
使用 Slony-I 进行数据库复制
多年来,数据库管理系统一直是基础设施的关键组成部分。PostgreSQL 是一种先进的、对象关系型数据库管理系统,经常用于提供此类服务。尽管这种数据库管理系统多年来已被证明是稳定的,但两种可用的开源复制解决方案 rserv 和 ERServer 存在严重的局限性,需要更换。
幸运的是,最近出现了一个这样的替代方案。Slony-I 是 Jan Wieck 开发的 PostgreSQL 的基于触发器的主到多从复制系统。这种企业级复制解决方案以异步方式工作,并提供数据中心所需的所有关键功能。Slony-I 的主要使用场景包括
从总公司到各个分公司的数据库复制,以减少带宽使用或加快数据库请求速度。
数据库复制,以在所有实例中提供负载均衡。这对于报表生成器或动态网站尤其有用。
数据库复制,以提供数据库服务的高可用性。
使用备用服务器进行热备份或升级到新版本的 PostgreSQL。
本文将引导您完成安装 Slony-I 和复制位于同一台机器上的简单数据库所需的步骤。它还描述了如何将 Slony-I 与高可用性解决方案结合使用以提供自动故障转移。
要安装 Slony-I 并复制一个简单的数据库,首先从源代码安装 PostgreSQL。Slony-I 支持 PostgreSQL 7.3.2 或更高版本;7.4.x 和 8.0 在编译时需要 PostgreSQL 源代码树的位置。如果您喜欢使用来自您最喜欢的发行版的 PostgreSQL 软件包,只需从软件包源代码重建它们,并保持软件包构建位置完整,以便在编译 Slony-I 时可以使用。也就是说,获取最新的 Slony-I 版本 1.0.5,编译并安装它。为此,请执行以下命令
% tar -zxvf slony1-1.0.5.tar.gz % cd slony1-1.0.5 % ./configure \ --with-pgsourcetree=/usr/src/redhat/BUILD/postgresql-7.4.5 % make install
在本示例中,我们告诉 Slony-I 的配置脚本在 /usr/src/redhat/BUILD/postgresql-7.4.5/ 中查找 PostgreSQL 源代码的位置,这是在 Red Hat Enterprise Linux 上构建 PostgreSQL 7.4.5 RPM 时使用的目录。最后一个命令编译 Slony-I 并安装以下文件
$postgresql_bindir/slonik:Slony-I 的管理和配置脚本实用程序。slonik 是一个简单的工具,通常嵌入在 shell 脚本中,用于修改 Slony-I 复制系统。它支持自己的无格式命令语言,在《Slonik 命令摘要》文档中详细描述。
$postgresql_bindir/slon:主要的复制引擎。这个多线程引擎利用来自复制模式的信息与其他引擎通信,创建分布式复制系统。
$postgresql_libdir/slony1_funcs.so:C 函数和触发器。
$postgresql_libdir/xxid.so:用于安全存储事务 ID 的附加数据类型。
$postgresql_datadir/slony1_base.sql:复制模式。
$postgresql_datadir/slony1_base.v73.sql。
$postgresql_datadir/slony1_base.v74.sql。
$postgresql_datadir/slony1_funcs.sql:复制函数。
$postgresql_datadir/slony1_funcs.v73.sql。
$postgresql_datadir/slony1_funcs.v74.sql。
$postgresql_datadir/xxid.v73.sql:用于加载先前定义的附加数据类型的脚本。
通常,$postgresql_bindir 指向 /usr/bin/,$postgresql_libdir 指向 /usr/lib/pgsql/,$postgresql_datadir 指向 /usr/share/pgsql/。使用pg_config --configure命令来显示构建 PostgreSQL 时使用的参数,以查找您自己的安装的各种位置。这些文件是为 PostgreSQL 提供完整复制引擎所需的所有文件。
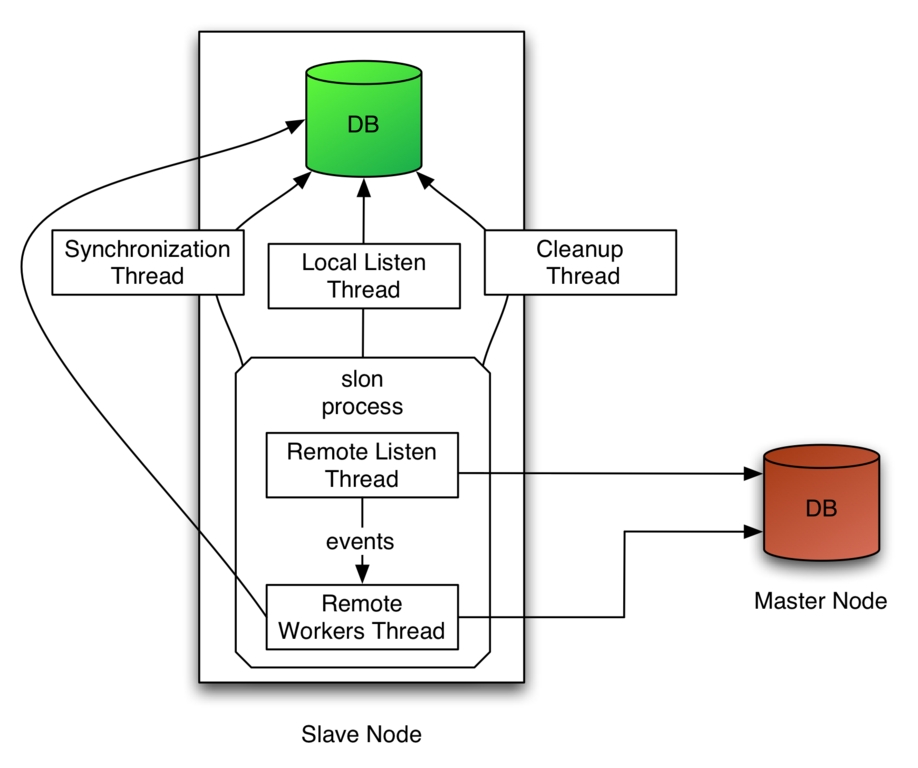
图 1. Slony-I 复制引擎如何为主库和从库数据库工作。
如图 1 所示,Slony-I 的主要复制引擎 slon 使用了许多线程。同步线程以可配置的时间间隔验证是否发生了可复制的数据库活动,如果发生此类活动,则生成 SYNC 事件。本地监听线程监听新的配置事件,并相应地修改集群配置和 slon 进程的内存配置。
顾名思义,清理线程对 Slony-I 模式执行维护,例如删除旧事件或清理表。远程监听线程连接到远程节点的数据库,以接收来自其事件提供者的事件。当它接收到事件或确认时,它会选择相应的信息并将其馈送到远程工作线程的内部消息队列。复制数据被组合成事务组。远程工作线程(每个远程节点一个)执行实际的数据复制、事件存储和确认生成。在任何时候,从库都确切地知道它已经消费了哪些事务组。
我们首先创建我们将要复制的数据库。此数据库包含单个表和序列。让我们创建一个用户 contactuser,contactdb 数据库,并通过执行以下命令为此新创建的 PostgreSQL 数据库激活 plpgsql 编程语言
% su - postgres % createuser --pwprompt contactuser Enter password for user "contactuser": (specify a password) Enter it again: Shall the new user be allowed to create databases? (y/ n) y Shall the new user be allowed to create more new users? (y/ n) n % createdb -O contactuser contactdb % createlang -U postgres -h localhost plpgsql \ contactdb
然后,我们在我们将要复制的数据库中创建序列和表,并在表中插入一些信息
% psql -U contactuser contactdb
contactdb=> create sequence contact_seq start with 1;
contactdb=> create table contact (
cid int4 primary key,
name varchar(50),
address varchar(255),
phonenumber varchar(15)
);
contactdb=> insert into contact (cid, name, address,
phonenumber) values ((select nextval('contact_seq')),
'Joe', '1 Foo Street', '(592) 471-8271');
contactdb=> insert into contact (cid, name, address,
phonenumber) values ((select nextval('contact_seq')),
'Robert', '4 Bar Roard', '(515) 821-3831');
contactdb=> \q
为了简单起见,让我们在同一系统上创建第二个数据库,我们将在其中复制来自 contactdb 数据库的信息。执行以下命令创建数据库,添加 plpgsql 编程语言支持,并从 contactdb 数据库导入不包含任何数据的模式
% su - postgres % createdb -O contactuser contactdb_slave % createlang -U postgres -h localhost plpgsql \ contactdb_slave % pg_dump -s -U postgres -h localhost contactdb | \ psql -U postgres -h localhost contactdb_slave
数据库创建完成后,我们就可以创建包含主库和单个从库的数据库集群了。创建 Slonik cluster_setup.sh 脚本并执行它。清单 1 显示了 cluster_setup.sh 脚本的内容。
清单 1. cluster_setup.sh
#!/bin/sh
CLUSTER=sql_cluster
DB1=contactdb
DB2=contactdb_slave
H1=localhost
H2=localhost
U=postgres
slonik <<_EOF_
cluster name = $CLUSTER;
node 1 admin conninfo = 'dbname=$DB1 host=$H1 user=$U';
node 2 admin conninfo = 'dbname=$DB2 host=$H2 user=$U';
init cluster (id = 1, comment = 'Node 1');
create set (id = 1, origin = 1,
comment = 'contact table');
set add table (set id = 1, origin = 1, id = 1,
full qualified name = 'public.contact',
comment = 'Table contact');
set add sequence (set id = 1, origin = 1, id = 2,
full qualified name = 'public.contact_seq',
comment = 'Sequence contact_seq');
store node (id = 2, comment = 'Node 2');
store path (server = 1, client = 2,
conninfo = 'dbname=$DB1 host=$H1 user=$U');
store path (server = 2, client = 1,
conninfo = 'dbname=$DB2 host=$H2 user=$U');
store listen (origin = 1, provider = 1, receiver = 2);
store listen (origin = 2, provider = 2, receiver = 1);
清单 1 的第一个 slonik 命令(集群名称)定义了所有 Slony-I 特定函数、过程、表和序列定义的命名空间。在 Slony-I 中,节点是数据库和 slon 进程的集合,集群是节点的集合,节点之间使用路径连接。然后,指定节点 1 和 2 的连接信息,并初始化第一个节点(init cluster)。完成后,脚本创建一个新的复制集,该复制集本质上是一个包含 public.contact 表和 public.contact_seq 序列的集合。创建集合后,脚本将 contact 表添加到其中,并将 contact_seq 序列添加到其中。store node 命令用于初始化第二个节点(id = 2)并将其添加到集群(sql_cluster)。完成后,脚本定义节点 2 的复制系统如何连接到节点 1,以及节点 1 如何连接到节点 2。最后,脚本告诉两个节点监听系统中每个其他节点的事件(store listen)。
脚本执行完毕后,启动 slon 复制进程。主节点和从节点都需要 slon 进程。对于我们的示例,我们在同一系统上启动两个所需的进程。slon 进程必须始终运行才能进行复制。如果由于某种原因必须停止它们,只需重新启动即可让它们从上次停止的地方继续。要启动复制引擎,请执行以下命令
% slon sql_cluster "dbname=contactdb user=postgres" & % slon sql_cluster "dbname=contactdb_slave user=postgres" &
接下来,我们需要订阅新创建的集合。订阅集合会导致第二个节点(订阅者)开始从第一个节点复制 contact 表和 contact_seq 序列的信息。清单 2 显示了订阅脚本的内容。
清单 2. subscribe.sh
#!/bin/sh CLUSTER=sql_cluster DB1=contactdb DB2=contactdb_slave H1=localhost H2=localhost U=postgres slonik <<_EOF_ cluster name = $CLUSTER; node 1 admin conninfo = 'dbname=$DB1 host=$H1 user=$U'; node 2 admin conninfo = 'dbname=$DB2 host=$H2 user=$U'; subscribe set (id = 1, provider = 1, receiver = 2, forward = yes);
与清单 1 非常相似,subscribe.sh 首先定义集群命名空间和两个节点的连接信息。完成后,subscribe set 命令使第一个节点开始使用 slon 进程将包含单个表和序列的集合复制到第二个节点。
subscribe.sh 脚本执行完毕后,连接到 contactdb_slave 数据库并检查 contact 表的内容。在任何时候,您都应该看到信息已正确复制
% psql -U contactuser contactdb_slave contactdb_slave=> select * from contact; cid | name | address | phonenumber -----+--------+--------------+---------------- 1 | Joe | 1 Foo Street | (592) 471-8271 2 | Robert | 4 Bar Roard | (515) 821-3831
现在,连接到 /contactdb/ 数据库并插入一行
% psql -U contact contactdb
contactdb=> begin; insert into contact (cid, name,
address, phonenumber) values
((select nextval('contact_seq')), 'William',
'81 Zot Street', '(918) 817-6381'); commit;
如果您再次检查 contactdb_slave 数据库的 contact 表的内容,您会注意到该行已被复制。现在,从 /contactdb/ 数据库中删除一行
contactdb=> begin; delete from contact where cid = 2; commit;
再次,通过检查 contactdb_slave 数据库的 contact 表的内容,您会注意到该行已从从节点正确删除。
与其手动比较 contactdb 和 contactdb_slave 的信息,我们还可以使用一个简单的脚本来自动化此过程,如清单 3 所示。可以定期执行这样的脚本,以确保所有节点都同步,并在不再同步时通知管理员。
清单 3. compare.sh
#!/bin/sh
CLUSTER=sql_cluster
DB1=contactdb
DB2=contactdb_slave
H1=localhost
H2=localhost
U=postgres
echo -n "Comparing the databases..."
psql -U $U -h $H1 $DB1 >dump.tmp.1.$$ <<_EOF_
select 'contact'::text, cid, name, address,
phonenumber from contact order by cid;
_EOF_
psql -U $U -h $H2 $DB2 >dump.tmp.2.$$ <<_EOF_
select 'contact'::text, cid, name, address,
phonenumber from contact order by cid;
_EOF_
if diff dump.tmp.1.$$ dump.tmp.2.$$ >dump.diff ; then
echo -e "\nSuccess! Databases are identical."
rm dump.diff
else
echo -e "\nFAILED - see dump.diff."
fi
rm dump.tmp.?.$$
尽管在同一系统上复制数据库用途不大,但此示例显示了这样做是多么容易。如果您想在位于不同计算机上的节点上试验复制系统,您只需修改清单 1 到 3 中的 DB2、H1 和 H2 环境变量。通常,DB2 将设置为与 DB1 相同的值,因此应用程序始终引用相同的数据库名称。主机环境变量需要设置为两个节点的完全限定域名。您还需要确保 slon 进程在两台计算机上都在运行。最后,最佳实践是使用 ntpd 或类似工具同步所有节点的时钟。
稍后,如果您想向初始复制集中添加更多表或序列,您可以创建一个新集合并使用 merge set slonik 命令。或者,您可以使用 set move table 和 set move sequence 命令来拆分集合。有关此方面的更多信息,请参阅《Slonik 命令摘要》。
如果主节点发生故障,例如由于操作系统崩溃或硬件问题,Slony-I 不提供任何自动将从节点提升为主节点的功能。这是有问题的,因为提升节点需要人工干预,并且需要高可用性数据库服务的应用程序不应依赖于此。幸运的是,有很多解决方案可以与 Slony-I 结合使用,以提供自动故障转移功能。Linux-HA Heartbeat 程序就是其中之一。
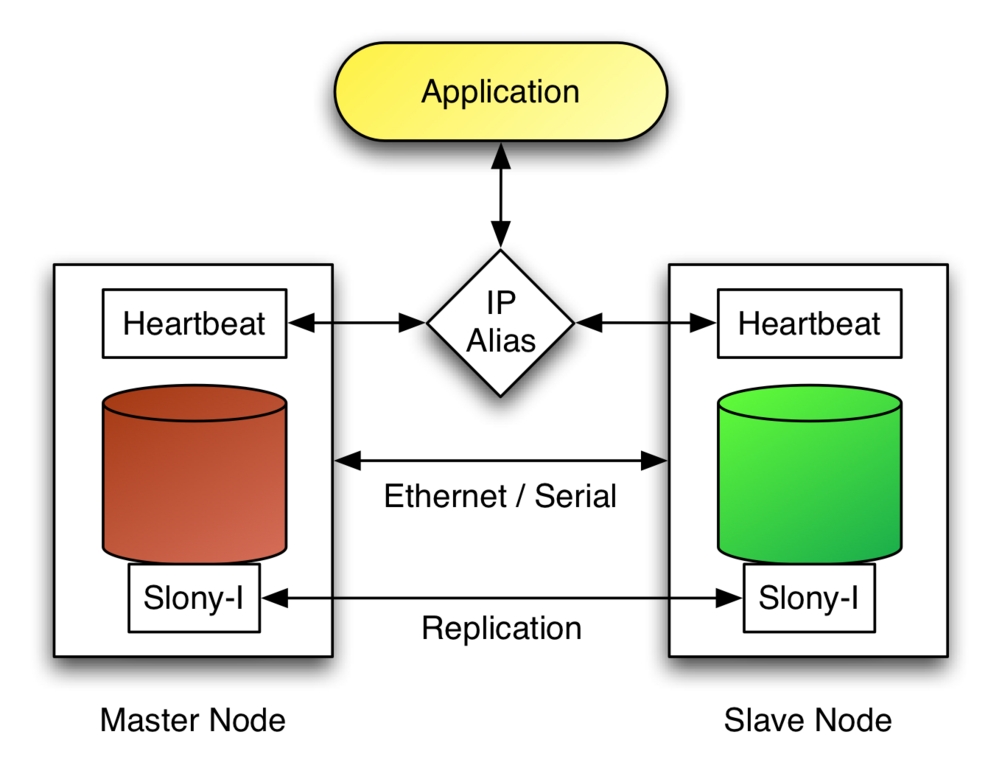
图 2. 在主库发生故障时,Heartbeat 将 IP 别名切换到从库节点。
考虑图 2,它显示了一个主节点和一个从节点通过以太网和串行链路连接在一起。在此配置中,Heartbeat 用于通过这两条链路监控节点的可用性。应用程序通过 IP 别名连接到 PostgreSQL 来使用数据库服务,IP 别名由 Heartbeat 在主节点上激活。如果 Heartbeat 检测到主节点已失败,它会在从节点上启动 IP 别名,并执行 slonik 脚本以将从库提升为新的主库。
该脚本相对简单。清单 4 显示了用于提升从节点(在 slave.example.com 上运行)的脚本内容,以便它开始提供 master.example.com 提供的所有数据库服务。
清单 4. promote.sh
#!/bin/bash CLUSTER=sql_cluster H1=master.example.com H2=slave.example.com U=postgres DB1=contactdb DB2=contactdb su - postgres -c slonik <<_EOF_ cluster name = $CLUSTER; node 1 admin conninfo = 'dbname=$DB1 host=$H1 user=$U'; node 2 admin conninfo = 'dbname=$DB2 host=$H2 user=$U'; failover (id = 1, backup node = 2); drop node (id = 1, event node = 2);
从清单 4 中可以看出,failover Slonik 命令用于指示 id = 1 的节点(在 master.example.com 上运行的节点)已失败,并且 id = 2 的节点将接管来自失败节点的所有集合。第二个命令 drop node 用于从复制系统中完全删除 id = 1 的节点。最终,您可能希望将失败的节点带回集群。为此,您必须将其配置为从库,并让 Slony-I 复制任何丢失的信息。最终,您可以通过锁定集合(lock set)、等待所有事件完成(wait for event)、将集合移动到新的源(move set)并等待确认最后一个命令已完成来继续切换回初始主节点。有关这些命令的更多信息,请参阅《Slonik 命令摘要》。
使用 Slony-I 复制数据库相对简单。与 Linux-HA Heartbeat 结合使用,这使您可以提供数据库服务的高可用性。尽管 Slony-I 和 Linux HA-Heartbeat 的组合是一个有吸引力的解决方案,但重要的是要注意,这不能替代数据库服务器的良好硬件。
即使存在一些小限制,例如无法传播模式更改或复制大型对象,Slony-I 也是 rserv 和 ERServer 的绝佳替代品,并且实际上现在是复制 PostgreSQL 数据库的首选解决方案。Slony-II 甚至支持同步多主复制,并且已经在设计表中。
最后,我要感谢 Slony-I 的作者 Jan Wieck 审阅本文。
本文资源: /article/8202。
Ludovic Marcotte (ludovic@sophos.ca) 拥有蒙特利尔大学计算机科学学士学位。他目前是 Inverse, Inc. 的软件架构师,Inverse, Inc. 是一家位于蒙特利尔市中心的 IT 咨询公司。
