
廉价的 3-D 空间音频
许多为高级游戏设置的计算机系统都包含杜比环绕声。典型的扬声器配置为 4.1(四个扬声器和一个低音炮)、5.1 和 7.1。此系统设计用于所有扬声器都位于以听众为中心的平面上,因此不可能让声音真正从听众上方或下方发出,尽管某些系统尝试模拟这种效果。想象一个游戏场景,其中一个怪物在玩家上方和后方的墙壁上爬下来,同时一只老鼠在听众身后的地板上乱窜。在平面环绕系统中,怪物和老鼠的声音效果都将来自后置扬声器,使得很难区分声音源的实际位置。
借助真正的 3-D 空间音频,怪物的声音效果可以从位于后左上方的扬声器播放,而老鼠的声音可以从位于后左下方和后右下方的扬声器播放。在这种设置中,玩家可以更好地感受到是什么产生了声音以及声音来自何处。现在玩家可以装备火箭发射器,直接转向后左上方,炸掉怪物——无需瞄准无害的老鼠。
空间声音已经存在多年,主要用于沉浸式虚拟环境。这些系统尚未大规模生产,通常必须由专业人员安装,这使得它们成本高昂,超出大多数家庭用户的承受能力。我们设计了一种低成本的真正 3-D 空间音频解决方案,该解决方案仅需廉价的消费级硬件和开源软件。此解决方案允许任意放置扬声器,而不必像其他系统那样共面。我们的 3-D 空间音频解决方案是我们所知的第一个以如此低的成本提供真正 3-D 声音的解决方案。
3-D 空间音频的初步技术 Fantasound 最初由迪士尼在 1930 年代后期为电影行业开发。多年来,人们进行了大量工作来推进该领域,特别是杜比实验室。在过去的几十年中,研究人员使个人计算机能够发出空间音频。如今,空间音频在现代电脑游戏中很常见。家用系统通常使用耳机或平面扬声器阵列,通常采用预设配置,例如杜比环绕声 5.1。
耳机为提供廉价的 3-D 音频提供了一个独特的机会。使用头部相关传输函数 (HRTF) 的算法可以使用简单的立体声声卡在耳机上创建令人信服的 3-D 空间音频。 HRTF 使用有关声音如何被用户的身体(尤其是耳朵的形状)转换的数据,以映射具有 3-D 位置源的声音。该技术在很大程度上依赖于为每个耳朵应用不同的时间延迟。最终,我们决定不使用耳机,因为我们需要一个易于扩展到许多用户的系统。使用扬声器远比耳机更实用且更具成本效益。
许多高成本的专业级硬件包可供选择,例如 RME Hammerfall 系列、M-Audio Delta 系列和 Lake Audio,它们提供真正的 3-D 空间音频。每个软件包的成本都超过 1000 美元,以高音质和面向专业市场的大量功能而自豪。虽然这些软件包的声学质量无疑高于我们的低成本 3-D 音频解决方案,但在音频清晰度和保真度方面,两种选择都提供真正的 3-D 空间音频。
当我们开始组装空间音频系统时,没有廉价的硬件和软件组合可以产生真正的 3-D 空间音频。虽然有一些软件 API 允许任意(不一定是共面的)放置声源,例如 Microsoft DirectSound 和高级 Linux 声音架构 (ALSA),但低级驱动程序官方仅支持前面提到的共面 4.1、5.1 和 7.1 扬声器位置。无法告知驱动程序扬声器已移动到备用配置,例如,扬声器位于听众上方或下方。因此,即使软件开发人员可以将声音定位在用户的头部上方或下方,低级驱动程序仍然假定声音是从用户头部周围的圆圈中发出的。真正 3-D 空间音频支持的大部分来自定制 API。
赫尔辛基理工大学 (HUT) 的 Tommi Ilmonen 开发了一个名为 Mustajuuri 的 3-D 空间音频 API,该 API 构建在 ALSA 驱动程序之上。 Mustajuuri API 实现了 Ville Pulkki 引入的矢量基振幅平移 (VBAP)(请参阅在线资源),作为底层的 3-D 空间音频模型。简而言之,VBAP 是一种算法,负责在 3-D 扬声器阵列中移动声音,并使声音看起来来自特定方向。 VBAP 选择最靠近虚拟声音位置的三个扬声器,并计算每个扬声器所需的音量。有关 VBAP 平移如何工作的示例,请参见图 1。 Mustajuuri 还通过使用时间延迟和距离衰减来模拟音频的深度。这使得可以将声音定位在相对于听众空间的任何位置。 Mustajuuri 已经用于使用高端声卡生成 3-D 空间音频,但到目前为止,它尚不支持低端声卡。
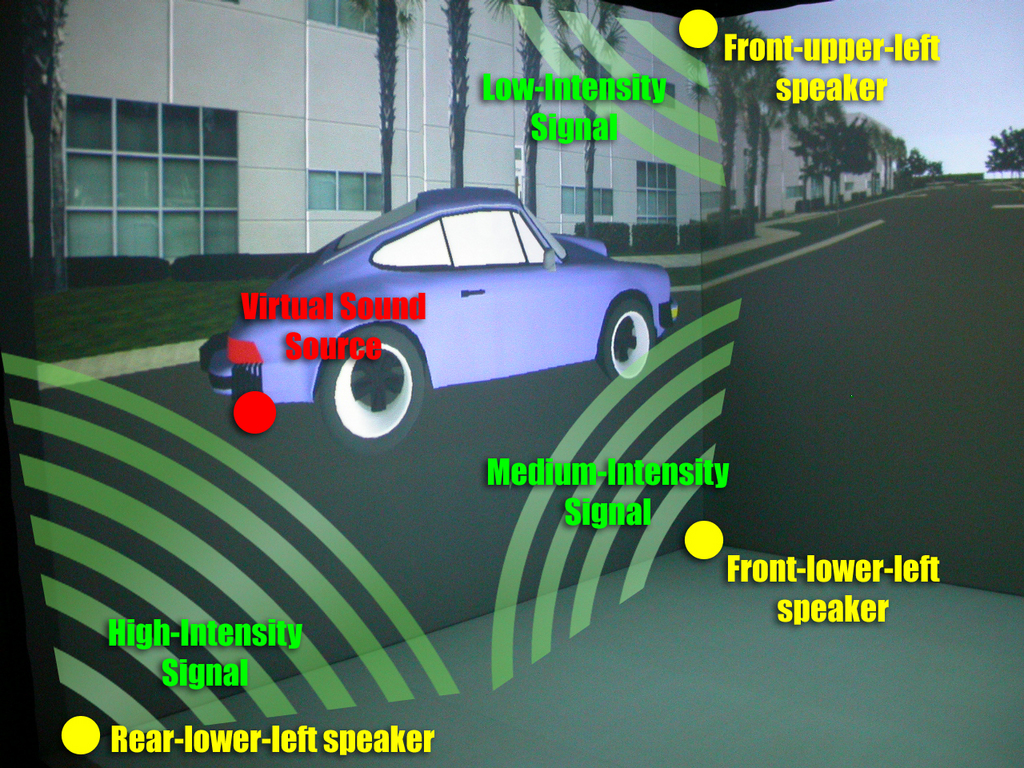
图 1. 沉浸式房间中 3-D 空间音频测试用例的视图。视觉描绘显示了当前视图的声音来自哪些扬声器。对于每个声音,使用最靠近虚拟声源的三个扬声器来播放声音。它们的音量根据与扬声器的距离和许多其他因素而变化。
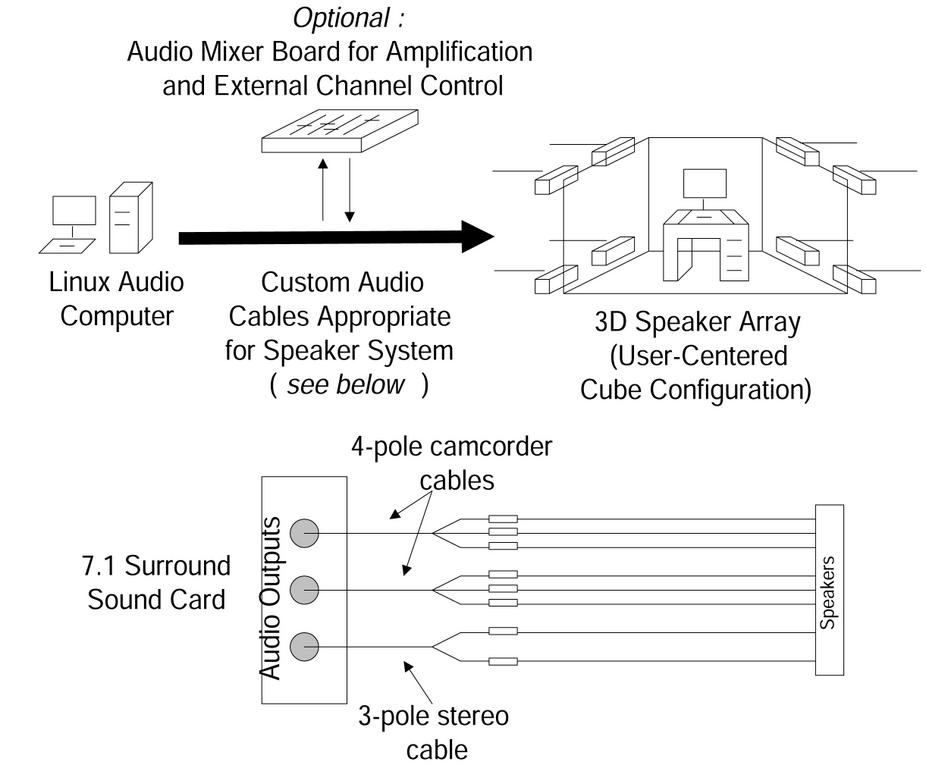
图 2. 音频硬件设置
设置低成本 3-D 空间音频系统所需的硬件包括具有某些功能的商用声卡、扬声器和音频线缆。在这里,我们描述了我们对硬件组件的选择以及设置硬件所需的步骤。在整个讨论过程中,请参考图 2,了解硬件互连、扬声器放置和布线的图示。
首先要考虑的是特定应用需要多少扬声器才能产生 3-D 空间音频。最小的包围式设置可产生来自用户周围所有方向(左右、前后和上下)的声音。扬声器可以以任何配置放置,但对于不规则配置,设置 3-D 音频平移功能并不那么简单。我们决定在立方体配置中使用八个扬声器,每个扬声器位于立方体的一个顶点,如图 2 所示。此任务所需的扬声器没有什么特别之处——选择取决于预算和品味。我们使用了八个有源商用级扬声器,原因很简单,因为我们的实验室中已经有了它们。
八个扬声器需要一张可以产生八个音频通道的声卡。在低成本商用声卡中,唯一适用的候选者是 7.1 声卡。我们选择了创新科技 Audigy 2 声卡,在撰写本文时发现它的价格低至 90 美元。虽然可以使用更昂贵的声卡生成八个独立的音频通道,但 Audigy 2 声卡是我们知道的唯一具有驱动程序来支持我们正在做的事情的商用声卡。
重要的是要了解声卡的输出。在典型的杜比环绕声 7.1 扬声器布置中,有两个前置扬声器(左声道和右声道);两个侧扬声器;两个后置扬声器;一个中置扬声器,位于视频屏幕的前方和上方;以及一个低音炮通道,即 .1 扬声器。 Audigy 2 ZS 有三个模拟输出插孔,一个 1/8 英寸迷你电话插孔,标记为 1、2 和 3,为八个扬声器提供线路电平输出。插孔 1 为三极,表示它携带三个信号——两个信号驱动前置左声道和右声道扬声器,第三个为接地。插孔 2 和 3 为四极,每个插孔携带四个信号。插孔 2 驱动后置扬声器对和一个侧扬声器,而插孔 3 驱动低音炮、中置扬声器和剩余的侧扬声器。最后一个需要考虑的因素是这些信号是未放大的线路电平,因此扬声器需要是接受线路电平输入的有源类型。或者,应在声卡和扬声器之间使用单独的放大器或一组放大器。
下一步是安装扬声器。许多为环绕声设计的扬声器都包含支架,但市面上也有许多其他扬声器类型的扬声器支架。在我们的应用中,我们已经有了立方体基础设施,并使用定制支架将扬声器连接到立方体。扬声器配置越简单,软件配置就越简单——该过程将在本文后面解释。
最后,必须将扬声器连接到声卡。将扬声器连接到 Audigy 2 的方式取决于扬声器的类型和使用的放大方式。去您最喜欢的电子商店应该可以买到任何必要的连接器。在我们的例子中,每个扬声器都有一个两极 1/4 英寸电话插孔,因此我们需要将声卡的三个组合输出分成八个单独的信号。对于插孔 1,我们使用了现成的 1/8 英寸立体声转双 RCA 适配器。对于插孔 2 和 3,我们找到了类似的带有四极和三个 RCA 连接器的适配器。这些适配器最常用于摄像机,其中三个信号用于复合视频和立体声音频。这些适配器为我们提供了八个单独的 RCA 连接器,在获得八根长 RCA 转 1/4 英寸单声道线缆后,我们就完成了设置。
在我们的最终配置中,我们使用了 Alesis Studio 32 混音器。此设备以内联方式安装在声卡的输出和扬声器的输入之间,允许微调音量级别。虽然混音器使测试和调整音频变得更容易一些,但它并不是真正必要的,因为相同的调整可以在软件中完成。
低成本 3-D 空间音频的软件解决方案最好用图 3 所示的分层层次结构来描述。与声卡接口所需的软件层包括低级音频驱动程序和 3-D 空间音频 API。由于可以轻松访问低级音频驱动程序的源代码,以及为从事我们此类项目的开发人员提供的总体支持社区,我们主要将开发工作集中在 Linux 上。

图 3. 音频驱动程序层
对于驱动程序层,我们选择了前面提到的 ALSA。 ALSA 为 Linux 操作系统提供音频和乐器数字接口 (MIDI) 功能。它支持多种类型的音频硬件,从消费级声卡到专业多通道音频接口。
我们选择 ALSA 是因为它看起来只需要最少的努力即可生成 3-D 空间音频所需的八个通道。在我们修改 ALSA 驱动程序以访问所有八个通道之前,它在 Audigy 2 上仅支持六个通道 (5.1)。这些更改已合并到 ALSA 中,但它们可能在发布时包含在发布版本中,也可能不包含。在这种情况下,可以获取最新的源代码并构建它——在使用 ./configure 脚本时,请务必包含 emu10k1 声卡参数,以便 ALSA 驱动程序识别 Audigy 声卡。
设置好驱动程序后,即可安装 3-D 空间声音 API。它将来自给定 3-D 位置的声音效果分配到适当的音频通道。虽然有很多 API 可供选择,但我们选择了前面提到的 Mustajuuri。 Mustajuuri 软件与 ALSA 配合使用,并使用 VBAP 算法(前面也介绍过)在任意扬声器阵列上提供 3-D 平移。 Mustajuuri API 提供了基本 3-D 位置声音系统所需的所有功能,并且相当容易扩展。在这个项目的过程中,我们进行了一些小的源代码修改,它们包含在 2004 年 10 月的发布版本中。
Mustajuuri 通过一个名为 Mixer 的模块来实现其魔力,该模块将多个声音源(声音文件、麦克风输入或其他来源)混合到单独的音频流中。然后,这些流被输送到平移模块中,该模块负责将每个输入信号路由到适当的扬声器,设置每个扬声器的正确增益和时间延迟,并将用于同一扬声器的多个流混合到要发送到该扬声器的单个流中。它根据 VBAP 进行路由和增益计算,并且一些额外的增益和延迟计算基于距离。结果是,每个传入平移模块的声音源都从一组三个扬声器发出,并且产生的声音似乎来自空间中的特定 3-D 位置。还模拟了多普勒频移。
编译并安装 Mustajuuri 后,必须执行几项任务来配置软件以使其与给定的 3-D 扬声器阵列一起工作。
ALSA 需要知道如何与声卡的所有八个通道通信。这通常只需使用名为 surround71 的设备即可实现,但它与空间声音 API Mustajuuri 不完全兼容。 Mustajuuri 需要支持输入通道。设备 surround71 支持八个输出通道,但不包含输入通道。因此,有必要定义一个具有八个输出通道和一些输入通道的新设备。
为了满足此要求,定义了一个非对称设备。该设备之所以称为非对称,是因为输入和输出通道的数量不一定相同。请注意,未明确声明输入通道的数量。 ALSA 会自动确定输入通道的数量并分配最大值;我们使用的 Audigy 声卡有两个输入通道。
要配置 ALSA,请将以下文本添加到文件 /etc/asound.conf 中,或者在必要时创建该文件。此文件包含有关用户定义设备的信息,因此我们使用以下文本添加一个名为 eightout 的非对称设备
ctl.eightout {
type hw
card 0
}
pcm.eightout {
type asym
playback.pcm {
type route
slave.pcm surround71
ttable.0.0 1
ttable.1.1 1
ttable.2.2 1
ttable.3.3 1
ttable.4.4 1
ttable.5.5 1
ttable.6.6 1
ttable.7.7 1
}
capture.pcm {
type hw
card 0
}
}
接下来,必须设置一个环境变量以允许 Mustajuuri 通过 ALSA 与声卡对话。设置以下环境变量
export MJ_AUDIO_CONF= "Input=2=hw:0,0 | Output=8=eightout"
完成此操作后,Mustajuuri 应该能够通过声卡的所有八个通道输出音频。
Mustajuuri 使用混音器风格的 GUI,用于将输入音频流发送到扬声器阵列,组合它们或只是完整地传递它们。输入流可以来自声音文件,也可以来自实时源,例如麦克风。 GUI 布置了几个通道条,这些通道条可以分配以顺序过程应用的不同功能。一些示例功能包括输入、发送(到扬声器)、幅度增益、平移和合成器。增益和平移修改了音频分配到各个输出音频通道的方式。
我们使用的混音器面板配置如图 4 所示,它使用了两个混音器条。第一个混音器条有两个有趣的通道:一个合成器通道,用于管理声音文件;一个平移模块,用于处理基于 VBAP 的跨扬声器平移。第二个混音器条用于管理来自外部应用程序的远程连接,并且不接受音频流作为输入。它向合成器和 VBAP 模块发送命令。
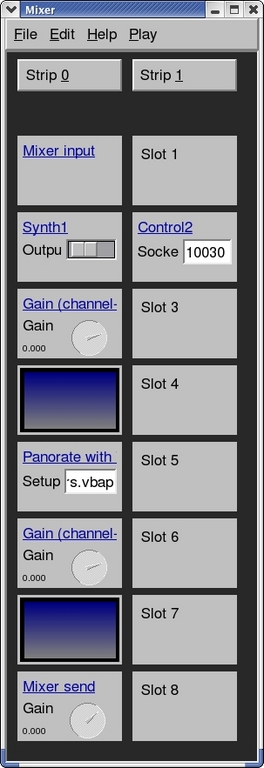
图 4. Mustajuuri 混音器 GUI 的屏幕截图(Tommi Ilmonen,Mustajuuri-2004)
要创建类似的配置,请启动 Mustajuuri 并从“文件”菜单中创建一个新的混音器。此混音器已经有几个条,所有这些条基本上都是空白的。如果需要,可以使用“编辑”菜单更改条的数量和每个条的模块数量。可以通过使用鼠标单击特定插槽来分配模块。要调整模块的属性,只需单击定义模块类型的蓝色链接,例如 Synth1 或 Mixer Input。条顶部的“Strip X”按钮可用于修改和删除该条中任何插槽中的模块。所有混音器配置更改都通过使用“文件”菜单中的保存选项来保存。生成的配置文件(例如,SpatialAudio.mj)在调用 Mustajuuri 时在命令行上指定。
为了使用 VBAP,Mustajuuri 必须知道扬声器在 3-D 阵列中的位置。 Mustajuuri 通过一个配置文件来完成此操作,该文件在 VBAP 平移模块设置中指定;此模块是在配置 Mustajuuri 混音器面板时创建的。此文件指定每个扬声器相对于听众的方位角和仰角(以度为单位)。由于我们的系统使用以立方体配置排列的八个扬声器,因此我们的配置文件指定如下
3 # dimensionality # Azimuth, followed by elevation. # 0 0 would be straight ahead. -45 45 # Front upper left 45 45 # Front upper right -135 45 # Back upper left 135 45 # Back upper right -45 -45 # Front lower left 45 -45 # Front lower right -135 -45 # Back lower left 135 -45 # Back lower right
Mustajuuri 混音器的主配置文件使用此配置文件。此文件假定所有扬声器与听众等距。如果不是这种情况,请使用 Mustajuuri 混音器手动调整每个扬声器的增益和延迟。在我们的系统中,不需要进行此类调整,如果需要进行此类调整,则需要进行大量工作。最简单的解决方案是尝试将所有扬声器放置在与理想聆听位置等距的位置。
为了从 Mustajuuri 使用声音文件,该声音文件必须在加载时为 Mustajuuri 所知。用于执行此操作的机制是一个配置文件,该文件指定 Mustajuuri 可能使用的所有声音文件。此配置文件由合成器混音器模块使用,该模块是在我们上面配置 Mustajuuri 混音器面板时创建的。以下是加载三个声音文件的示例配置文件。创建文件后,可以分配任何名称;确保合成器模块指向该文件。
unusevoices *-stk polyphony 48 sample audioeffect1.wav sample audioeffect2.wav sample sudioeffect3.wav
polyphony 行指定 Mustajuuri 应加载的最大音频文件数,因此它应至少与此文件中列出的音频文件数一样大。最后三行指定了三个示例音频 WAV 文件。此处指定的任何音频文件都必须放置在单独指定的目录中,作为合成器模块配置的一部分。 unusevoices 行是一个稍微高级的设置,但应该有助于在一定程度上提高效率。
Mustajuuri 旨在充当独立程序来操作音频,而不是充当要由另一个应用程序链接的库。要从另一个应用程序控制 Mustajuuri(就像我们的项目一样),需要执行两个步骤。第一步是设置 Mustajuuri 以侦听网络上的控制命令。第二步包括在主应用程序中编写一个简单的 API 以与 Mustajuuri 通信。
要使 Mustajuuri 接受来自网络的命令,必须加载一个网络模块。即使应用程序和 Mustajuuri 都在同一台计算机上运行,此网络模块也是外部应用程序控制 Mustajuuri 的唯一方法。添加此模块是一项简单的任务,只需配置 Mustajuuri 将侦听的端口即可;默认端口为 10030。此模块会自动与合成器模块和 VBAP 平移模块(如果在混音器中)通信。
为了从应用程序控制 Mustajuuri,有必要将 Mustajuuri API 随附的代码添加到应用程序中。我们在此处介绍示例代码段,这些代码段显示了如何连接到远程音频服务器、播放来自给定 3-D 位置的指定音频以及更改声源和听众位置的位置。
第一个代码段显示了将应用程序连接到远程 Mustajuuri 音频服务器并对其进行初始化的初始命令。如果 Mustajuuri 在另一台计算机上运行,请更改地址以反映这一点。要更改 Mustajuuri 侦听的默认端口 10030,请在地址字符串中指定新端口,例如,mjserver.mydomain.com:12345。我们创建的两个对象(AC_Control 和 AC_VrControl 各一个实例)稍后用于向 Mustajuuri 发送命令
// connecting to a remote server
#include <ac_vr_control.h>
AC_Control acControl =
new AC_Control();
char* mjServerAddress = "127.0.0.1";
if(!acControl->init(mjServerAddress))
{
// error handling code here
}
AC_VrControl acVrControl =
new AC_VrControl( acControl );
下一个代码段显示了如何指定音频源的位置并播放它。此处需要注意的一件有趣的事情是,变量 outputChannel 标识了要使用的预期声源。受支持的声源数量在“配置 Mustajuuri 混音器面板”部分中的合成器模块中指定,outputChannel 应介于 0 和源数量(减 1)之间。变量 soundFilename 不应将路径作为文件名的一部分。文件名应是在配置声音文件加载器文件时创建的配置文件中列出的文件之一。最后,soundLevel 本质上是新声音的初始增益级别。这需要进行实验才能找到合适的设置
AC_Vector3 location(
positionX,
positionY,
positionZ);
int soundId =
acVrControl->playSample(
outputChannel,
soundFilename,
soundLevel,
location,
true,
0, 0);
最后一个代码段显示了如何重新定位声源位置以及听众的方向和位置。 outputChannel 变量引用要移动的声源,并且应是用于从上一个示例中调用 playSample 的相同值。 listenerRotation 矩阵指定听众相对于世界的方向,worldRotation 矩阵指定世界相对于扬声器的方向
// reposition a source of sound
AC_Vector3 location(
positionX,
positionY,
positionZ);
acVrControl->moveSource(outputChannel,
0.05, location);
// reposition the listener orientation
AC_Matrix3 listenerRotation(
... listener rotation matrix ... );
AC_Matrix3 worldRotation(
... world rotation matrix ... );
acVrControl->setTransformations(
location, listenerRotation,
worldRotation, 0.05);
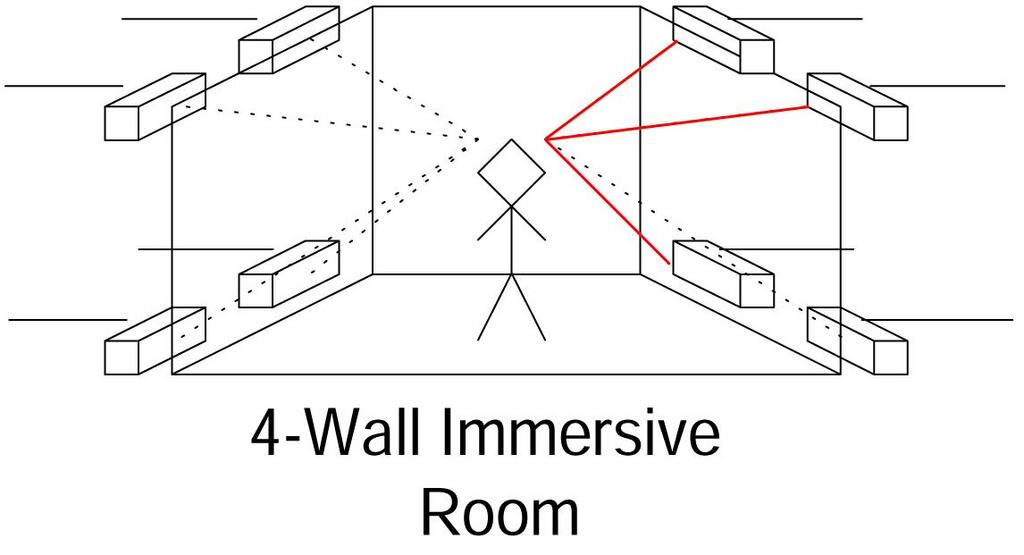
图 5. 沉浸式房间描绘,显示了立方体阵列中扬声器的放置以及来自用户前右上方向的音频;线条为红色。
我们通过将硬件与我们在华盛顿特区海军研究实验室虚拟现实实验室的四壁沉浸式虚拟现实房间集成,来测试我们的 3-D 空间音频系统的硬件设计。我们将扬声器排列成立方体阵列,并将它们放置在沉浸式房间的角落,如图 5 所示。我们将一台 1.2GHz Red Hat Linux 机器指定为音频服务器,并安装了一张 Audigy 2 ZS 声卡。我们使用之前描述的布线连接了扬声器,并尝试了带有和不带有前面提到的混音器的系统。
当 Mustajuuri 在运动中运行三个音频源时,此机器上的 CPU 利用率通常低于 20%,并且内存使用量可以忽略不计。当然,通过使用优化的编译器设置而不是我们使用的调试设置,可以实现进一步的节省。
我们测试了每个扬声器的输出,以确定可以在每个通道上播放的强度范围。我们单独聆听每个扬声器的音质、声音平衡和打击乐共振。最容易听出的是高音和低音之间的声音平衡。如果其中一个明显高于另一个,请根据需要调整相关的频率滤波器。例如,如果低音过多,请降低低音和/或增加高音。如果似乎有过度的高端或低端噪声,则可能需要添加低通滤波器或高通滤波器。
另一个容易听出的方面是扬声器失真。简而言之,如果扬声器声音太大以至于产生的声音不好,请降低扬声器的音量。如果给定的扬声器组无法以可接受的音量产生高质量的声音,则可能需要购买更强大的扬声器。
最难听出的方面之一是扬声器产生的打击乐声音的共振。这种质量基本上是声音从扬声器所在位置回响的程度。如果听起来扬声器在打击乐声音中混响,则必须进行调整。根据扬声器的质量和混音器的质量,可以通过继续过滤信号在一定程度上纠正此问题。对于非常糟糕的情况,应使用隔音材料(例如布或泡沫)覆盖坚硬的物体,例如裸露的金属、混凝土、硬塑料甚至玻璃。
校准完每个扬声器后,必须平衡整个设置。这可以通过使用旨在测量声学水平的设备来完成,也可以通过从 3-D 扬声器阵列的预定中心聆听扬声器来完成。无论哪种方式,都应调整每个扬声器的增益,直到从每个通道接收到相同的音频强度级别。请记住,声卡的每个通道的输出都由制造商针对每种类型的扬声器(卫星扬声器、中置扬声器和低音炮)的强度要求进行了自定义,这些扬声器通常以环绕声配置连接,并且每种类型的强度输出都不同。有很多已发布的方法可以解决此问题,但我们采用了低技术解决方案,让某人站在我们的扬声器阵列中心聆听。我们将软件控制设置为最大增益,并根据听众的反馈调整混音器。请记住,如果混音器不可用,则可以使用 ALSA 驱动程序和 Mustajuuri 在软件中进行这些更改。
我们通过将声音集成到现有的内部模拟平台 BARS-Utopia 中来测试该软件,该平台在 ORAD Incorporated 的 Linux 可视化集群上运行,该集群驱动我们的沉浸式房间。BARS-Utopia 支持多个虚拟世界数据库、交互方法和空间音频。但是,没有可用于与特定 Mustajuuri API 交互的支持,因此我们实现了一个插件,以将 BARS-Utopia 空间音频支持与 Mustajuuri 桥接起来。 BARS-Utopia 已经包含 Mustajuuri 所需的所有信息,例如声源位置、听众位置和方向以及声源创建/删除通知——插件只是将这些数据转换为 Mustajuuri 可以理解的形式。
插件完成后,我们测试并调试了新系统。我们进行的主要软件调整是对音频通道输出的衰减级别。 Mustajuuri 使用简单的衰减模型,需要针对预期环境(例如室外、室内、一年中的时间等)进行一些手动调整。在现实世界中,声音衰减率非常复杂,并且受温度、湿度和声音的频率组成等因素的影响。
我们通过实施几个场景来测试声音系统,每个场景都有不同的场景数据集和附加到动画对象的不同音频效果。在音频对象动画化之前,我们评估了每个对象的几个音量级别和几个距离。图 1 显示了我们设计和测试的简单场景——汽车的声音效果。当我们完成音量和距离效果的测试后,我们为汽车生成了一条动画路径以供跟随。
图 6 显示了一个更复杂的场景,其中包含三个声源:坦克、喷气式飞机和直升机——喷气式飞机在屏幕外,未在视图中显示。我们进行了一些简单的测试,以了解有多少个声源一起交互。最重要的是,通常很远的喷气式飞机听起来不太安静,而通常离相机更近的坦克和直升机不会占据听觉带宽。因此,对远近对象的衰减参数都进行了一些小的调整。

图 6. 显示了用户与包含多个声源(坦克、直升机和一架不可见的喷气式飞机)的场景进行交互。最近的扬声器是为每个声源确定的,如果重叠,则在每个扬声器处混合输出。
在完成所有测试和校准后,我们进行了两次非正式的定性用户测试,这将有助于我们验证新的低成本空间音频系统。第一个测试评估了新的八扬声器声音系统配置与我们之前的包含四个扬声器的平面配置相比如何。之前的配置仅使用了立方体阵列顶部的四个扬声器。我们意识到,由于四扬声器阵列的放置位置位于用户头部上方,因此直接比较这两种配置在某种程度上存在偏差。与位于用户高度的四扬声器阵列进行比较会更公平。但是,通过使用顶部四个扬声器,我们能够在两种配置之间切换,而无需拆卸我们的安装。
我们通过要求一些测试对象站在沉浸式房间中间并聆听为每种配置播放的声音来执行实验。我们在两种扬声器配置上播放了不同的音频序列,并充分利用了可用的全部扬声器。未告知受试者正在使用哪种配置,也未告知配置对的呈现顺序。对于每个受试者,尝试了几次配置对的迭代。在呈现每对配置后,受试者对两个系统进行了评级。诚然,这不是一项科学的测试,正如几个未解决的偏差所证明的那样,但所有测试对象都明显更喜欢八扬声器配置。
第二个用户测试评估了听众在使用八扬声器配置时能够多好地定位音频源。同样,对受试者进行了测试,并要求每个人站在沉浸式房间的中心。向每个受试者呈现了几个一次播放一个的声音,这些声音来自受试者周围的不同位置。要求受试者指向他们听到的声源方向。视觉系统未运行,因此用户没有获得有关声源位置的视觉提示。受试者能够以很高的精度定位声音,尤其是在仰角方面。
我们的 3-D 空间音频系统与我们的沉浸式房间的集成确实增强了我们拥有的模拟和培训演示。我们完成的系统显着提高了运行演示时的沉浸感。模拟用户可以轻松感知头顶飞过的直升机和喷气式飞机,以及虚拟世界中附近许多街道之一隆隆驶过的坦克。来自音频源的深度感知被准确传达,并且还包括多普勒效应。我们的系统比我们以前使用 Microsoft DirectSound API 的四扬声器解决方案更进一步。它也是我们使用另一个昂贵的硬件和软件平台运行的强大但过时且不受支持的八扬声器解决方案的良好替代品。
我们设计了一种真正的 3D 空间音频解决方案,该方案成本低廉,质量可与昂贵的高端商业系统相媲美。 3D 空间音频解决方案允许声音效果从用户周围的所有方向生成,而不仅仅是平面方向。 我们仅使用市售硬件和开源软件就实现了这一壮举。 我们认为,这项功能现在以实惠的价格提供,为游戏和虚拟现实系统开发人员创造了众多选择。
我们认为我们的系统为其他人使用当前和未来的市售音频设备设计类似的解决方案开辟了道路。 开发人员只需购买杜比环绕声 7.1 声卡、四对低成本扬声器和音频线缆即可。 我们在硬件(Audigy 2 声卡和音频线缆)上花费不到 150 美元,因为我们已经有扬声器可用。 从开始到结束,包括硬件和软件调试、配置和测试,我们花费不到一个月的时间开发了低成本 3D 空间音频系统。 我们认为,以本文档为指南,其他人应该可以在不到一周的时间内实现该系统。
未来增强功能
虽然该系统目前完全满足我们的需求,但以下功能若能添加到未来的 3D 空间声音 API 中将会更好
定向声锥:定向声锥是一种提供定向声音的机制,最强的强度沿锥体的中心轴传播,最弱的强度向边缘传播。 由于许多声源本质上是定向的,例如从扩音器发出的声音,因此定向声锥将允许更准确地生成这些声源。 此外,由于一些主要的 API(例如 Microsoft DirectSound)提供声锥,因此提供这样的功能将会很好。
额外的环境混响效果:虽然在常见的 3D 空间音频 API 中提供了许多简单的环境混响效果,但支持更复杂的效果(例如不同表面的声音反射和吸收)将大大增强听觉体验。 这是正在进行的研究领域,Mustajuuri 系统将成为尝试新技术的良好试验平台。
增强的声音衰减级别:Mustajuuri 中当前的声音距离衰减模型本质上是二次方的,因此它们相当简单。 在现实世界中,声音衰减要复杂得多,并且取决于热量、湿度、声音频率和许多其他因素。 例如,低频声音通常比高频声音传播得更远。 考虑这些复杂性可能有助于显着提供距离提示。
我们谨此感谢赫尔辛基理工大学 (HUT) 的 Tommi Ilmonen 对 Mustajuuri 所做修改的支持。 我们还要感谢 Bryan Hurley、Simon Julier、Mark Livingston、Yohan Baillot 和 Jonathan Sabo 对研究的贡献。 本研究由海军研究办公室根据合同 #N00014-04-WX-20102 赞助。
本文资源: /article/8407。
Eric Klein 是加州大学戴维斯分校数据分析和可视化虚拟现实实验室的研究生。 他正在攻读计算机科学博士学位,专攻虚拟现实。 Eric 获得了加州大学圣巴巴拉分校的学士学位,并在重返研究生院之前在工业界担任工程师多年。 他的主要研究兴趣是沉浸式音频、数据声音化、科学可视化、协作环境和人机交互。
Greg S. Schmidt 是海军研究实验室 3D 虚拟和混合环境实验室的计算机科学家。 他拥有德州农工大学计算机科学博士和 MCS 学位,以及马凯特大学生物医学工程学士学位。 他的研究兴趣包括科学和信息可视化、人机交互、增强现实、地形和医疗应用的建模与仿真以及计算机视觉。
Erik B. Tomlin 是匹兹堡大学计算机工程专业的学生。 他一直在美国海军研究实验室的 3D 虚拟和混合环境实验室从事涉及虚拟和增强现实、人机交互和科学可视化的研究项目。
Dennis G. Brown 是海军研究实验室的计算机科学家。 他获得了莱斯大学计算机科学学士学位和北卡罗来纳大学教堂山分校计算机科学硕士学位。 他从事战场增强现实系统 (BARS) 和多模式虚拟现实项目。 他的研究兴趣包括增强现实和虚拟现实,特别是新型用户界面和数据分发。
