin/kexec -p
↪--command-line="BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64 root=
Feb 26 08:13:34 deb-panic kdump-tools[506]: loaded kdump kernel
Feb 26 08:13:34 deb-panic systemd[1]: Started Kernel crash dump
↪capture service.
您的崩溃内核应该已加载(到内存中,并在您之前定义的 128M 区域中)
$ cat /sys/kernel/kexec_crash_loaded
1
您可以在此处进一步验证您的 kdump 配置
$ sudo kdump-config show
DUMP_MODE: kdump
USE_KDUMP: 1
KDUMP_SYSCTL: kernel.panic_on_oops=1
KDUMP_COREDIR: /var/crash
crashkernel addr: 0x2d000000
/var/lib/kdump/vmlinuz: symbolic link to /boot/
↪vmlinuz-4.9.0-8-amd64
kdump initrd:
/var/lib/kdump/initrd.img: symbolic link to /var/lib/kdump/
↪initrd.img-4.9.0-8-amd64
current state: ready to kdump
kexec command:
/sbin/kexec -p --command-line="BOOT_IMAGE=/boot/
↪vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-
↪a0d8-a7533620f6fa ro quiet irqpoll nr_cpus=1 nousb
↪systemd.unit=kdump-tools.service
↪ata_piix.prefer_ms_hyperv=0"
↪--initrd=/var/lib/kdump/initrd.img /var/lib/kdump/vmlinuz
让我们也在不实际运行它的情况下进行测试
$ sudo kdump-config test
USE_KDUMP: 1
KDUMP_SYSCTL: kernel.panic_on_oops=1
KDUMP_COREDIR: /var/crash
crashkernel addr: 0x2d000000
kdump kernel addr:
kdump kernel:
/var/lib/kdump/vmlinuz: symbolic link to /boot/
↪vmlinuz-4.9.0-8-amd64
kdump initrd:
/var/lib/kdump/initrd.img: symbolic link to
↪/var/lib/kdump/initrd.img-4.9.0-8-amd64
kexec command to be used:
/sbin/kexec -p --command-line="BOOT_IMAGE=/boot/
↪vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-
↪a0d8-a7533620f6fa ro quiet irqpoll nr_cpus=1 nousb
↪systemd.unit=kdump-tools.service
↪ata_piix.prefer_ms_hyperv=0"
↪--initrd=/var/lib/kdump/initrd.img /var/lib/kdump/vmlinuz
既然您的环境已加载以使用 kdump,您可能应该对其进行测试,而测试它的最佳方法是通过 SysRq 强制内核崩溃。假设您的内核是使用 SysRq 支持构建的,那么崩溃正在运行的内核就像输入
$ echo "c" | sudo tee -a /proc/sysrq-trigger
您应该期待什么?您将看到类似于图 1 中显示的内核崩溃。在崩溃之后,通过 kexec 加载的内核将收集系统状态,其中包括内存、CPU、dmesg、已加载模块等中的所有相关信息。然后,它会将这些有价值的崩溃数据保存在 /var/crash 中的某个位置以供进一步分析。一旦信息收集完成,系统将自动重启,并将您带回功能状态。
接下来做什么?您现在有了崩溃文件,它再次位于 /var/crash 中
$ cd /var/crash/
$ ls
201902261006 kexec_cmd
$ cd 201902261006/
虽然在打开崩溃文件之前,您可能应该安装内核的源代码包
$ sudo apt source linux-image-`uname -r`
早些时候,您安装了 Linux 内核的调试版本,其中包含此类调试分析所需的未剥离调试符号。现在您需要该内核。使用 crash 实用程序打开内核崩溃文件
$ sudo crash dump.201902261006 /usr/lib/debug/
↪vmlinux-4.9.0-8-amd64
一旦所有内容加载完毕,屏幕上将出现崩溃摘要
KERNEL: /usr/lib/debug/vmlinux-4.9.0-8-amd64
DUMPFILE: dump.201902261006 [PARTIAL DUMP]
CPUS: 4
DATE: Tue Feb 26 10:07:21 2019
UPTIME: 00:04:09
LOAD AVERAGE: 0.00, 0.00, 0.00
TASKS: 100
NODENAME: deb-panic
RELEASE: 4.9.0-8-amd64
VERSION: #1 SMP Debian 4.9.144-3 (2019-02-02)
MACHINE: x86_64 (2592 Mhz)
MEMORY: 4 GB
PANIC: "sysrq: SysRq : Trigger a crash"
PID: 563
COMMAND: "tee"
TASK: ffff88e69628c080 [THREAD_INFO: ffff88e69628c080]
CPU: 2
STATE: TASK_RUNNING (SYSRQ)
请注意崩溃的原因:sysrq: SysRq : Trigger a crash。另请注意导致崩溃的命令:tee。由于是您触发了它,因此这些都不应令人惊讶。
如果您运行导致崩溃的内核函数的反向追踪,您应该看到以下内容(由 CPU 核心编号 2 处理)
crash> bt
PID: 563 TASK: ffff88e69628c080 CPU: 2 COMMAND: "tee"
#0 [ffffa67440b23ba0] machine_kexec at ffffffffa0c53f68
#1 [ffffa67440b23bf8] __crash_kexec at ffffffffa0d086d1
#2 [ffffa67440b23cb8] crash_kexec at ffffffffa0d08738
#3 [ffffa67440b23cd0] oops_end at ffffffffa0c298b3
#4 [ffffa67440b23cf0] no_context at ffffffffa0c619b1
#5 [ffffa67440b23d50] __do_page_fault at ffffffffa0c62476
#6 [ffffa67440b23dc0] page_fault at ffffffffa121a618
[exception RIP: sysrq_handle_crash+18]
RIP: ffffffffa102be62 RSP: ffffa67440b23e78 RFLAGS: 00010282
RAX: ffffffffa102be50 RBX: 0000000000000063 RCX: 0000000000000000
RDX: 0000000000000000 RSI: ffff88e69fd10648 RDI: 0000000000000063
RBP: ffffffffa18bf320 R8: 0000000000000001 R9: 0000000000007eb8
R10: 0000000000000001 R11: 0000000000000001 R12: 0000000000000004
R13: 0000000000000000 R14: 0000000000000000 R15: 0000000000000000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#7 [ffffa67440b23e78] __handle_sysrq at ffffffffa102c597
#8 [ffffa67440b23ea0] write_sysrq_trigger at ffffffffa102c9db
#9 [ffffa67440b23eb0] proc_reg_write at ffffffffa0e7ac00
#10 [ffffa67440b23ec8] vfs_write at ffffffffa0e0b3b0
#11 [ffffa67440b23ef8] sys_write at ffffffffa0e0c7f2
#12 [ffffa67440b23f38] do_syscall_64 at ffffffffa0c03b7d
#13 [ffffa67440b23f50] entry_SYSCALL_64_after_swapgs at ffffffffa121924e
RIP: 00007f3952463970 RSP: 00007ffc7f3a4e58 RFLAGS: 00000246
RAX: ffffffffffffffda RBX: 0000000000000002 RCX: 00007f3952463970
RDX: 0000000000000002 RSI: 00007ffc7f3a4f60 RDI: 0000000000000003
RBP: 00007ffc7f3a4f60 R8: 00005648f508b610 R9: 00007f3952944480
R10: 0000000000000839 R11: 0000000000000246 R12: 0000000000000002
R13: 0000000000000001 R14: 00005648f508b530 R15: 0000000000000002
ORIG_RAX: 0000000000000001 CS: 0033 SS: 002b
在您的反向追踪中,您应该注意到存储在您的返回指令指针 (RIP) 中的符号地址:ffffffffa102be62。让我们看一下这个符号地址
crash> sym ffffffffa102be62
ffffffffa102be62 (t) sysrq_handle_crash+18 ./debian/build/
↪build_amd64_none_amd64/./drivers/tty/sysrq.c: 144
等一下!异常似乎是在 drivers/tty/sysrq.c 文件的第 144 行 *以及* sysrq_handle_crash 函数内部触发的。嗯...我想知道这个内核源文件中发生了什么。(这就是为什么我让您在稍早前安装了内核源代码包。)让我们导航到 /usr/src 目录并解压源代码包
$ cd /usr/src
$ ls
linux_4.9.144-3.debian.tar.xz linux_4.9.144.orig.tar.xz
↪linux-headers-4.9.0-8-common
linux_4.9.144-3.dsc linux-headers-4.9.0-8-amd64
↪linux-kbuild-4.9
$ sudo tar xJf linux_4.9.144.orig.tar.xz
$ vim linux-4.9.144/drivers/tty/sysrq.c
找到 sysrq_handle_crash 函数
static void sysrq_handle_crash(int key)
{
char *killer = NULL;
/* we need to release the RCU read lock here,
* otherwise we get an annoying
* 'BUG: sleeping function called from invalid context'
* complaint from the kernel before the panic.
*/
rcu_read_unlock();
panic_on_oops = 1; /* force panic */
wmb();
*killer = 1;
}
更具体地说,查看第 144 行
*killer = 1;
正是这一行导致了反向追踪的第 6 行中记录的页面错误
#6 [ffffa67440b23dc0] page_fault at ffffffffa121a618
好的。所以,现在您应该对如何调试糟糕的内核代码有了基本的了解,但是如果您想调试您自己的自定义内核模块(例如,驱动程序)会发生什么?我编写了一个简单的 Linux 内核模块,它在加载时基本上调用了类似风格的内核崩溃。将其命名为 test-module.c 并将其保存在您主目录中的某个位置
#include <linux/init.h>
#include <linux/module.h>
#include <linux/version.h>
static int test_module_init(void)
{
int *p = 1;
printk("%d\n", *p);
return 0;
}
static void test_module_exit(void)
{
return;
}
module_init(test_module_init);
module_exit(test_module_exit);
您需要一个 Makefile 来编译此内核模块(将其保存在同一目录中)
obj-m += test-module.o
all:
$(MAKE) -C/lib/modules/$(shell uname -r)/build M=$(PWD)
运行 make 命令来编译模块,并且 *不要* 删除任何编译工件;您稍后会需要它们
$ make
make -C/lib/modules/4.9.0-8-amd64/build M=/home/petros
make[1]: Entering directory '/usr/src/
↪linux-headers-4.9.0-8-amd64'
CC [M] /home/petros/test-module.o
/home/petros/test-module.c: In function "test_module_init":
/home/petros/test-module.c:7:11: warning: initialization makes
↪pointer from integer without a cast [-Wint-conversion]
int *p = 1;
^
Building modules, stage 2.
MODPOST 1 modules
LD [M] /home/petros/test-module.ko
make[1]: Leaving directory '/usr/src/
↪linux-headers-4.9.0-8-amd64'
注意:您可能会看到编译警告。暂时忽略它。此警告将是触发内核崩溃的原因。
现在要小心。一旦您加载 .ko 文件,系统将崩溃,因此请确保所有内容都已保存并同步到磁盘
$ sync && sudo insmod test-module.ko
与之前类似,系统将崩溃,kexec 内核/环境将帮助收集所有内容并将其保存在 /var/crash 中的某个位置,然后自动重启。在您重启并返回到功能状态后,找到新的崩溃目录并进入它
$ cd /var/crash/201902261035/
此外,将您的 test-module 的未剥离内核目标文件从您的主目录复制到当前工作目录中
$ sudo cp ~/test.o /var/crash/201902261035/
使用您的调试内核加载崩溃文件
$ sudo crash dump.201902261035 /usr/lib/debug/
↪vmlinux-4.9.0-8-amd64
您的摘要应如下所示
KERNEL: /usr/lib/debug/vmlinux-4.9.0-8-amd64
DUMPFILE: dump.201902261035 [PARTIAL DUMP]
CPUS: 4
DATE: Tue Feb 26 10:37:47 2019
UPTIME: 00:11:16
LOAD AVERAGE: 0.24, 0.06, 0.02
TASKS: 102
NODENAME: deb-panic
RELEASE: 4.9.0-8-amd64
VERSION: #1 SMP Debian 4.9.144-3 (2019-02-02)
MACHINE: x86_64 (2592 Mhz)
MEMORY: 4 GB
PANIC: "BUG: unable to handle kernel NULL pointer
↪dereference at 0000000000000001"
PID: 1493
COMMAND: "insmod"
TASK: ffff893c5a5a5080 [THREAD_INFO: ffff893c5a5a5080]
CPU: 3
STATE: TASK_RUNNING (PANIC)
内核崩溃的原因总结如下:BUG: unable to handle kernel NULL pointer dereference at 0000000000000001。导致崩溃的用户空间命令是您的 insmod。
反向追踪将揭示地址 ffffffffc05ed005 的页面错误异常
crash> bt
PID: 1493 TASK: ffff893c5a5a5080 CPU: 3 COMMAND: "insmod"
#0 [ffff9dcd013b79f0] machine_kexec at ffffffffa3a53f68
#1 [ffff9dcd013b7a48] __crash_kexec at ffffffffa3b086d1
#2 [ffff9dcd013b7b08] crash_kexec at ffffffffa3b08738
#3 [ffff9dcd013b7b20] oops_end at ffffffffa3a298b3
#4 [ffff9dcd013b7b40] no_context at ffffffffa3a619b1
#5 [ffff9dcd013b7ba0] __do_page_fault at ffffffffa3a62476
#6 [ffff9dcd013b7c10] page_fault at ffffffffa401a618
[exception RIP: init_module+5]
RIP: ffffffffc05ed005 RSP: ffff9dcd013b7cc8 RFLAGS: 00010246
RAX: 0000000000000000 RBX: 0000000000000000 RCX: 0000000000000000
RDX: 0000000080000000 RSI: ffff893c5a5a5ac0 RDI: ffffffffc05ed000
RBP: ffffffffc05ed000 R8: 0000000000020098 R9: 0000000000000006
R10: 0000000000000000 R11: ffff893c5a4d8100 R12: ffff893c5880d460
R13: ffff893c56500e80 R14: ffffffffc05ef000 R15: ffffffffc05ef050
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#7 [ffff9dcd013b7cc8] do_one_initcall at ffffffffa3a0218e
#8 [ffff9dcd013b7d38] do_init_module at ffffffffa3b81531
#9 [ffff9dcd013b7d58] load_module at ffffffffa3b04aaa
#10 [ffff9dcd013b7e90] SYSC_finit_module at ffffffffa3b051f6
#11 [ffff9dcd013b7f38] do_syscall_64 at ffffffffa3a03b7d
#12 [ffff9dcd013b7f50] entry_SYSCALL_64_after_swapgs at ffffffffa401924e
RIP: 00007f124662c469 RSP: 00007fffc4ca04a8 RFLAGS: 00000246
RAX: ffffffffffffffda RBX: 0000564213d111f0 RCX: 00007f124662c469
RDX: 0000000000000000 RSI: 00005642129d3638 RDI: 0000000000000003
RBP: 00005642129d3638 R8: 0000000000000000 R9: 00007f12468e3ea0
R10: 0000000000000003 R11: 0000000000000246 R12: 0000000000000000
R13: 0000564213d10130 R14: 0000000000000000 R15: 0000000000000000
ORIG_RAX: 0000000000000139 CS: 0033 SS: 002b
让我们尝试查看地址 ffffffffc05ed005 处的符号
crash> sym ffffffffc05ed005
ffffffffc05ed005 (t) init_module+5 [test-module]
嗯。问题发生在 test-module 内核驱动程序的模块初始化代码中的某个位置。但是早期分析中显示的所有细节都发生了什么?好吧,由于此代码不是调试内核映像的一部分,因此您需要找到一种方法将其加载到您的崩溃分析中。这就是为什么我指示您将未剥离的目标文件复制到您当前的工作目录中。现在是加载模块目标文件的时候了
crash> mod -s test ./test.o
MODULE NAME SIZE OBJECT FILE
ffffffffc05ef000 test 16384 ./test.o
现在您可以返回并查看相同的符号地址
crash> sym ffffffffc05ed005
ffffffffc05ed005 (T) init_module+5 [test-module]
↪/home/petros/test-module.c: 8
现在是时候重新查看您的代码并查看第 8 行了
$ sed -n 8p test.c
printk("%d\n", *p);
就是这样。当您尝试打印定义不佳的指针时,发生了页面错误。还记得早期的编译警告吗?好吧,它警告您是有原因的,在当前情况下,它是触发内核崩溃的原因。在未来的编码案例中,您可能不会这么幸运。
您还能在这里做什么?内核崩溃文件将在崩溃事件中保留您系统的许多工件。您可以使用 help 命令列出可用命令的简短摘要
crash> help
* files mach repeat timer
alias foreach mod runq tree
ascii fuser mount search union
bt gdb net set vm
btop help p sig vtop
dev ipcs ps struct waitq
dis irq pte swap whatis
eval kmem ptob sym wr
exit list ptov sys q
extend log rd task
例如,如果您想查看内存利用率的总体摘要
crash> kmem -i
PAGES TOTAL PERCENTAGE
TOTAL MEM 979869 3.7 GB ----
FREE 835519 3.2 GB 85% of TOTAL MEM
USED 144350 563.9 MB 14% of TOTAL MEM
SHARED 8374 32.7 MB 0% of TOTAL MEM
BUFFERS 3849 15 MB 0% of TOTAL MEM
CACHED 0 0 0% of TOTAL MEM
SLAB 5911 23.1 MB 0% of TOTAL MEM
TOTAL SWAP 1047807 4 GB ----
SWAP USED 0 0 0% of TOTAL SWAP
SWAP FREE 1047807 4 GB 100% of TOTAL SWAP
COMMIT LIMIT 1537741 5.9 GB ----
COMMITTED 16370 63.9 MB 1% of TOTAL LIMIT
如果您想查看 dmesg 在故障发生时记录的内容
crash> log
[ 0.000000] Linux version 4.9.0-8-amd64
↪(debian-kernel@lists.debian.org) (gcc version 6.3.0
↪20170516 (Debian 6.3.0-18+deb9u1) ) #1 SMP Debian
↪4.9.144-3 (2019-02-02)
[ 0.000000] Command line: BOOT_IMAGE=/boot/
↪vmlinuz-4.9.0-8-amd64 root=UUID=bd76b0fe-9d09-40a9-
↪a0d8-a7533620f6fa ro quiet crashkernel=128M
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x001:
↪'x87 floating point registers'
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x002:
↪'SSE registers'
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x004:
↪'AVX registers'
[ 0.000000] x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]:
↪256
[ .... ]
使用相同的 crash 实用程序,您可以更深入地钻研内存位置及其内容,以及每个 CPU 核心在崩溃时正在处理的内容等等。如果您想了解有关这些功能的更多信息,只需键入 help 后跟函数名称
crash> help mount
类似于手册页的内容将加载到您的屏幕上。
总结所以,这就是您所拥有的:内核崩溃调试的介绍。本文仅触及皮毛,但希望它将为您提供一个合适的起点,以帮助诊断生产、开发和测试环境中的内核崩溃。

Petros Koutoupis,LJ 特约编辑,目前是 Cray 公司 Lustre 高性能文件系统部门的资深性能软件工程师。他还是 RapidDisk 项目的创建者和维护者。Petros 在数据存储行业工作了十多年,并帮助开创了当今广泛应用的许多技术。






