
IBM InfoSphere Streams 和乌普萨拉大学空间天气项目
2006 年,国际天文联合会 (IAU) 决定冥王星不再是行星,而是矮行星。然后在 2008 年,同一个组织决定冥王星是类冥矮行星而不是矮行星。今年,国际天文联合会于 8 月 3 日至 14 日在巴西举行会议,虽然在撰写本文时,会议尚未举行,但预计冥王星的官方头衔将再次被提出。
关于冥王星的最大问题之一是我们对它了解的信息不足。除了遥远的图像和行为观察之外,我们对冥王星的大部分信息都是数学上的猜测。然而,如果我们把焦点转向太阳系的另一边,困境就会逆转。我们可以收集到的关于太阳的信息量如此之大,以至于很难捕捉到它,更不用说对这些数据做任何有用的事情了。
2008 年 1 月 8 日,太阳周期 24 开始了。虽然这对大多数人来说似乎微不足道,但在大约三年后,它将达到顶峰(图 1)。太阳风暴,或称空间天气,会对现代社会产生非常重大的影响。这些看不见的爆发可能会摧毁卫星,破坏电网并关闭无线电通信。我们无法避免太阳风暴;然而,早期探测将有可能最大限度地减少影响。而这正是瑞典乌普萨拉大学的研究人员正在努力做的事情。
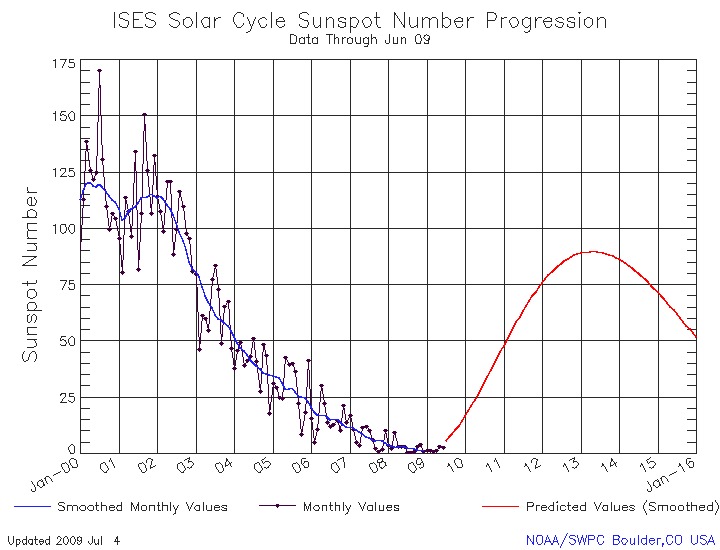
图 1. 我们正处于这个太阳周期的开始阶段,这使得早期探测尤为重要。(图片来源:美国国家海洋和大气管理局,www.noaa.org)
问题在于数字无线电接收器正在收集的数据量——准确地说,大约 6GB 的原始数据,每秒。没有办法存储所有数据以供以后分析,因此乌普萨拉大学与 IBM 及其 InfoSphere Streams 软件合作,实时分析数据。
LJ 副编辑 Mitch Frazier 和我有机会与 IBM 和乌普萨拉大学进行了交谈,我们向他们询问了更多关于如何完成这项壮举的信息。我们听到“使用 Linux”并不感到惊讶。以下是我们的问答环节,其中穿插了我的一些评论。
Shawn & Mitch: 它运行在什么硬件上?
IBM & 乌普萨拉大学:InfoSphere Streams 旨在在各种平台上工作,包括 IBM 硬件。它运行多达 125 个多核 x86 服务器集群,并搭载红帽企业 Linux (RHEL)。正在进行的 IBM 研究项目 System S 是 InfoSphere Streams 的基础,并且已经在许多平台上运行,包括 Blue Gene 超级计算机和 System P。
S&M: 它可以在通用硬件上运行吗?
I&U:是的,x86 刀片服务器。
S&M: 它运行在什么操作系统上?
I&U:InfoSphere Streams 在用于 32 位 x86 硬件的 RHEL 4.4 和用于 64 位 x86 硬件的 RHEL 5.2 上运行。
S&M: 这些操作系统是标准版本还是定制版本?
I&U:它们是标准操作系统。
S&M: 它用什么语言编写?
I&U:InfoSphere Streams 是用 C 和 C++ 编写的。
S&M: 程序员如何与它交互?通过正常的编程语言还是某种自定义语言?
I&U:InfoSphere Streams 的应用程序是用一种名为 SPADE(流处理应用程序声明式引擎)的语言编写的。SPADE 由 IBM 研究院开发,是一种编程语言和编译基础设施,专门为流式系统构建。它旨在促进大型流式应用程序的编程,以及它们到各种目标架构的高效和有效映射,包括集群、多核架构和特殊处理器,例如 Cell 处理器。SPADE 编程语言允许使用对应用程序有意义的最细粒度的运算符编写流处理应用程序,并且 SPADE 编译器适当地融合运算符并生成要在 Streams Runtime 上运行的流处理图。
[有关 SPADE 的示例,请参见列表 1。列表 1 摘自 Martin Hirzel、Henrique Andrade、Bugra Gedik、Vibhore Kumar、Giuliano Losa、Robert Soulé 和 Kun-Lung Wu 在 IBM 研究部门托马斯·J·沃森研究中心撰写的“IBM 研究报告—SPADE 语言规范”。]
列表 1. SPADE 中的 VWAP 应用程序示例。VWAP,或“成交量加权平均价格”,是金融交易中的常见计算。
composite VWAP {
param
expression<set<string>> $monitoredTickers :
{ "IBM", "GOOG", "MSFT" };
type
TradeInfoT = decimal64 price, decimal64 volume;
QuoteInfoT = decimal64 bidprice,
decimal64 askprice, decimal64 asksize;
TradeQuoteT = TradeInfoT, QuoteInfoT,
tuple<string ticker, string dayAndTime, string ttype>;
TradeFilterT = TradeInfoT, tuple<timestamp ts, string ticker>;
QuoteFilterT = QuoteInfoT, tuple<timestamp ts, string ticker>;
VwapT = string ticker, decimal64 minprice,
decimal64 maxprice, decimal64 avgprice,
decimal64 vwap;
graph
stream<TradeQuoteT> TradeQuote = FileSource() {
param fileName : "TradesAndQuotes.csv.gz";
format : csv, compressed, nodelays;
columns : irange(1,3), 5, irange(7,9), [11, 15, 16];
}
stream<TradeFilterT> TradeFilter = Functor(TradeQuote) {
param filter : ttype == "Trade"
&& (ticker in $monitoredTickers);
output TradeFilter : ts = timeStringToTimestamp(dayAndTime);
}
stream<QuoteFilterT> QuoteFilter = Functor(TradeQuote) {
param filter : ttype == "Quote"
&& (ticker in $monitoredTickers);
}
stream<VwapT, tuple<decimal64 sumvolume>>
PreVwap = Aggregate(TradeFilter)
{
window TradeFilter : sliding, count(4), count(1);
param groupBy : ticker;
perGroup : true;
output PreVwap : ticker = Any(ticker),
vwap = Sum(price*volume),
minprice = Min(price),
maxprice = Max(price),
avgprice = Avg(price),
sumvolume = Sum(volume);
}
stream<VwapT> Vwap = Functor(PreVwap) {
output Vwap : vwap = vwap / sumvolume;
}
stream<timestamp ts, decimal64 index>
BargainIndex = Join(Vwap as V; QuoteFilter as Q)
{
window V : sliding, count(1);
Q : sliding, count(0);
param equalityLHS : V.ticker; // can also be written
// as nested loop join:
equalityRHS : Q.ticker; // "condition: V.ticker==Q.ticker"
perGroupLHS : true;
output BargainIndex :
index = vwap > askprice*100.0
? asksize*exp(vwap-askprice*100.0)
: 0.0;
}
() = PerfSink(BargainIndex) { }
pragma
debugLevel: trace;
}
S&M: 它是否有非技术用户界面,还是所有接口都由程序员完成?
I&U:目前,InfoSphere Streams 没有面向开发人员的非技术用户界面。
IBM 研究院正在开展一个项目,旨在提供非技术用户界面,以允许业务分析师根据他们正在寻找的信息生成和运行程序。该项目名为 Mashup Automation with Run-time Invocation and Orchestration (MARIO,domino.research.ibm.com/comm/research_projects.nsf/pages/semanticweb.Semantic%20Web%20Projects.html)。
MARIO 允许业务用户通过指定信息目标来自动化组合,这些信息目标以所需流程输出的高级语义描述来表示。MARIO 使用现有的信息定义和可用的信息源来生成可能生成所需信息目标的应用程序。选择最佳应用程序,部署到运行时,然后将请求的信息结果显示给用户。
S&M: 数据是被捕获和分析还是仅被分析?
I&U:流计算的优势克服了与传统分析相关的难题,传统分析速度慢、不灵活(就它可以分析的数据类型而言),并且不适合从时间敏感事件(例如跟踪流行病或金融交易)中捕获见解。借助 InfoSphere Streams,可以捕获和分析数据,也可以仅分析数据。可以分析信息并将数据存储在文件或数据库中,或者发送到其他系统进行存储。摘要数据和模型也可以保存和存储。例如,一个分析水听器数据以研究海洋哺乳动物种群的应用程序不会捕获和存储无休止的音频,而只会捕获结果模型。该模型包括海洋哺乳动物访问的次数、频率和持续时间。
S&M: 它是开源的吗?
I&U:不,InfoSphere Streams 不是开源代码。
[Shawn 注:我承认,这几乎让我放弃了。当我联系我的 IBM 代表时,我正要拿出我的肥皂箱。事实证明,虽然 InfoSphere Streams 不是开源的,但 IBM 实际上为开源社区做出了巨大贡献。我被温和地提醒,IBM 是主要的内核贡献者,每年在开源开发方面投资约 1 亿美元,并且“回报”它从中受益匪浅的社区。我仍然希望 InfoSphere Streams 成为一个开源项目;但是,我想只要 IBM 遵守 GPL 并成为开源社区的优秀成员,我就会把我的肥皂箱收起来。]
S&M: InfoSphere Streams 为组织带来什么价值(换句话说,为什么有人会购买它)?
I&U:随着世界变得越来越互联互通和仪器化,数据量呈爆炸式增长——而且不仅仅是数据库中找到的结构化数据,还有从电子传感器、网页、电子邮件、音频和视频中捕获的非结构化、不兼容的数据。InfoSphere Streams 能够实时分析海量数据,提供极速、准确的见解。这些见解能够实现更明智的业务决策,并最终帮助企业实现差异化并获得竞争优势。
[Shawn 注:好吧,我明白了。我相信 InfoSphere Streams 不仅仅是一堆 Perl 脚本。在这一点上,我们很想更多地了解这个空间项目本身。]
S&M: 项目名称是什么?
I&U:瑞典空间物理研究所实时高频无线电天气统计和预报。为了将该项目置于背景中,它是斯堪的纳维亚 LOIS 项目 (www.lois-space.net) 的一部分,而 LOIS 项目又是主要的欧洲项目 LOFAR (www.lofar.org) 的衍生项目。
S&M: 项目的目标是什么?
I&U:乌普萨拉大学正在使用 InfoSphere Streams 分析海量的实时数据,以更好地了解空间天气。
科学家使用高频无线电传输来研究空间天气或电离层中等离子体的影响,这可能会影响电力线上的能量传输、通过无线电和电视信号进行的通信、航空和航天旅行以及卫星。然而,最近新传感器技术和天线阵列的出现意味着科学家收集的信息量超过了智能分析它的能力。
InfoSphere Streams 项目的最终目标是建模和预测我们大气层最上层及其对周围空间和太阳事件的反应的行为。这项工作可能对未来在太空和地球上的科学实验产生持久的影响。凭借预测等离子云在太空中如何移动的独特能力,可以做出新的努力来最大限度地减少能量爆发造成的损害或改变敏感卫星、电网或通信系统。
S&M: 它目前正在运行吗?
I&U:新一代高速软件定义三轴数字无线电传感器已经制造出来,并且正在测试作为该项目的一部分进行部署。InfoSphere Streams 软件目前正在为这种新硬件进行更新,预计将在 2009 年 9 月/10 月与新传感器一起部署。在购买新传感器之前,该项目已经启动并运行。
S&M: 正在分析什么类型的数据?
I&U:来自网络传感器和天线的大量结构化和非结构化数据正在作为该项目的一部分进行分析。通过使用 IBM InfoSphere Streams 分析来自跟踪高频无线电波的传感器的数据,可以动态捕获和分析海量数据。在接下来的一年中,预计该项目将执行至少每秒 6GB 或每小时 21.6TB 的分析。该技术通过在数据流式传输时立即对其进行分析和过滤来解决这个问题,帮助研究人员识别出百分之一的临界部分,而其余部分则被过滤掉作为噪声。通过使用可视化软件包,科学家可以对数据流执行查询,以仔细查看有趣的事件,从而使他们不仅可以预测,还可以“即时预测”几个小时后的事件。这将有助于预测,例如,太阳上的磁暴是否会在 18-24 小时内到达地球。
S&M:用于捕获数据的是什么类型的硬件?
I&U:该项目使用三轴电偶极子天线(通常称为三极天线)和三轴磁环天线(图 2)。

图 2. 乌普萨拉大学项目的数据收集测试站之一。该站位于瑞典韦克舍。它包括三极天线和三通道数字传感器以及 GPS 天线和接收器。
S&M: 系统中使用的是什么类型的硬件?
I&U:除了用于收集天气数据的设备、用于将数据路由到 Streams 运行时的网络设备外,InfoSphere Streams 软件还在 4 核 x86 (Xeon) 系统上开发,但也可以移植到 IBM JS20 Blade Center (Power PC) 和联想 ThinkPad X200s 笔记本电脑。
S&M: 除了 InfoSphere Streams 之外,还使用了什么软件?
I&U:RHEL 和用 C 和 C++ 编写的自定义分析代码,以及一些遗留的 FORTRAN 代码。
S&M: 系统的用户界面是什么?
I&U:InfoSphere Streams 有一个基于浏览器的管理控制台来管理运行时。它允许人们部署作业,查看作业如何在运行时集群中的机器之间分布,查看性能详细信息以及许多其他管理运行时环境的功能。系统的输出可以流式传输到各种显示和仪表板应用程序,以可视化实时分析处理的结果(图 3 和图 4)。
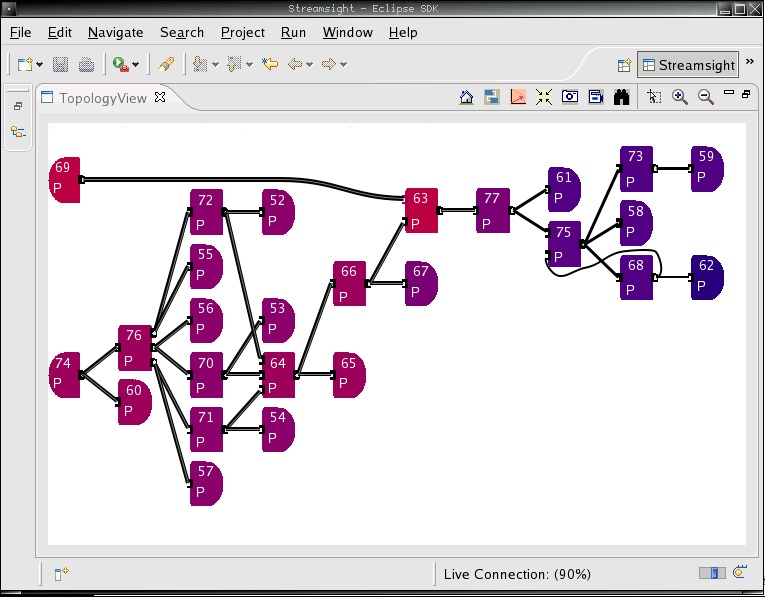
图 3. Streamsight 是正在运行的 InfoSphere Stream 的管理视图。它允许人们可视化各种任务在 Linux 集群中的哪些机器上运行、性能水平和其他信息。每个框代表正在运行的不同类型的分析,线条代表每个任务之间的数据流。
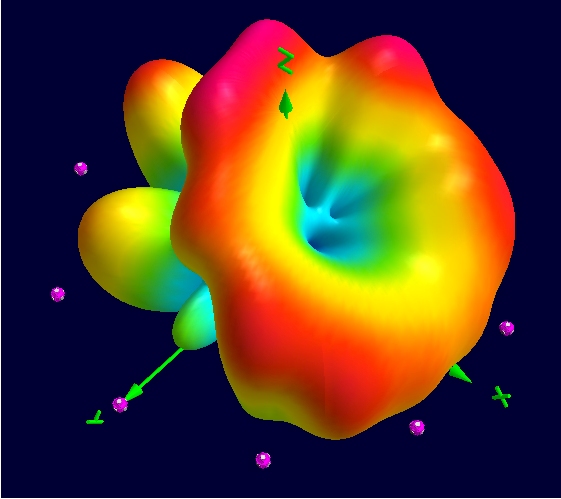
图 4. 在乌普萨拉瑞典空间物理研究所的模拟工作中发现的新型 3D 无线电模式的可视化。
S&M: 开发该系统花了多长时间?
I&U:空间天气应用程序是由乌普萨拉大学的一位博士生在几个月内开发的。更大的 LOIS 项目已经持续了八年。
S&M: 有多少开发人员/研究人员参与其中?
I&U:这位博士生得到了来自 LOIS 团队的四位科学家和一位研究工程师以及几位 IBM 研究人员的支持。
S&M: 空间天气软件是开源的吗?
I&U:否
[Shawn 注:是的,我们确实问了两次关于这些产品的开放程度。我们情不自禁。]
乌普萨拉空间天气项目是 Linux 如何用作使世界运转的底层引擎的一个典型例子。事实上,Linux 在此类项目中已经变得如此主流,以至于我们专门询问了该项目使用了什么基础设施。即便如此,答案也不是“Linux”,而是 Linux 的哪个版本。显然,项目应该在 Linux 环境中运行是显而易见的——我喜欢在世界上看到这种推测性的态度!
乌普萨拉大学收集和分析的信息是否会对我们如何应对太阳周期 24 产生影响还有待观察。至少,我们将拥有比历史上任何时候都更多的关于空间天气的数据。至于我们的小行星/矮行星/类冥矮行星冥王星,可悲的是,我们将不得不等到 2015 年 7 月 14 日才能获得更详细的信息。“新视野号”卫星正在那里竞速,以获取更多关于这个冰冷天体的信息。很难说当它到达那里时冥王星会被如何分类,但无论如何,我们将焦急地等待数据。当数据最终到达时,很可能数据将由 Linux 进行分析。
Shawn Powers 是 Linux Journal 的副编辑。他也是 LinuxJournal.com 的 Gadget Guy,并且他收藏了有趣的复古加菲猫咖啡杯。不要让他的傻发型迷惑你,他是一个非常普通的人,可以通过电子邮件 shawn@linuxjournal.com 联系到他。或者,在 Freenode.net 上访问 #linuxjournal IRC 频道。
