
创建 Planet Me 博客聚合器
Planet 项目允许在线社区轻松构建中心网页,聚合来自社区成员的博客。Planet 代码驱动了诸如 Planet GNOME 和 Planet Apache 等社区博客。Planet 代码的这些在线应用为人们关注社区提供了低成本的入口。本文重点介绍如何在本地机器上使用 Planet 代码创建您自己的自定义博客聚合器。
Planet 代码需要 Python 2.2 或更高版本。安装 Planet 最简单的方法是从 planetplanet.org 网站下载每夜快照 tarball,并将其解压到您的主目录。我倾向于重命名解压后的 planet-nightly 目录,以包含其下载日期,并使用一个方便的链接指向 Planet Me 的当前版本。
在本文中,我多次引用了我的主目录路径;请记住在示例中替换为您自己的主目录。
清单 1. 安装 Planet
$ cd ~ $ tar xjvf planet-nightly.tar.bz2 $ planetdated=planet-$(date +'%d%b%y') $ mv planet-nightly $planetdated; $ ln -s $planetdated planet $ cd planet $ cp -av fancy-examples me-meta $ cd me-meta $ cp ../examples/*.xml* . $ edit config.ini name = Planet Me link = file://home/ben/planet/me/index.html owner_name = John Doe owner_email = root@localhost # later in the file # template_files should all be on one line template_files = me-meta/index.html.tmpl me-meta/rss20.xml.tmpl me-meta/rss10.xml.tmpl me-meta/opml.xml.tmpl me-meta/foafroll.xml.tmpl # later in the file change # fancy-examples/index.html.tmpl [me-meta/index.html.tmpl] items_per_page = 30 $ cd .. $ mkdir cache $ ln -s output me # Without proxy $ python planet.py me-meta/config.ini # Using a standard squid proxy on "dairiserver" $ http_proxy=http://dairiserver:3128/ \ python planet.py me-meta/config.ini
清单 1 中的最后两个命令展示了如何获取最新的新闻源并设置您的初始 Planet。这些命令会因各种因素而异,例如您是否必须使用代理服务器才能访问互联网。运行这些命令后,您应该可以在 Web 浏览器中查看位于 ~/planet/me/index.html 的 Planet Me。完成这些步骤后,您的 planet 应该看起来类似于图 1。
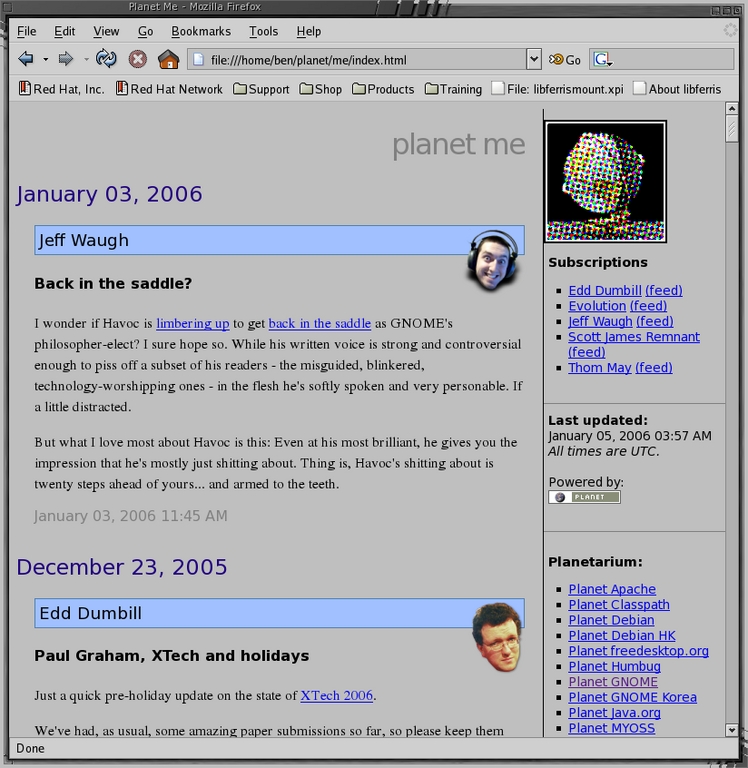
图 1. 一个新的正在运行的 Planet 安装
您需要自定义您正在查看的新闻源。这在 me-meta/config.ini 的末尾完成。配置文件通过方括号括起来的文本定义一个节。节的选项在其初始定义之后以键=值对的形式出现。您在节中定义要聚合的每个博客,在其中指定 RSS 源的 URL 作为节名称。请参阅清单 2,了解默认 config.ini 文件中的示例。
名称将显示在来自该博客的每个聚合帖子的标题中,并且在使用默认 HTML 模板时,人脸图像将位于右侧。默认情况下,facewidth 和 faceheight 是可选的。
清单 2. 示例聚合定义
[https://gnome.org.cn/~jdub/blog/?flav=rss] name = Jeff Waugh face = jdub.png facewidth = 70 faceheight = 74
许多网站提供方便的主题图标,可以用来美化您的 Planet Me。例如,在清单 3 中,我使用了 Slashdot 部分图标之一(请参阅在线资源)来表示从 Slashdot 的 RSS 源获取的新闻项目。
假设您按照本文所述使用 Planet 设置,主题图标存储在 ~/planet/me/images 中。您可以在清单 3 中看到我的 Slashdot 主题图标的设置。
清单 3. 如何从 Slashdot 获取图像
$ cd ~/planet/me/images/ $ wget \ http://images.slashdot.org/topics/topicslashback.gif # convert is from ImageMagick $ convert topicslashback.gif slashdot.png
清单 4 显示了要附加到 config.ini 的新节,以将 Slashdot 图标集成到您的 Planet Me 中。
清单 4. 创建一个定义以使用 Slashdot 图标
$ edit ~/planet/me-meta/config.ini [http://rss.slashdot.org/Slashdot/slashdot] name = Slashdot face = slashdot.png $ cd ~/planet $ python planet.py me-meta/config.ini
清单 5. 设置 cron 作业以聚合博客
$ mkdir -p ~/mycron $ cd ~/mycron $ vi upd-planet.sh #!/bin/sh cd ~/planet; http_proxy=http://dairiserver:3128/ \ python planet.py me-meta/config.ini $ chmod +x upd-planet.sh $ echo \ '00 04 * * * /home/ben/mycron/upd-planet.sh' \ >|upd-planet.cron # only if you already use cron from outside ~/mycron $ crontab -l >|oldcrontab.cron $ cat *.cron >|newtab $ crontab newtab $ rm -f oldcrontab.cron
如果您保留博客定义文件列表而不是尝试手动管理配置文件本身,则可以轻松添加和删除博客。您可以使用清单 6 中显示的 generate-config 脚本将博客名称和 URL 移动到博客子目录中的非常简单的文件中。
您可以使用文件管理器或命令行来添加或删除文件,这些文件确定您的聚合方案的配置。这也为简单的 Firefox 扩展铺平了道路,允许从上下文菜单将新的 RSS 源添加到 Planet Me。通过将博客信息移出 config.ini,稍后显示的存档处理也得到了简化。
清单 6. 生成文件以定义要聚合的博客。
$ cd ~/planet/me-meta $ mv config.ini config.ini.template $ edit config.ini.template # remove all blog URL sections from the bottom of file # search for http: to find the first one $ mkdir blogs $ echo http://rss.slashdot.org/Slashdot/slashdot \ >blogs/slashdot.blog $ ./generate-config
清单 7. 使用文件创建博客聚合配置。
#!/bin/sh cp -av config.ini.template config.ini for if in blogs/*.blog do base=$(basename $if .blog); content=$(cat $if); echo "" >> config.ini echo "[$content]" >> config.ini echo "name = $base" >> config.ini echo "face = $base.png" >> config.ini done
控制您的 planet 外观的两个文件是 me-meta/index.html.tmpl(它是页面内容的模板)和 me/planet.css(它是层叠样式表)。
默认情况下,face、entry、date 和 sidebar 都定义了可以使用样式表更改的样式。您可以通过修改 font-family CSS 标签来使用自定义字体。
index.html.tmpl 模板具有 Planet 代码用于生成最终 index.html 文件的额外标签。感兴趣的主要标签是 TMPL_LOOP、TMPL_IF 和 TMPL_VAR。新闻源使用 <TMPL_LOOP Items> 类似 HTML 的标签及其对应的闭合标签放置到输出页面中。这两个标签之间的 HTML 元素将为要显示的每个新闻项目输出一次。这些元素定义了为每个新闻项目生成什么以及如何生成输出。
Planet 代码使用这些变量来访问新闻源内容。例如,它将 <TMPL_VAR title> 标签替换为当前新闻项目的实际标题。请注意,TMPL_VAR 没有对应的闭合标签。
TMPL_IF 标签用于检查信息是否存在或设置特定条件。例如,有时新闻项目没有标题信息。清单 8 中的代码将在标题信息存在时输出标题信息,如果标题不存在则不输出任何内容。TMPL_VAR 标签上的 escape 属性告诉 Planet 确保 link 变量的值采用合法 HTML 属性的形式。
清单 8. 使用 TMPL_IF 标签为您的输出设置条件。
<TMPL_IF title> <a href="<TMPL_VAR link ESCAPE="HTML">"> <TMPL_VAR title> </a> </TMPL_IF>
您必须编辑 me-meta/index.html.tmpl 和 CSS 文件,才能将频道图标移动到 Planet Me 新闻项目的左侧。
默认情况下,您的 index.html.tmpl 仅当当前新闻项目与前一个新闻项目来自不同的频道时才会显示频道图标。
我从清单 9 中显示的 index.html.tmpl 片段中删除了围绕人脸图像信息输出的 <TMPL_IF new_channel> 标签。我还为频道图像使用了 news-item-icon CSS 类,为主要新闻帖子部分使用了 news-item 类,为实际频道图像使用了新的 embedded-face 类。
清单 9. ~/planet/me-meta/index.html.tmp 的新频道项目节
<TMPL_LOOP Items>
<TMPL_IF new_date>
<h2><TMPL_VAR new_date></h2>
</TMPL_IF>
<div class="news-item-icon">
<a href="<TMPL_VAR channel_link ESCAPE="HTML">"
title="<TMPL_VAR channel_title ESCAPE="HTML">">
<TMPL_VAR channel_name>
<br/>
<img class="embedded-face" alt=""
src="images/<TMPL_VAR channel_face ESCAPE="HTML">" >
</a>
</div>
<div class="news-item">
<TMPL_IF title>
<h4><a href="<TMPL_VAR link ESCAPE="HTML">">
<TMPL_VAR title></a></h4>
</TMPL_IF>
<div class="entry">
<p>
<TMPL_VAR content>
</p>
<p class="date">
<a href="<TMPL_VAR link ESCAPE="HTML">">
<TMPL_IF creator>by <TMPL_VAR creator> at </TMPL_IF>
<TMPL_VAR date></a>
</p>
</div>
</div>
</TMPL_LOOP>
清单 10 中显示的是新的样式表代码,用于将频道图像设置在新闻项目的左侧。您的 Planet Me 现在应该如图 2 所示。如果您希望频道图标位于新闻项目的右侧,请更改样式表,使 news-item-icon 的 float 标签为 right,news-item 的 margin-left 为 0px。
清单 10. 要添加到 ~/planet/me/planet.css 的新样式
div.news-item-icon {
float: left;
position: relative;
left: 4px;
margin-top: 25px;
padding: 0 20px 30px 0;
width: 120px;
text-align: center;
}
div.news-item-icon a {
text-decoration: none;
}
div.news-item {
margin-left: 140px;
}
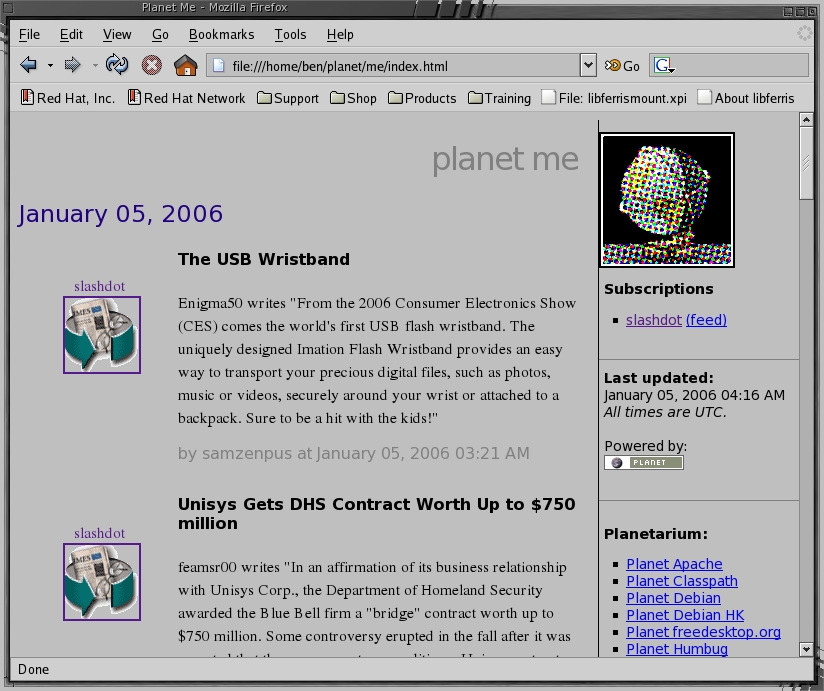
图 2. 我的示例 Planet 站点,带有自定义模板和 CSS 文件
频道定义文件中使用的 face=whatever.png 行对于 Planet 来说并非特殊。您可以根据每个频道定义您想要的任何其他变量,它们将在您的 index.html.tmpl 中可用。例如,清单 11 显示了可选变量 foo 的使用,该变量可能在您的 config.ini 文件中的频道描述之后被定义为 foo=bar。
清单 11. 使用 TMPL_IF 的另一种方式
<TMPL_IF channel_foo> Have foo:<TMPL_VAR channel_foo ESCAPE="HTML"> </TMPL_IF>
学习如何自定义您的 Planet Me 的另一种好方法是访问其他 Planet 网站。检查他们的 HTML 和 CSS 文件,了解他们如何修改外观。
Planet 代码旨在聚合来自多个来源的新闻源,并在单个页面上提供它们的近期历史记录。对于 Planet Me 的本地使用,能够查看过去任意时间段的新闻源是很不错的。
您的 Planet Me 将创建一个有效的 RSS RDF 新闻源,您可以使用它来存档您的 Planet。RDF 文件中的所有内容都围绕三元组展开。三元组的三个部分被称为主体、谓词和对象。一个示例三元组可能说明新闻项目具有给定的发布日期,例如,item57 具有日期 2006 年 1 月 3 日。RSS 新闻源定义了一个新闻频道,将该频道与新闻项目列表关联,并为每个新闻项目定义了有趣的属性,例如其标题、发布日期和文本内容。通常,像 has-date 这样的东西是使用长 URI 定义的,以避免两个三元组意外地具有相同的字面值。
一种简单而强大的存档 Planet 的 RSS 的方法是使用 Jena Project。一旦您安装了 Java 虚拟机,您需要安装 Jena 的只是下载一个 tarball,解压它并将其添加到您的 classpath 中。
清单 12 显示了新闻源的安装步骤和可重复的存档过程。如果您长期收集大量源,您可以将您的新闻源存档放入使用 Jena 的数据库中。
清单 12. 如何在重复的基础上存档新闻源
$ cd ~
$ unzip Jena-2.3.zip
$ edit ~/.bashrc
# append a handy classpath setup
JenaSetup() {
for if in ~/Jena-2.3/lib/*.jar; do
export CLASSPATH=$CLASSPATH:$if;
done
}
$ . ~/.bashrc
$ JenaSetup
# archive news feed
# repeatable three step
$ cd ~/planet/me
$ mv -f archive.xml rss10-archive.xml
$ java jena.rdfcat rss10*xml >archive.xml
Jena 使您能够对您的存档使用非常强大的查询来重新创建您的 Planet。
清单 13 显示了新闻源的简单时间间隔查询。此查询使用 SPARQL 查询语言,该语言用于查询 RDF 存储库。查询的核心链接了频道、新闻项目和日期组件,然后在应用过滤器,根据附加到该新闻项目的日期来确定要返回哪些新闻项目。
清单 13. 使用 Jena 查询您的 Planet Me 站点。
$ cat rss-by-date.sparql
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
DESCRIBE ?channel ?bnode ?a WHERE
{
?channel ?items ?bnode .
?bnode ?hasitem ?a .
?a dc:date ?date .
FILTER ( xsd:dateTime(?date)
>= xsd:dateTime("2006-01-03T00:00:00")
&& xsd:dateTime(?date)
<= xsd:dateTime("2006-01-05T00:00:00") )
}
$ cd ~/planet/me
$ java jena.sparql --data archive.xml \
--query rss-by-date.sparql --results RDF/XML \
>my-query-result.rss
我们现在可以轻松地更改 Planet Me 以仅使用您的查询结果作为输入,如清单 14 所示,因为我们已将博客 URL 和元数据移动到单独的文件中,如上所述。
清单 14. 使用 Jena 查询结果来修改您的 Planet Me 聚合。
$ cd ~/planet/me-meta $ cp -av config.ini.template config.ini $ echo \ "[file:///home/ben/planet/me/my-query-result.rss]" \ >>config.ini $ echo "name = archive" >>config.ini $ cd ~/planet $ rm -f cache/file.home* $ python planet.py me-meta/config.ini
使用上述查询,频道图标将全部相同,因为您正在查询单个新闻源,即您自己的新闻源。可以在 FILTER 部分中使用的另一个表达式是 regex()。清单 15 中显示的示例过滤所有新闻项目,并且仅显示与不区分大小写的正则表达式匹配的项目。
清单 15. 您可以使用正则表达式作为过滤器。
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX rss: <http://purl.org/rss/1.0/>
PREFIX content: <http://purl.org/rss/1.0/modules/content/>
DESCRIBE ?channel ?bnode ?a WHERE
{
?channel ?items ?bnode .
?bnode ?hasitem ?a .
?a content:encoded ?content .
FILTER ( regex(?content, ".*product.*", "i") )
}
Planet Me 旨在用于在线社区博客聚合,但 Planet 代码可以为个人使用提供非常有效的博客聚合器。Planet 代码旨在创建由大量人查看的在线博客聚合。通过一些调整,Planet 代码可以成为非常有效的个人博客聚合器,让您可以自由地明确选择谁在您的社区中,并轻松创建 Planet 存档,并使用非常强大的查询语言搜索过去的新闻。
本文的资源: /article/8830。
Ben Martin 大部分时间都在研究虚拟文件系统和在它们之上进行数据挖掘。最近的乐趣包括扩展 libferris 以允许将 Emacs 和 Firefox 挂载为文件系统。
