
基于 Squid 的流量控制和管理系统
在任何组织的计算机网络中,互联网访问都是一项主要且最需要的服务。《计算机网络:原理、技术与协议》一书的作者 Olifer 和 Olifer 写道,在过去的 10-15 年中,内部流量和外部流量的 80/20 分配比例已经颠倒,现在外部流量占 80%(参见在线资源)。访问速度、服务数量和可用内容量都在持续增加。互联网用户访问控制任务的现实意义也在增加。这个问题由来已久,但现在它的一些方面正在发生变化。在本文中,我们将以巴什基尔国立师范大学 (BSPU) 的计算机网络为例,探讨其现代解决方案的变体。
首先,我们为互联网访问控制和管理系统提出了一些初始要求
用户帐户支持和管理。
用户流量统计和控制。
三种类型的用户流量限制:每月、每周和每天。
支持移动用户——每次访问互联网时都使用不同计算机的人,例如学生。
每日和每周统计数据以及系统状况的 Web 和电子邮件报告。
基于 Web 的统计数据和系统管理。
显然,这些要求没有以任何方式指定系统实施阶段,因此不会限制我们在这一方面的“幻想”。因此,我们对问题及其解决方案进行了总体考虑。在本文的其余部分,我们将讨论引导我们做出最终决定的想法和推理。
让我们以最流行的万维网 (WWW) 服务为例,重新审视互联网访问过程
用户运行浏览器并输入所需的 URL。
浏览器直接通过网关(进行网络地址转换或其他网络数据包操作)与 WWW 服务器建立连接,或者与代理服务器建立连接,代理服务器会彻底分析客户端请求,并在其缓存中查找所需信息。如果不存在此类信息或信息已过时,代理服务器将以自己的名义与 WWW 服务器连接。
获得的信息将返回给客户端。
浏览器结束连接或进入保持活动状态。
图 1 显示了互联网用户访问组织方案。
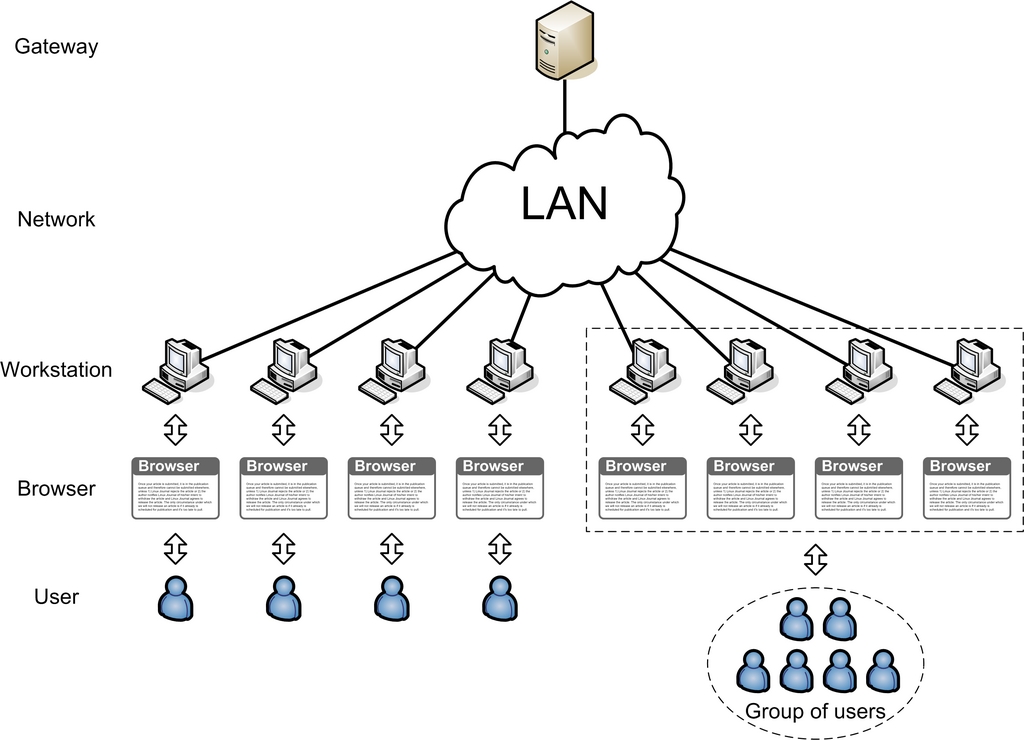
图 1. 互联网用户访问组织
该方案的主要要素包括用户;客户端软件,包括浏览器和操作系统;工作站和其他客户端硬件;网络设备;以及网关(或代理服务器)。网络中可能还存在其他用户身份验证服务器,例如 Microsoft Windows 域控制器、OpenLDAP 或 NIS。
如图 1 所示,用户与工作站之间的关系可以是一对一或多对多的类型。例如,大学教职员工大多配备了自己的计算机。
问题的主要方面是用户流量统计、用户身份验证、用户访问控制和管理以及报告。
这些方面彼此相当独立,每个方面都有多种实现方式。身份验证、流量统计和访问控制的功能可以分配给上述方案中的任何要素。最佳解决方案是将所有功能集中在单个模块或单个访问方案要素中。
访问控制可以在客户端或服务器端实现。客户端访问控制需要使用特殊的客户端软件,该软件也可以验证用户身份。服务器端访问控制实现有两种方式:防火墙和代理服务器。防火墙访问控制存在用户身份验证问题。网络数据包仅包含 IP 地址,这些地址未绑定到用户名。在使用防火墙的情况下,此问题有两种解决方案:使用 VPN,VPN 具有自己的用户身份验证机制和动态用户到 IP 分配控制。这可以通过一些外部工具实现。
然而,更简单的解决方案是使用代理服务器,该服务器支持使用浏览器进行用户身份验证。浏览器身份验证有三种方法
基本身份验证——一种简单且广泛分布的方案,大多数 Internet 浏览器和代理服务器都支持它。其主要缺点是用户密码在网络上传输时未加密。
摘要身份验证是一种更可靠的方案,它使用密码哈希进行安全保护。其主要缺点是缺乏特殊的软件支持。
NTLM 身份验证是 Microsoft 产品网络基础设施特有的。然而,这种身份验证方案是可以接受的,并且在许多计算机网络中,包括 Windows 工作站(据我们所知,Windows 工作站在俄罗斯很普遍),更是可取的。这里的主要优点是代理身份验证方案可以与 Windows 和 Samba 域控制器集成。
任务分析和上述一些想法引导我们开发了两个系统
使用基于防火墙内部功能的 PPTP 的 VPN。从历史上看,VPN 服务器使用 FreeBSD,因此,我们使用 ipfw 防火墙接口和 mpd 移植应用程序作为 PPTP 服务器。流量控制是使用免费、可分发的 NetAMS 系统进行的。
基于 Squid 的互联网用户访问控制和管理系统。
第一个系统由 Vladimir Kozlov 开发,用于连接使用专用计算机进行互联网访问的大学教职员工。其主要缺点是需要客户端 VPN 设置。当计算机网络分布广泛且用户对计算机不够熟悉时,这是一个相当大的障碍。
第二个系统由 Tagir Bakirov 开发,用于连接大多数没有固定计算机进行互联网访问的大学用户。开发的复杂性是该解决方案的主要缺点。接下来,我们将详细讨论第二个解决方案的实施。
在开始之前,我们应该提及,此处的文件路径始终相对于 Squid 源基本目录,在我们的例子中,该目录是 /usr/local/src/squid-2.5STABLE7/。有关获取、编译和使用 Squid 的详细信息,可以从 Squid 站点获得。
现在让我们考虑一下从《Squid 编程指南》中提取的 Squid 的一些特性。
Squid 是一个单进程代理服务器。每个客户端 HTTP 请求都由主进程处理。它的执行过程是一系列回调函数。当 I/O 准备就绪或发生其他事件时,将执行回调函数。当回调函数完成时,它会为后续 I/O 注册下一个回调函数。
Squid 的核心是 select(2) 或 poll(2) 系统调用,它们通过等待一组文件描述符上的 I/O 事件来工作。Squid 使用它们来处理所有打开的文件描述符上的 I/O。comm_select() 是发出 select() 系统调用的函数。它扫描整个 fd_table[] 数组以查找处理程序函数。对于每个就绪的描述符,都会调用处理程序。处理程序函数使用 commSetSelect() 函数注册。关闭处理程序通常从 comm_close() 调用。关闭处理程序的工作是释放与文件描述符关联的数据结构。因此,comm_close() 通常必须是序列中的最后一个函数。
Squid 的一个有趣的特性是每个 IP 地址的客户端数据库支持。相应的代码位于文件 src/client_db.c 中。主要思想是哈希索引表 client_table,它由指向 ClientInfo 结构的指针组成。这些结构包含有关 HTTP 客户端和 ICCP 代理服务器连接的不同信息,例如,请求、流量和时间计数器。以下是文件 src/structs.h 中的相应代码
struct _ClientInfo {
/* must be first */
hash_link hash;
struct in_addr addr;
struct {
int result_hist[LOG_TYPE_MAX];
int n_requests;
kb_t kbytes_in;
kb_t kbytes_out;
kb_t hit_kbytes_out;
} Http, Icp;
struct {
time_t time;
int n_req;
int n_denied;
} cutoff;
/* number of current established connections */
int n_established;
time_t last_seen;
};
以下是一些用于管理客户端表的重要全局和局部函数
clientdbInit()——初始化客户端表的全局函数。
clientdbUpdate()——更新表中的记录或在需要时添加新记录的全局函数。
clientdbFreeMemory()——删除表并释放已分配内存的全局函数。
clientdbAdd()——由函数 clientdbUpdate() 调用的局部函数,用于将记录添加到表中并计划垃圾记录收集过程。
clientdbFreeItem()——由函数 clientdbFreeMemory() 调用的局部函数,用于从表中删除单个记录。
clientdbSheduledGC()、clientdbGC() 和 clientdbStartGC()——实现垃圾记录收集过程的局部函数。
通过并行化对已开发系统的要求和现有客户端数据库的可能性,我们可以说,除了每个用户名的客户端索引之外,一些关键的基本功能已经实现。现有客户端统计数据库的另一个重大缺点是,信息是在客户端已经收到整个请求内容之后才刷新的。
在我们的开发中,我们使用来自 src/client_db.c 文件的代码和一些修改,实现了另一个并行且独立的每个用户的客户端数据库。用户统计信息保存在结构 ClientInfo_sb 中。以下是来自文件 src/structs.h 的相应代码
#ifdef SB_INCLUDE
#define SB_CLIENT_NAME_MAX_LENGTH 16
struct _ClientInfo_sb {
/* must be the first */
hash_link hash;
char *name;
unsigned int GID;
struct {
long value;
char type;
long cur;
time_t lu;
} lmt;
/* HTTP Request Counter */
int Counter;
};
#endif
客户端数据库由以下全局和局部函数管理,这些函数与先前列出的函数非常相似
clientdbInit_sb()——初始化客户端表的全局函数。
clientdbUpdate_sb()——更新表中的记录的全局函数,当超出限制时断开客户端连接,或者在需要时通过调用函数 clientdbAdd_sb() 添加新记录。
clientdbEstablished_sb()——全局函数,用于计算客户端请求的数量,并定期将相应的记录刷新到文件中,当超出限制时断开客户端连接,并在需要时通过调用函数 clientdbAdd_sb() 添加新记录。
clientdbFreeMemory_sb()——删除表并释放已分配内存的全局函数。
clientdbAdd_sb()——由函数 clientdbUpdate_sb() 调用的局部函数,用于将记录添加到表中并计划垃圾记录收集过程。
clientdbFlushItem_sb()——由函数 clientdbEstablished_sb() 和 clientdbFreeItem_sb() 调用的局部函数,用于将特定记录刷新到文件中。
clientdbFreeItem_sb()——由函数 clientdbFreeMemory_sb() 调用的局部函数,用于从表中删除单个记录。
clientdbSheduledGC_sb()、clientdbGC_sb() 和 clientdbStartGC_sb()——实现垃圾记录收集过程的局部函数。
客户端数据库初始化和释放的实现方式与文件 src/main.c 中的原始表类似。我们代码的主要特点是在文件 src/client_side.c 中的客户端例程中调用函数 clientdbUpdate_sb() 和 clientdbEstablished_sb()
从辅助函数 clientWriteComplete() 调用函数 clientdbUpdate_sb(),该函数负责将数据部分发送到客户端。
从函数 clientReadRequest() 调用函数 clientdbEstablished_sb(),该函数处理客户端请求。
列表 1 显示了文件 src/client_side.c 中函数 clientWriteComplete() 和 clientReadRequest() 的相应片段。
列表 1. 来自 src/client_side.c 文件的函数 clientWriteComplete() 和 clientReadRequest() 的片段
static void
clientWriteComplete(int fd,
char *bufnotused,
size_t size,
int errflag,
void *data)
{
clientHttpRequest *http = data;
...
if (size > 0)
{
kb_incr(&statCounter.client_http.kbytes_out,
size);
/*-Here comes the SB section----------------------*/
#ifdef SB_INCLUDE
if (http->request->auth_user_request)
{
if ( authenticateUserRequestUsername(
http->request->auth_user_request) )
if (!clientdbUpdate_sb(
authenticateUserRequestUsername(
http->request->auth_user_request),
size) )
{
comm_close(fd);
return;
}
}
#endif
/*------------------------------------------------*/
if (isTcpHit(http->log_type))
kb_incr(
&statCounter.client_http.hit_kbytes_out,
size);
}
...
}
...
static void
clientReadRequest(int fd, void *data)
{
ConnStateData *conn = data;
int parser_return_code = 0;
request_t *request = NULL;
int size;
void *p;
method_t method;
clientHttpRequest *http = NULL;
clientHttpRequest **H = NULL;
char *prefix = NULL;
ErrorState *err = NULL;
fde *F = &fd_table[fd];
int len = conn->in.size - conn->in.offset - 1;
...
/* Process request body if any */
if (conn->in.offset > 0 &&
conn->body.callback != NULL)
{
clientProcessBody(conn);
}
/* Process next request */
while (conn->in.offset > 0 &&
conn->body.size_left == 0)
{
int nrequests;
size_t req_line_sz;
...
/* Process request */
http = parseHttpRequest(conn,
&method,
&parser_return_code,
&prefix,
&req_line_sz);
if (!http)
safe_free(prefix);
if (http) {
...
if (request->method == METHOD_CONNECT)
{
/* Stop reading requests... */
commSetSelect(fd,
COMM_SELECT_READ,
NULL,
NULL,
0);
clientAccessCheck(http);
/*-Here comes the SB section----------------------*/
#ifdef SB_INCLUDE
if(http->request->auth_user_request)
{
if (
authenticateUserRequestUsername(
http->request->auth_user_request
)!=NULL)
{
if(!clientdbCount_sb(
authenticateUserRequestUsername(
http->request->auth_user_request)))
{
comm_close(fd);
return;
}
}
}
#endif
/*------------------------------------------------*/
break;
} else {
clientAccessCheck(http);
/*-Here comes the SB section----------------------*/
#ifdef SB_INCLUDE
if(http->request->auth_user_request)
{
if (
authenticateUserRequestUsername(
http->request->auth_user_request
)!=NULL)
{
if(!clientdbCount_sb(
authenticateUserRequestUsername(
http->request->auth_user_request)))
{
comm_close(fd);
return;
}
}
}
#endif
/*------------------------------------------------*/
/* while offset > 0 && body.size_left == 0 */
continue;
}
} else if (parser_return_code == 0) {
...
/* while offset > 0 && conn->body.size_left == 0 */
}
...
}
因此,该机制非常简单。图 2 显示了从我们系统的角度来看的简单客户端请求处理图。每个客户端请求都包含用户身份验证信息,包括用户名。函数 clientdbUpdate_sb() 搜索与从请求中获取的用户名对应的 ClientInfo_sb 记录。在没有此类记录的情况下,它使用来自授权文件的信息添加新的 ClientInfo_sb 记录。如果用户超出其限制,他们将立即使用函数 comm_close() 断开连接。函数 clientdbEstablished_sb() 的调用也用于控制客户端请求的数量,并将当前用户信息每 SB_MAX_COUNT 个请求保存到授权文件中。授权文件称为 passwd 和 group,类似于 UNIX 文件。passwd 文件包含用户信息,group 文件包含用户组信息。以下是描述性示例
`passwd': #<name>:<full name>:<group id>: #<current limit value>:<last limit update time> tagir:Tagir Bakirov:1:6567561:12346237467 `group': #<name>:<full name>:<group id>: #<group limit value>:<group limit type> users:BSPU users:1:10000000:D
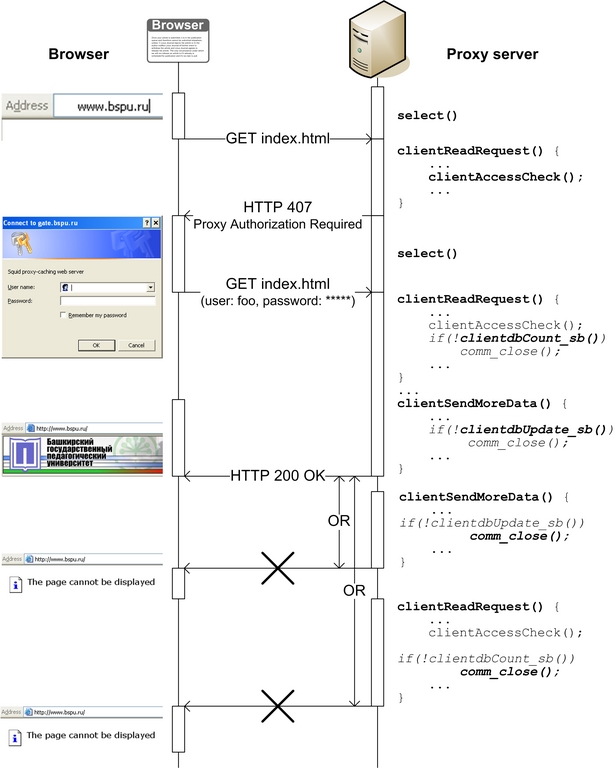
图 2. 简单客户端请求处理图
限制有三种类型:D(每日)、W(每周)和 M(每月)。passwd 和 group 文件名和路径可以在 Squid 配置文件 squid.conf 中设置。这是通过修改 squid.conf 模板文件结构和 Squid 配置结构来实现的。
以下是 Squid 源代码中的其他细微更改
文件 src/protos.h 中的全局函数定义。
文件 src/typedefs.h 中的 ClientInfo_sb 结构类型定义。
文件 src/enums.h 中结构列表中的 ClientInfo_sb 结构标识符声明。
文件 src/mem.c 中内存分配过程 memInit() 中的 ClientInfo_sb 结构初始化。
所有这些更改都是类似于代码进行的,维护了原始的每个 IP 客户端数据库。我们希望一切都做得正确。
浏览我们的修改,您可能会注意到所有代码都放在条件编译块 (#ifdef SB_INCLUDE ... #endif) 中。当参数 --enable-sbclientdb 包含在 Squid configure 脚本的命令行中时,将声明变量 SB_INCLUDE。这是通过在进行一些细微修改后使用 autoconf 重新编译 configure.in 脚本来实现的。
在本文中,我们考虑了互联网访问控制问题的最新技术。我们提出了几种解决方案,并考虑了基于 Squid 代理服务器的变体,该变体已在 BSPU 的 LAN 中实施。我们的解决方案不是万能药,可能存在一些缺点,但它相当简单、灵活且完全免费。
我们还应该说,我们的 Web 程序员 Elmir Mirdiev 现在正在完成一个小型基于 PHP 的网站的实施,该网站旨在用于系统管理和用户统计报告。用户详细统计信息是使用 Sarg 系统从 Squid 日志生成的。
其他信息可以从系统源代码中获得。您可以从我们的站点获取 Squid 版本 2.5STABLE7 tarball 的整个修改后的源代码,或者仅获取补丁文件。我们很乐意通过电子邮件回答您的问题。
本文的资源: /article/8205。
Tagir K. Bakirov (batk@mail.ru) 是 BSPU 的系统管理员,也是乌法国立航空技术大学的一年级研究生。他的主要兴趣是信息安全、多智能体系统和其他 IT。他的爱好包括体育活动、书籍、音乐和外语。
Vladimir G. Kozlov (admin@bspu.ru),教育学博士,副教授,是 BSPU 的高级系统管理员和多门 IT 学科的讲师。他的主要兴趣是 *NIX 网络、IT 和电子学。他的爱好包括业余无线电 (UA9WBZ)、家庭和体育。
