
使用 NCS 和 Brainlab 建模大脑
自 20 世纪 50 年代以来,计算机科学家一直在研究人工神经网络 (ANN)。尽管 ANN 的灵感来源于真实生物网络,例如您大脑中的网络,但典型的 ANN 并未对许多可能被证明很重要的生物学方面进行建模。例如,真实的神经元通过发送称为动作电位 (AP) 的小电压尖峰进行通信。然而,ANN 并不对这些单个 AP 的时间进行建模。相反,ANN 通常假设 AP 是重复的,并且它们仅对重复率进行建模。在一段时间内,大多数研究人员认为,对尖峰率进行建模足以捕捉网络的有趣行为。但是,如果生物神经网络的一些计算能力来源于单个 AP 的精确时间呢?常规 ANN 永远无法对此可能性进行建模。
1999 年,ANN 忽略了单个 AP 现实的想法使内华达大学里诺分校的 Phil Goodman 将他的重点从 ANN 转向更真实的尖峰神经网络模型。他首先寻找一个程序,该程序允许他对大型尖峰神经元网络进行实验。当时,存在几个优秀的开源研究软件包,它们能够真实地模拟少量尖峰神经元;GENESIS 和 NEURON 是最受欢迎的两个。但是这些程序并非旨在与他设想的数千个尖峰神经元网络一起工作。Goodman 认为,借助低成本的 Linux 集群技术,应该可以构建一个并行程序,该程序足够真实,可以对神经元的尖峰和细胞膜通道行为进行建模,同时效率也足够高,可以构建这些神经元的大型网络进行研究。Goodman 启动了新皮层模拟器 (NCS) 项目来创建这样一个程序。从 Goodman 在专有的 MATLAB 环境中编写的原型程序开始,一位与计算机科学教授 Sushil Louis 合作的学生使用 MPI 并行库包在 C 语言中编写了 NCS 的第一个并行版本。
当我在 2002 年加入研究小组时,NCS 已经在由另一位学生 James Frye 进行重大重写,他与 CS 教授 Frederick C. Harris, Jr. 合作。这一次,目标是将系统从原型转变为精简可靠的生产软件系统。我帮助了这项工作,实施了许多优化,大大提高了性能。
我还为 NCS 源代码设置了第一个版本控制,使用了当时新的开源 Subversion 系统。当时,Subversion 仍然是一个 alpha 项目。尽管如此,我还是被该系统的几个功能所吸引,包括将整套文件自动捆绑到一个单独的发布版本中。在使用了 Subversion 一段时间后,旧的主力 CVS 相比之下显得笨拙。Subversion 当时发展迅速。不过,不止一次在系统软件升级后,我不得不花费数小时尝试使用组件库的某种组合版本重建 Subversion 可执行文件,以便恢复对我们版本历史的访问。Subversion 用户邮件列表在这些恢复工作中总是很有帮助。渴望利用新功能,我欣然为选择 alpha 软件付出了代价。幸运的是,这种权衡不再必要。Subversion 现在稳定且灵活,我毫不犹豫地会为任何新项目选择它。
随着 NCS 软件的成熟,我们的集群不断扩展,这要归功于美国海军研究办公室的几项资助。最初由 30 台双处理器 Pentium III 机器组成的 Beowulf 集群随着 34 台双处理器 Pentium 4 的加入而增长。最近,它再次随着 40 台双处理器 Opteron 的加入而增长。从一开始,Linux 就一直是集群的操作系统,运行 Rocks 集群 Linux 发行版。计算节点配备了完整的 4GB 系统内存,以容纳大脑模型中的大量突触结构。内存容量是迁移到 64 位 Opteron 的主要动机。管理网络流量在 100MB 和后来的 1GB 以太网连接上移动,而专门的低延迟 Myrinet 网络有效地传递了典型的神经网络模拟中发生的数百万个 AP 尖峰消息。
随着 NCS 现在能够模拟数千个尖峰神经元和数百万个突触的网络,学生们开始将其用于实际研究。然而,正如我在开始自己的第一次大规模模拟实验时发现的那样,NCS 在实践中可能很难有效使用。使用 NCS 的大部分困难源于 NCS 将纯文本文件作为输入的事实。此输入文件定义了神经网络的特征,包括神经元和树突隔室、突触、离子通道等等。对于大型神经网络模型,此文本文件通常会增长到数千甚至数十万行。
尽管这种纯文本文件方法允许模型定义具有很大的灵活性,但任何使用 NCS 进行严肃工作的人很快就会意识到,通过直接在文本编辑器中编辑输入文件来创建网络模型是不切实际的。如果模型包含超过少数的神经结构,手动编辑是乏味且容易出错的。因此,每个学生最终都会实现某种专用宏处理器,以帮助通过基于循环或其他控制结构重复发出带有变量替换的文本块来构建输入文件。其中几个预处理器是用专有的 MATLAB 语言构建的,因为 MATLAB 也可用于模拟后数据分析,并且是我们实验室中流行的工具。这些宏处理器中的每一个都是匆忙实现的,并且只考虑了一个特定的网络模型。因此,没有一个解决方案足够通用,可以供下一个学生使用,从而导致大量的重复工作。
为了我自己的工作,也为了防止未来的学生在开始使用 NCS 进行大型实验时面临这些熟悉的障碍,我寻找了更通用的解决方案。似乎没有模板化的预处理方法能够胜任这项任务。经过一些实验,我得出的结论是,指定大脑模型的最佳方法是直接作为程序——不是作为将由程序解析的模板化文本文件,而是实际上作为程序本身。
为了理解这个问题,请考虑我们的大脑模型通常包含数百或数千个称为皮质柱的结构,每个结构由一百个或更多神经元组成。这些柱具有复杂的、通常是可变的内部结构,并且这些柱本身通过突触以复杂的方式互连。我们可能希望从一次运行到另一次运行调整某些或所有这些连接的模式。例如,我们可能希望将一个柱连接到位于一定距离范围内的所有相邻柱,其概率是距离的函数。即使是这种相对简单的连接模式也无法在 NCS 输入文件中方便地表达出来,该文件仅允许对象和连接的纯列表。
但是,通过将大脑模型本身存储为构建连接的小脚本,我们可以得到一个只有几行代码而不是数千行文本的模型。这段代码很容易在以后进行修改,以适应实验的变化。脚本语言的所有强大的循环和控制结构、数学功能,甚至面向对象的功能都可以直接供大脑建模者使用。在幕后,脚本可以自动将模型的脚本表示形式转换为 NCS 文本输入文件以进行实际模拟。大脑建模者将永远不会再受限制性的解析模板结构的束缚。我给我计划开发的通用脚本建模环境命名为 Brainlab,并着手为该项目选择合适的脚本语言。
考虑到 MATLAB 在我们实验室中的突出地位,我对脚本语言的第一个想法是 MATLAB。但是,关键时期重复出现的许可服务器故障使我对 MATLAB 感到厌烦。我考虑了 Octave,这是一个优秀的开源 MATLAB 仿制品,它采用了相同的强大向量处理方法。我总体上喜欢我所看到的,甚至在紧要关头将一些 MATLAB 应用程序移植到 Octave 中工作。我很高兴地发现转换相对轻松,只是由于 MATLAB 宽松的语言规范而变得复杂。但我发现 Octave 的语法很笨拙,这并不奇怪,因为它在很大程度上是从 MATLAB 继承来的。我以前的 Tcl/Tk 经验是积极的,但似乎没有太多的科学界人士使用它。这些年来,我做了一些 Perl 项目,但我发现它难以阅读且容易忘记。
然后我开始在一些小型项目中使用 Python。Python 简洁的语法、强大且设计良好的面向对象功能以及拥有广泛库和科学工具包的大型用户社区使其使用起来非常愉快。阅读 Python 代码是如此容易和自然,以至于我可以离开一个项目几个月,然后重新开始,几乎没有任何延迟地弄清楚我离开时的位置。因此,我使用 Python 创建了 Brainlab 的第一个版本。
在 Brainlab 中,大脑模型从 BRAIN 类的 Python 对象开始
from brainlab import * brain=BRAIN()
这个大脑对象最初包含一个默认的细胞类型库、突触类型、离子通道类型和用于构建大脑模型的其他类型的对象。例如,内置的离子通道类型存储在 BRAIN 类中名为 chantypes 的字段中。此字段实际上是一个 Python 字典,按通道名称索引。可以通过简单地打印出相应的 Python 字典来查看它
print brain.chantypes
可以创建、修改和查看基于名为 ahp-2 的标准类型的新通道类型 ahp-3,如下所示
nc=brain.Copy(brain.chantypes, 'ahp-2', 'ahp-3') nc.parms['STRENGTH']="0.4 0.04" print brain.chantypes['ahp-3']
为了构建真正的网络,大脑必须包含这些结构的一些实例,而不仅仅是类型配置文件。在 NCS 中,每个细胞都属于一个称为皮质柱的结构。我们可以创建一个简单柱的实例并将其添加到我们的大脑对象中,如下所示
c1=brain.Standard1CellColumn() brain.AddColumn(c1)
此柱对象带有一组默认的离子通道实例和其他结构,如果需要,我们可以轻松调整它们。最常见的情况是,我们有一组我们想要创建和互连的柱。以下示例在循环中创建一个二维柱网格,然后随机连接这些柱
cols={}
size=10
# create the columns and store them in cols{}
for i in range(size):
for j in range(size):
c=brain.Standard1CellColumn()
brain.AddColumn(c)
cols[i,j]=c
# now connect each column to another random column
# (using a default synapse)
for i in range(size):
for j in range(size):
ti=randint(0, size-1)
tj=randint(0, size-1)
fc=cols[i,j]; tc=cols[ti,tj]
brain.AddConnect(fc, tc)
如果我们的大脑没有受到一些刺激,它就不会有太大的作用。因此,我们可以在 Python 列表中定义一组随机间隔的刺激尖峰,并将其应用于我们的柱网格的第一行,如下所示
t=0.0
stim=[]
for s in range(20):
t+=random()*10.0
stims.append(t)
for i in range(size):
brain.AddStim(stim, cols[i,0])
到目前为止,我们的大脑模型仅作为 Python 对象存在。为了在 NCS 模拟中运行它,我们必须将其转换为 NCS 要求的文本输入文件。Brainlab 负责此转换;只需打印大脑对象即可为该模型创建相应的 NCS 输入文本。命令print brain打印超过 3,000 行的 NCS 输入文件文本,即使对于此处显示的相对简单的示例也是如此。更复杂的模型会导致 NCS 的输入文件更长,但模型的程序版本仍然非常紧凑。
通过仅更改脚本中的几个参数,我们可以创建一个完全不同的文本 NCS 输入文件。实验人员可以将此文本保存到文件中,然后从命令行在文件上调用 NCS 模拟器。更好的是,他或她可以直接在 Brainlab 环境中模拟模型,甚至不必查看中间文本,如下所示brain.Run(nprocs=16).
Run() 方法使用指示的处理器节点数在 Beowulf 集群上调用大脑模型。最常见的情况是,实验不仅仅是单个大脑模型的单个模拟。真实实验几乎总是由数十或数百个相关大脑模型的模拟运行组成,每次运行的参数或刺激略有不同。这就是 Brainlab 真正闪光的地方:在一个集成的环境中创建模型、模拟模型、调整模型,然后一次又一次地模拟模型。如果我们想运行十次实验,每次运行都改变突触传导强度,并且每次运行都有不同的作业编号,以便我们稍后可以检查所有报告,我们可以这样做
for r in range(10): # r is run number
s=brain.syntypes['C.strong']
s.parms['MAX_CONDUCT']=.01+.005*r
brain.parms['JOB']='testbrain%d'%r
brain.Run(nprocs=16)
Python 的 numarray 扩展包提供了对模拟产生的大型 NCS 数据集进行高效操作和统计分析的功能。对于结果的图形和图表,优秀的 matplotlib 包通过简单但功能强大的类似 MATLAB 的界面生成出版质量的输出(图 1)。Brainlab 还为这些包提供了许多方便的接口,使执行神经科学研究常用的操作更加容易。Brainlab 还提供使用 Python OpenGL 绑定交互式检查网络模型的 3D 视图(图 2)。
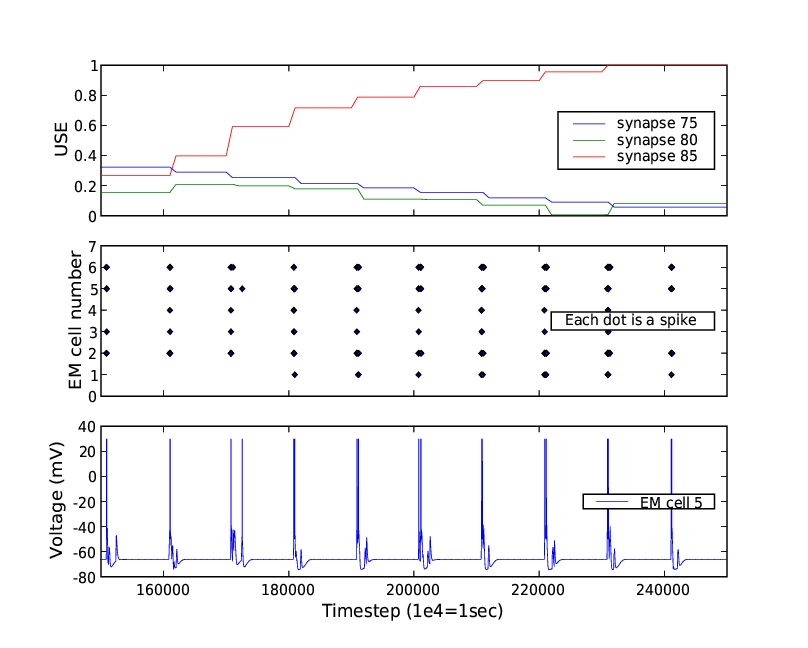
图 1. 使用 matplotlib 包可以轻松创建可用于出版的图表。
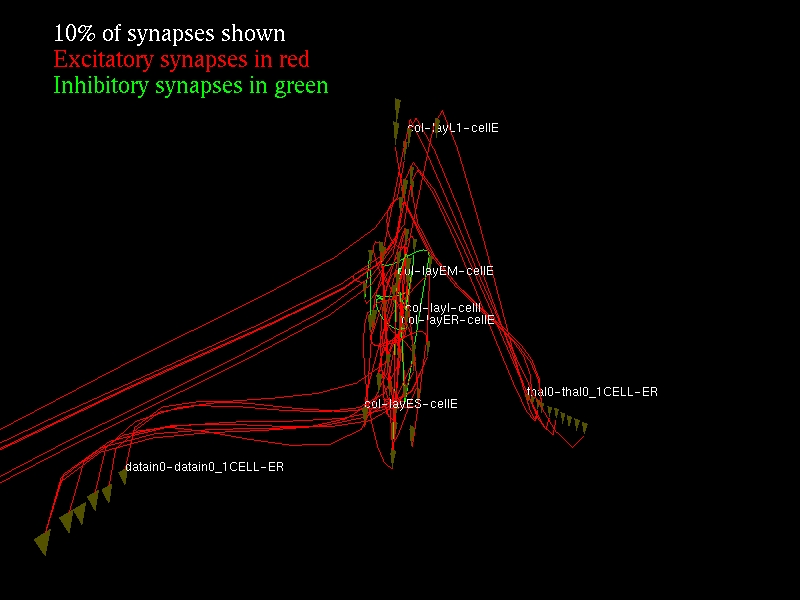
图 2. 为了与 3D 视图进行交互式实验,Brainlab 提供了 OpenGL 接口。
通常,需要对许多网络参数进行一些实验,以便找到平衡的大脑模型。例如,如果突触强度太高或太低,模型可能无法真实地工作。我们已经看到 Brainlab 如何帮助建模者通过使用变化的参数重复运行相同的模型来搜索好的模型。但是,比简单搜索更强大的技术是使用来自生物学、进化的另一个灵感,对整套参数的值进行遗传搜索。我已经使用 Brainlab 通过我自己设计的遗传算法 (GA) 模块以及 Scientific Python 包 SciPy 的标准 GA 模块进行了这种多参数搜索。
Brainlab 使我的复杂实验变得切实可行,甚至可能成为可能。在这一点上,我无法想象以任何其他方式进行它们。事实上,如果 NCS 要从头开始重新实现,我会建议一个重要的设计更改:消除中间 NCS 输入文本文件格式。此文件格式的复杂度足以需要解析器以及相关的实现复杂性、文档负担和大脑模型加载速度减慢。与此同时,它远不够表达力,无法直接用于除最简单的大脑模型之外的任何模型。相反,可以将 Python/Brainlab 等脚本环境直接集成到 NCS 中,脚本可以在内存中创建结构,这些结构可以直接从 NCS 模拟引擎访问。由此产生的系统将非常强大和高效,并且总体文档负担将减少。这种通用方法应适用于模型构建研究其他领域的许多不同问题。
今年夏天,NCS 将安装在我们位于瑞士 EPFL 的姐妹实验室——脑智研究所神经微电路实验室的新型 4,000 处理器 IBM BlueGene 集群上,并与实验室主任 Henry Markram 合作。早期测试表明,由于高效的编程和大脑中突触连接的高度并行性,我们可以随着集群规模的增加实现 NCS 性能的近线性加速。我们希望世界各地的其他研究人员会发现 NCS 和 Brainlab 在建模和理解人脑的工作中很有用。
本文的资源: /article/8203。
Rich Drewes (drewes@interstice.com) 是内华达大学里诺分校生物医学工程专业的博士候选人。
