
路跑者超级计算机:千万亿次浮点运算不再是问题
1995 年,法国让全世界一片哗然。他们在南太平洋穆鲁罗瓦环礁进行的核装置试验引发了抗议、外交摩擦以及全球对法国餐厅的抵制。 感谢众多发展——其中包括 Linux、硬件和软件的进步以及众多聪明的人——物理测试已变得过时,法国美食也重新回到了菜单上。 这些发展体现在“路跑者”身上,它是目前世界上速度最快的超级计算机。 “路跑者”由 IBM 和洛斯阿拉莫斯国家实验室 (LANL) 创建,精确地模拟核爆炸以及我国老化的核武库的其他方面。

图 1. 洛斯阿拉莫斯国家实验室的路跑者团队部分成员
虽然核爆炸建模对于某些人来说是必要且有趣的,但名副其实的“路跑者”真正吸引人的特性是它的速度。 2008 年 5 月,“路跑者”完成了几乎令人难以置信的壮举——它以千万亿次浮点运算的速度运行。 我将为您省去在维基百科上查找这个词的时间:千万亿次浮点运算是每秒一千万亿(即一千兆亿)次浮点运算。 这比长期占据性能冠军宝座的劳伦斯利弗莫尔国家实验室的 IBM 478.2 万亿次浮点运算的“蓝色基因/L”系统快了一倍多。
除了千万亿次浮点运算的成就外,“路跑者”背后的故事在很多方面也同样令人难以置信。 “路跑者”的混合 Cell-Opteron 架构、其应用、其 Linux 和开源基础、其效率,以及将这些部件统一成一个高速单元的后勤保障等要素,构成了一个伟大的故事。 这期《Linux Journal》是高性能计算专刊,在这里讲述“路跑者”超级计算机背后的故事似乎再合适不过了。
“你想谈论挑战;处理如此大量的‘东西’的后勤保障就是挑战”,IBM“路跑者”首席工程师 Don Grice 说。 “后勤人员已经将其简化为一门科学。” 当您读到这篇文章时,“路跑者” 17 个部分中的最后一部分(包含 180 个计算节点——250 吨“东西”,装在 21 辆半挂卡车上)将离开 IBM 位于纽约州波基普西的工厂,运往位于新墨西哥州的洛斯阿拉莫斯国家实验室尼古拉斯·梅特罗波利斯中心。

图 2. 2007 年春季在洛斯阿拉莫斯国家实验室拍摄的“路跑者”(第一阶段测试版)的早期鸟瞰图
千万亿次浮点运算的成就是在“IBM 的地方”取得的,机器在那里被建造、测试和基准测试。 实际上,“路跑者”实现了 1.026 千万亿次浮点运算——仅仅比千万亿次浮点运算标记多出 26 万亿次浮点运算/秒。 “路跑者”的计算能力相当于当今 10 万台最快的笔记本电脑。
“路跑者”是 IBM 及其合作伙伴开展的最复杂的项目之一。 IBM 在两个不同的地点生产了“路跑者”的每个服务器刀片,并在第三个地点将它们组装成所谓的“三刀片”。 然后,将三刀片运往波基普西,成为“路跑者”的一部分。 尽管存在这种后勤障碍,但该项目仍按计划和预算完成。
IBM 还必须为整个互连结构寻找合作伙伴,使其规模化并获得所需的性能。 该公司还与各种 Linux 和其他开源社区合作,构建了一个连贯的软件堆栈。 之前担心 Emcore、Flextronics、Mellanox 和 Voltaire 等合作伙伴之间的高度协调不会奏效,但事实证明这种担心是没有根据的。 “他们都以一种非常、非常好的方式团结在一起”,Grice 说。 “这台机器的任何方面都没有不符合其预期用途的。”
当然,“路跑者”如此规模的项目需要 IBM 和 LANL 的许多聪明人,他们合作了六年时间来开发和建造它。 LANL 团队由 171 人组成,IBM 方面也有规模相似的团队。 “洛斯阿拉莫斯和 IBM 形成了非常紧密的合作伙伴关系”,LANL 项目负责人 Andy White 评论道。 “我们能够共同努力解决许多问题”,他补充道。
据 White 称,项目规划始于 2002 年,当时 LANL 决定追求带有加速器(最终选择了 Cell 处理器)的超级计算机,以满足其建模需求。 他们开始听说 Cell 处理器,并对其应用潜力很感兴趣。 LANL 确定它基本上想要一个非常大的 Linux 集群,并意识到借助加速器,他们可以达到千万亿次浮点运算。
IBM 和 LANL 共同致力于“路跑者”的总体设计; IBM 实现了代码——即混合系统的计算库 (ALF) 和算术软件 (DaCS)。 洛斯阿拉莫斯小组的任务是确保其应用程序可以在机器上运行。 系统建模小组花了一整年的时间分析其应用程序和机器的性能特征,以确保 LANL 的机密工作和各种有趣的科学应用程序都能很好地运行。 该小组构建了四个与其核物理建模相关的应用程序。 这些应用程序包括用于模拟热辐射传播的隐式蒙特卡罗 (IMC) 代码(Milagro 应用程序套件)、Sweep3D 内核、SpaSM 分子动力学代码和 VPIC 粒子和等离子体物理代码。 LANL 的 White 表示,这些应用程序是提出问题“我们能否对 [路跑者] 进行编程,我们能否在这个系统上获得加速性能?”的基础。
在让“路跑者”完成其工作方面,智力挑战不胜枚举。 其中一项挑战是证明上述应用程序可以在加速的“路跑者”上运行——而无需实际运行! 2006 年 9 月,IBM 向 LANL 交付了一个基本系统用于测试,但没有加速器。 应用程序可以在 Cell 处理器上进行测试,但不能在完整的节点或系统上进行测试。 White 解释说:
性能和架构实验室团队实际上能够对整个系统[配备加速]进行建模,并几乎准确地预测了代码在完整系统上运行时发生的情况。 我们能够在 10 月 [2007 年] 通过两次重要的技术评估,并向人们展示我们可以对机器进行编程,代码可以获得良好的加速,它们是加速的,我们可以管理机器等等,而无需实际拥有机器在手,我认为这是一项杰作。
另一项挑战涉及网络。 在 2006 年末和 2007 年初使用基本系统工作时,人们担心“路跑者”的计算能力会导致网络成为瓶颈。 因此,White 说,“节点在飞行中被重新设计”,新的节点将 Opteron 到 Cell 处理器的性能提高了 400%,并且相对于原始设计,网络性能也提高了 400%。 所有这些都是以相同的原始合同价格完成的。
耗资 1.1 亿美元的“路跑者”按计划完成,及时赶上 2008 年 6 月发布的全球最强大的计算机系统 Top 500 榜单。
您可能会惊讶地得知“路跑者” 100% 由商用部件构建而成。 其惊人性能的秘诀在于两个关键要素,即新型混合 Cell-Opteron 处理器架构和创新的软件设计。 Grice 强调,“路跑者”“是一件大规模的事情,但从根本上来说,它关乎软件”。
尽管如此,硬件特性仍然令人难以置信。 “路跑者”本质上是一个 Linux Opteron 节点集群的集群,通过 MPI 和并行文件系统连接。 它配备了 6,562 个 AMD 双核 Opteron 2210 1.8GHz 处理器和 12,240 个 IBM PowerXCell 8i 3.2GHz 处理器。 Opteron 的工作是管理标准处理,例如文件系统 I/O; Cell 处理器处理数学和 CPU 密集型任务。 例如,Cell 的八个向量引擎内核可以比通用内核更酷、更快、更便宜地完成算法加速。 “大多数人认为 [Cell 处理器] 有点难用,而且它只是一种游戏设备”,Grice 开玩笑说。 但是,Cell 显然不再仅仅用于游戏。 Cell 处理器使每个计算节点比仅使用 Opteron 快 30 倍。
LANL 的 White 进一步强调了“路跑者”混合架构的独特性,称其为“混合混合”,因为 Cell 处理器本身就是混合的。 这是因为 Cell 具有 PPU (PowerPC) 内核和八个 SPU。 由于 PPU 的“性能适中”(正如 LANL 的人礼貌地说),他们需要一个内核来运行无法在 SPU 上运行的代码并提高性能。 因此,Cell 连接到 Opteron。
该系统还配备了 98 TB 的内存,以及 10,000 个 InfiniBand 和千兆以太网连接,需要 55 英里的光纤电缆。 10GbE 用于连接到 2 PB 的外部存储。 278 个 IBM BladeCenter 机架占用了 5,200 平方英尺的空间。
该机器由独特的三刀片配置组成,包括一个双插槽双核 Opteron LS21 刀片服务器和两个双插槽 IBM QS22 Cell 刀片服务器。 尽管 Opteron 内核通过专用 PCIe 链路连接到每个 Cell 芯片,但节点到节点的通信是通过 InfiniBand 进行的。 3,456 个三刀片中的每一个都可以以 400 Gigaflops(每秒 4000 亿次运算)的速度运行。
有关三刀片的示意图,请参见图 3。
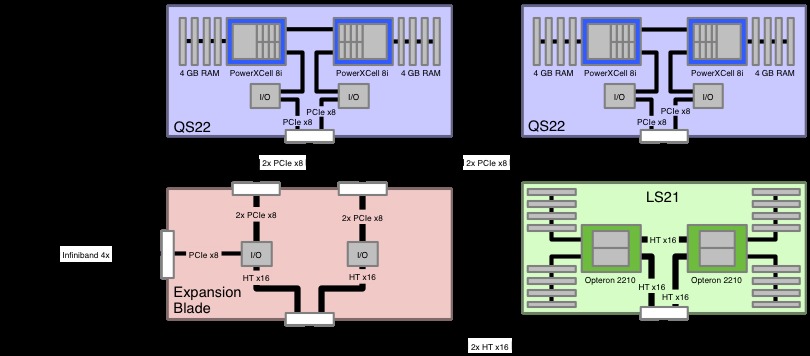
图 3. 混合 Opteron-Cell 架构体现在三刀片设置中。 三刀片允许 Opteron 执行标准处理,而 Cell 执行数学和 CPU 密集型任务。
混合三刀片架构在利用与前几代超级计算机相同的空间的同时,实现了性能的量子飞跃。 “路跑者”占用的空间和运行成本与其之前的两代机器 ASC Purple 和 ASC White 相同。 这是因为性能继续以每 10-11 年 1,000% 的可预测速度增长。 Grice 指出,仅三个“路跑者”三刀片就具有与 1998 年最快的计算机相同的功率。 换句话说,今天在“路跑者”上需要一周才能完成的计算,在一台 1998 年启动的旧的 1 万亿次浮点运算的机器上,只能完成一半。
如此巨大的性能飞跃帮助许多科学家感到震惊,他们看到自己的职业生涯在眼前发生变化。 如果他们今天有需要花费太长时间的计算,他们可以非常肯定,在两年内,计算将花费十分之一的时间。
IBM 的 Grice 和 LANL 的 White 都无法充分强调软件的重要性和复杂性,正是软件使得能够利用“路跑者”的硬件实力。 由于时钟频率和芯片功率已趋于平稳,摩尔定律将继续通过其他方式保持下去,例如“路跑者”的混合架构。
“路跑者”于 2008 年 5 月 23 日以完整配置组装完成。 5 月 26 日,它达到了千万亿次浮点运算。 “在组装完成仅三天后就达到千万亿次浮点运算的速度真是令人惊叹”,White 说。
显然,千万亿次浮点运算并非极限。 不仅最初的千万亿次浮点运算成就实际上是 1.026 千万亿次浮点运算,而且从那时起,“路跑者”的表现更出色。 2008 年 6 月,LANL 和 IBM 运行了一个名为 PetaVision Synthetic Cognition 的项目,这是一个大脑视觉皮层的模型,模拟了超过 10 亿个脑细胞和数万亿个突触。 它达到了 1.144 千万亿次浮点运算的标记。 像这样的计算是“路跑者”理想的千万亿次浮点运算级任务。
“很难过分强调看到我们能够用‘路跑者’完成的科学研究有多么令人兴奋”,White 说。 在 2009 年年中,“路跑者”的大部分节点将进入“机密”模式,在其剩余的生命周期内,只有授权人员才能知道它在做什么。 然而,科学家及其追随者会很高兴了解“路跑者”的一些非军事职责。 首先,在 2008 年 8 月,LANL 为“路跑者”订购了两个额外的连接单元,称为 Turquoise Network,根据 White 的说法,这些单元将可用并且“始终公开”。 这些单元应该在 2008 年 10 月之前运行。 此外,在 2009 年初“路跑者”进入机密状态之前,LANL 将利用其他几个所谓的非机密开放科学代码作为测试负载,作为“路跑者”稳定和集成过程的一部分。 已选择用于此目的的十个代码必须证明它们在“路跑者”上工作的能力。 虽然其中一些代码基于上述 VPIC 和 SPaSM,但其他代码是新的且未经测试的。 “其他人是否可以编写实际上可以在系统上运行的代码仍有待观察”,White 表示。
LANL 收到了 29 份访问“路跑者”的提案,其中两份与武器相关,八份与非武器相关。 精选的有趣项目示例包括使用原子力显微镜研究金属纳米线的形成、HIV 早期感染状态的系统发育以及最终的暗能量和物质。
虽然利用“路跑者”的强大功能的机会很诱人,但必须考虑进行额外的调整以利用混合架构。 “这可能很棘手”,White 说。 使用更传统的机器,代码从一个 Linux 集群到另一个 Linux 集群不需要太多更改。 幸运的是,对于那些提案已被接受的科学家,LANL 正在提供额外资金来支持混合架构的代码开发。 今年 12 月,LANL 将评估每个项目的进展,并根据这些结果在 2009 年初分配计算时间。
是的,我没有忘记提到“路跑者”运行在 Linux 上——确切地说,是 Red Hat。 从一开始,LANL 团队就知道他们想要 Linux,因为其使命的开放性以及它试图实现的目标。 IBM 的 Grice 补充说,LANL“一直对 Linux 的东西感兴趣,所以这是一个自然之选。 我们确实考虑过[其他操作系统],但我们没有认真考虑。”
从技术上讲,Linux 也很合适。 团队无需担心运行 Cell 处理器或 LS21 刀片服务器,可伸缩性也不是主要问题,因为它没有在节点级别下降。 相反,它关乎将所有节点一起使用,这意味着操作系统上的压力很小。 IBM 的 Linux 技术中心在使 Linux 在“路跑者”上工作方面发挥了重要作用。
除了 Linux 之外,Grice 还赞扬了其他开源社区的“巨大合作”。 他解释说,他们如何兴奋地投入到“路跑者”及其混合架构带来的独特挑战中,并超越了所有期望。 一些开源应用程序包括 Moab 调度程序和 Torque 资源管理器。
令 IBM 和 LANL 惊讶的是,大多数潜在的软件“问题”从未变成问题。 然而,开源带来的一个挑战是许多流并不总是彼此兼容。 因此,团队不得不在某些地方自我约束,在另一些地方进行试验,以保持与自身连贯的堆栈。 然而,结果令人满意,并且可以有效地扩展。
“各个独立的社区都团结在一起,然后作为一个整体堆栈锁定在一起,我认为这是一个精彩的故事”,Grice 说。
总的来说,“功率和冷却仅次于软件复杂性”,Grice 强调说。 功率是推动 HPC 向前发展的真正问题。 “路跑者”通过其设计的效率解决了这些问题。 特别是由于 Cell 处理器的效率,“路跑者”在满载运行 Linpack 时仅需要 2.3MW 的功率,每瓦特可提供世界领先的 4.37 亿次运算。 这一结果远好于 IBM 官方额定的满载 3.9MW。 如此高的效率使“路跑者”在最节能超级计算机 Green 500 榜单中名列第三。
否则,“路跑者”采用风冷,利用大型铜散热器和变速风扇。
尽管“路跑者”实现了进入千万亿次级计算的量子飞跃,但这仅仅是一个令人兴奋的趋势的开始。 IBM 的 Grice 谈到了欧洲为重振超级计算所做的努力,计划在 2010 年之前推出多台千万亿次级机器。 IBM 还在与洛斯阿拉莫斯国家实验室和桑迪亚国家实验室合作规划数百千万亿次级机器,其中包括计划于 2012 年或 2013 年交付的 5 千万亿次级机器。 “我们将在 11 年内拥有一台百亿亿次级机器”,Grice 补充道,“所以我们只需要弄清楚如何为其供电”。 这一趋势一直惊人地呈线性发展,并且鉴于混合计算的进步,这种情况很可能会持续下去。
“路跑者”也将提高人们的期望,混合计算将逐渐普及,使曾经不可能的事情成为可能。 气候变化科学家将为其模型添加更多要素,制药公司将模拟药物在体内的作用,好莱坞的特效将变得更加令人叹为观止。
随着这个未来的展开,IBM 和洛斯阿拉莫斯国家实验室的“路跑者”团队应该对他们建造了世界上最快的超级计算机——有史以来第一台千万亿次级机器——的成就充满信心。 这是在规划、硬件、软件和后勤保障方面取得的令人难以置信的成就,为超级计算设定了全球标准。 看看该团队接下来会取得什么成就将会很有趣。
资源
IBM 关于“路跑者”的情况说明书: www-03.ibm.com/press/us/en/pressrelease/24405.wss
洛斯阿拉莫斯国家实验室的“路跑者”主页: www.lanl.gov/orgs/hpc/roadrunner/index.shtml
Green 500 榜单: www.green500.org
James Gray 是 Linux Journal 产品编辑,也是密歇根州立大学环境科学与管理专业的研究生。 作为 20 世纪 90 年代中期以来的 Linux 爱好者,他目前与妻子和猫居住在密歇根州兰辛市。
